深層学習 Day1
本記事はラビット☆チャレンジのレポートとして記載し、今回は以下の内容について記述する。
Section1:入力層~中間層
Section2:活性化関数
Section3:出力層
Section4:勾配降下法
Section5:誤差逆伝播法
動画の要約
Section1:入力層~中間層
- 入力層のそれぞれの値に対して、重みの線形結合した値が第一の中間層の入力となる。
- 活性化関数を用いた結果が出力となり、次の層の入力となる。
Section2:活性化関数
1) 活性化関数とは
- ニューラルネットワークにおいて、次の層への出力を決定する非線形の関数もしくは恒等関数。
- 入力値の値によって、次の層への信号のON/OFFや強弱を定める働きをもつ。
2) 中間層の活性化関数
活性化関数として以下の3つがあげられる。※ステップ関数は実用で用いられるケースはない。
- RELU関数
- シグモイド関数(ロジスティック関数)
- ステップ関数
3) 出力層の活性化関数
出力層の活性化関数として利用されるのは以下の3つがあげられる。
- ソフトマックス関数
- 恒等写像
- シグモイド関数(ロジスティック関数)
4) 中間層の活性化関数の特徴
- シグモイド関数
- ステップ関数ではON/OFFしかないがシグモイド関数では0 ~ 1の間を緩やかに変化する
- 信号の強弱を伝えることができる
- 絶対値の大きな値では微分係数が微小なため、勾配消失問題を起こしやすい
- RELU関数
- 今最も使われている関数
- 勾配消失問題の回避とスパース化に貢献することで良い成果を上げている
Section3:出力層
1) 誤差関数
- 回帰:二乗誤差(MSE)を用いる
- 分類:交差エントロピー関数を用いる
2)出力層の活性化関数
中間層と出力層とでは活性化関数を利用する目的が異なるため、中間層と同一の関数を用いる必要はない
- 出力層が回帰の場合
- 活性化関数:恒等写像
- 誤差関数:二乗誤差
- 出力層が二値分類の場合
- 活性化関数:シグモイド関数
- 誤差関数:交差エントロピー
- 出力層が多クラス分類の場合
- 活性化関数:ソフトマックス関数
- 誤差関数:交差エントロピー
Section4:勾配降下法
最適なパラメータをするために勾配降下法を用いる。主な手法として以下の3つがある。
- 勾配降下法
- パラメータの更新に全サンプルの平均誤差を使用
- 計算量が多い
- 確率的勾配降下法
- パラメータの更新にランダムに抽出したサンプルの誤差を使用
- 計算コストの削減
- 局所極小解に収束するリスクの軽減
- オンライン学習がて可能
- ミニバッチ勾配降下法
- ミニバッチ( ランダムに分割したデータの集合)に属するサンプルの集合平均誤差を使用
- 確率的勾配降下法のメリットを損なわず高速な処理が可能
Section5:誤差逆伝播法
- 算出された誤差を、出力層側から順に微分し、前の層前の層へと伝播する手法
- 最小限の計算で各パラメータでの微分値を解析的に計算する手法
- 誤差から微分を逆算することで、不要な再帰的計算を避けて微分を算出できる
確認テスト
P10 ディープラーニングは、結局何をやろうとしているか2行以内で述べよ。 また、次の中のどの値の最適化が最終目的か。 全て選べ。
1:入力値[ X] 2:出力値[ Y] 3:重み[W] 4:バイアス[b] 5:総入力[u] 6:中間層入力[z] 7:学習率[ρ]
- ディープラーニングは誤差を最小化するネットワークを作成すること
- 3,4の最適化をすることで誤差を最小化する
P12 入力層:2ノード1層 中間層:3ノード2層 出力層:1ノード1層 のネットワークを書け
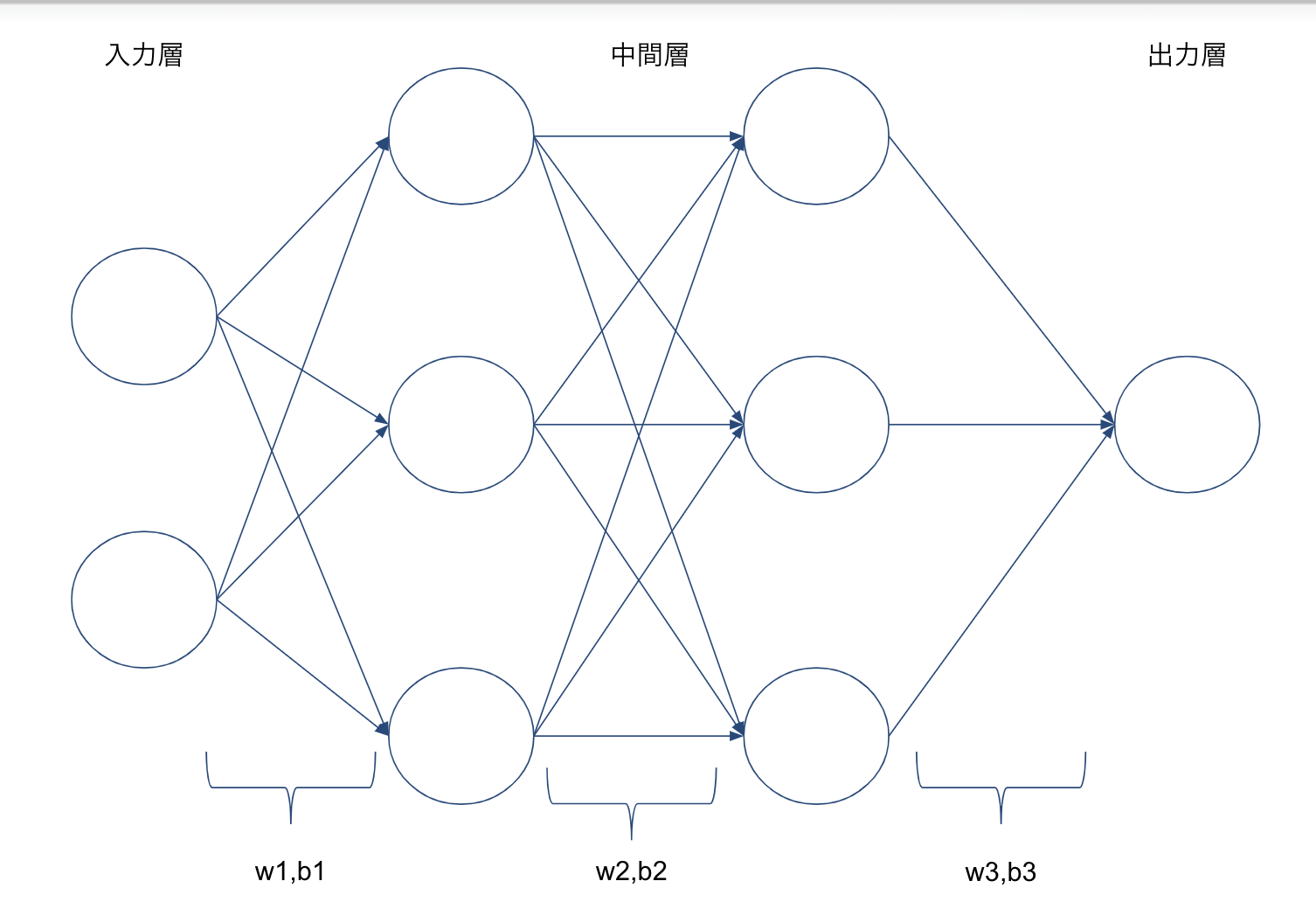
P19 下の図の入力に動物分類の例を書け
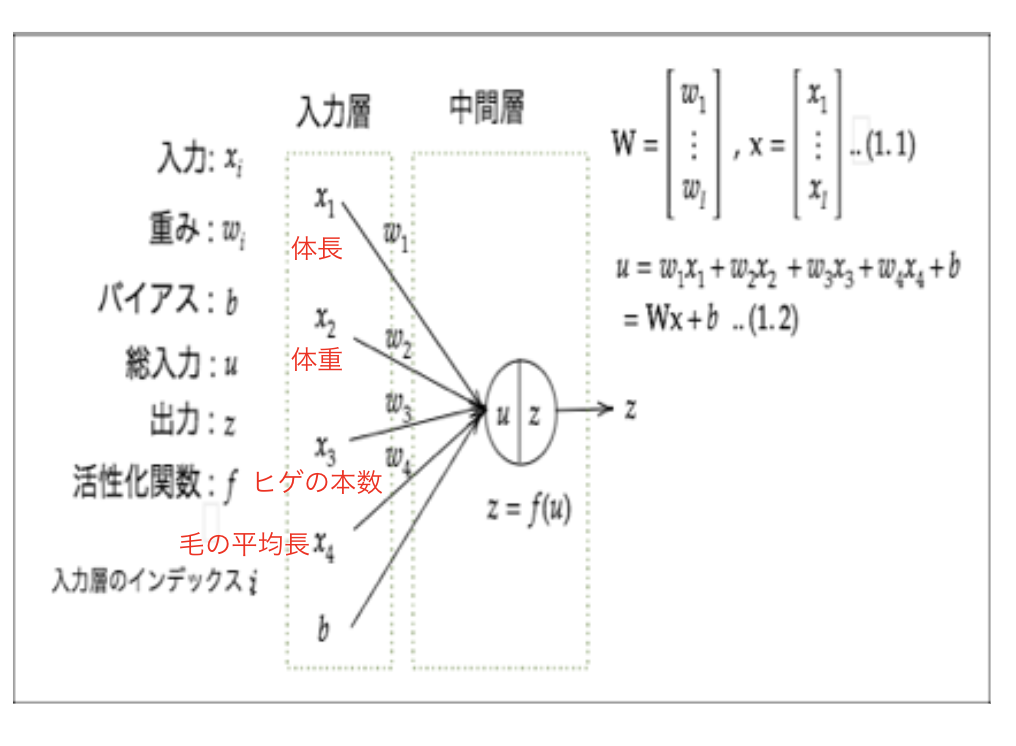
P21 上記の図の重みと入力の内積およびバイアスの加算式をPythonのコードで書け
u = np.dot(W,x) + b
P23 中間層の出力を定義しているソースを抜き出せ
z = functions.relu(u)
P26 線形と非線形について図に書いて簡単に説明せよ。
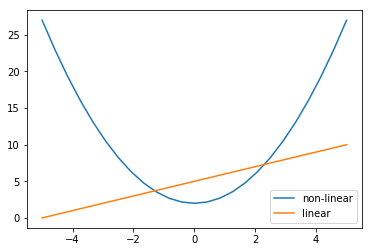
線形とは下記の性質が満たされることである。
- $f(x+y) = f(x) + f(y)$
- $f(ax) = a f(x)$
上記性質を満たさないものを非線形という
P33 配布されたソースコードより該当する箇所を抜き出せ。
z1 = functions.sigmoid(u)
P44 誤差関数の計算において
- なぜ、引き算でなく二乗するか述べよ
- 下式の1/2はどういう意味を持つか述べよ
E_n(w) = \frac{1}{2}\sum_{j=1}^J(y_j - d_j)^2 = \frac{1}{2}||(y-d)||^2
- 二乗することで絶対値を考慮せず微分が可能になるため
- 微分を行うことで後続の計算が簡単になるため1/2をしている
P51 ソフトマックス関数において、下の図の1〜3のコードを示し意味を答えよ。

def softmax(x):
1:の説明
xがuに相当する。配列なので全要素についてf(u) を返す関数となる。
np.exp(x)
2:の説明
配列の全要素について指数関数の値を計算している。
np.sum(np.exp(x), axis=0)
3:の説明
配列の全要素について指数関数の値を総和で割っている。
P53 交差エントロピーにおいて、下の図の1〜2のコードを示し意味を答えよ。

def cross_entropy_error(d, y):
1:の説明
引数dは教師データのエントロピー ( one-hot-vector 形式でも可 )。yはNNの出力となる。
return -np.sum(np.log(y[np.arange(batch_size), d] + 1e-7))
2:の説明
log内の積がlogの和になる性質を利用している。また、0にならないように微小な値を加算している。
P56 下記の数式に該当するコードを書け。
w^{t+1} = w^{t} - \varepsilon \nabla E
network[key] -= learning_rate * grad[key]
P65 オンライン学習とは何か2行でまとめよ。
- 学習データが入ってくるたびにその都度、新たに入ってきたデータのみを使って学習を行う
- 今あるモデルのパラメータを随時更新していく
P68 記の数式の意味を図示して説明せよ。
w^{t+1} = w^{t} - \varepsilon \nabla E_t
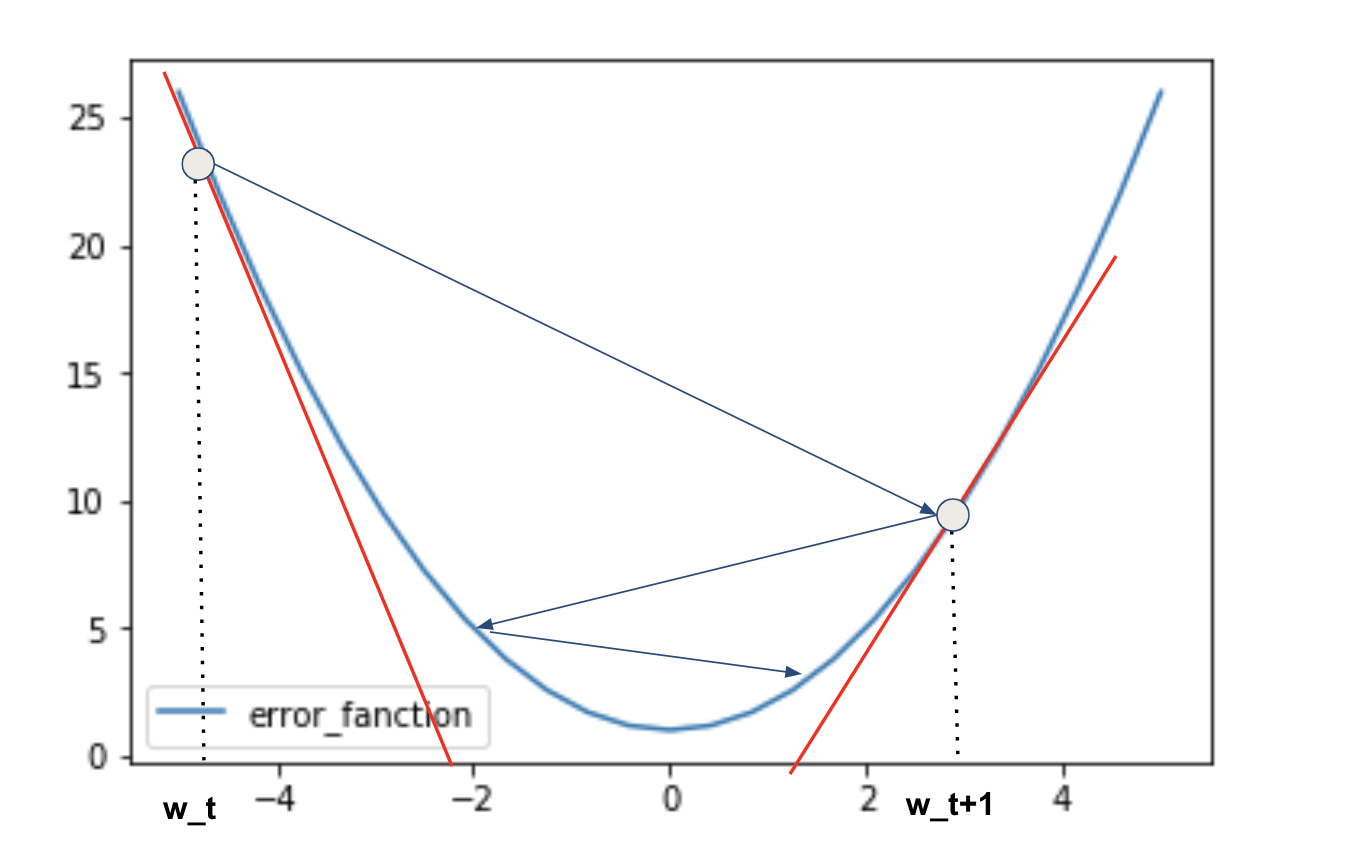
t+1時点のパラメータは、t時点の誤差関数Eの傾きと学習率を掛けたものを引いて求める。
P78 誤差逆伝播法では不要な再帰的処理を避ける事が出来る。計算結果を保持しているソースコードを抽出せよ。
def backward(x, d, z1, y):
print("\n##### 誤差逆伝播開始 #####")
grad = {}
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 出力層でのデルタ
delta2 = functions.d_sigmoid_with_loss(d, y)
# b2の勾配
grad['b2'] = np.sum(delta2, axis=0)
# W2の勾配
grad['W2'] = np.dot(z1.T, delta2)
# 中間層でのデルタ
delta1 = np.dot(delta2, W2.T) * functions.d_relu(z1)
P83 2つの空欄を埋めるソースコードを書け

bの勾配
grad['b2'] = np.sum(delta2, axis=0)
wの勾配
grad['W2'] = np.dot(z1.T, delta2)
演習問題
forward_propagation.ipynbをもとに編集し実行した。
# 2値分類
# 2-3-1ネットワーク
# !試してみよう_ノードの構成を 5-10-1 に変更してみよう
# ウェイトとバイアスを設定
# ネートワークを作成
def init_network():
print("##### ネットワークの初期化 #####")
network = {}
network['W1'] = np.array([
[0.1, 0.3, 0.5,0.7,0.9,1.1,1.3,1.5,1.7,1.9],
[0.1, 0.3, 0.5,0.7,0.7,1.7,1.3,1.5,1.7,1.9],
[0.1, 0.3, 0.5,1.1,1.1,1.1,1.3,1.5,1.7,1.9],
[0.1, 0.3, 0.5,0.7,0.9,1.9,1.3,1.5,1.7,1.9],
[0.1, 0.3, 0.5,0.7,0.9,1.7,1.7,1.5,1.7,1.9]
])
network['W2'] = np.array([
[0.1],
[0.2],
[0.3],
[0.4],
[0.5],
[0.6],
[0.7],
[0.8],
[0.9],
[1.0]
])
network['b1'] = np.array([0.1, 0.2, 0.3,0.4,0.5,0.6,0.7,0.8,0.9,1.0])
network['b2'] = np.array([0.1])
return network
# プロセスを作成
def forward(network, x):
print("##### 順伝播開始 #####")
W1, W2 = network['W1'], network['W2']
b1, b2 = network['b1'], network['b2']
# 隠れ層の総入力
u1 = np.dot(x, W1) + b1
# 隠れ層の総出力
z1 = functions.relu(u1)
# 出力層の総入力
u2 = np.dot(z1, W2) + b2
# 出力層の総出力
y = functions.sigmoid(u2)
print_vec("総入力1", u1)
print_vec("中間層出力1", z1)
print_vec("総入力2", u2)
print_vec("出力1", y)
print("出力合計: " + str(np.sum(z1)))
return y, z1
# 入力値
x = np.array([1., 2.,3.,4.,5.])
# 目標出力
d = np.array([1])
network = init_network()
y, z1 = forward(network, x)
# 誤差
loss = functions.cross_entropy_error(d, y)
## 表示
print("\n##### 結果表示 #####")
print_vec("中間層出力", z1)
print_vec("出力", y)
print_vec("訓練データ", d)
print_vec("誤差", loss)
その他のコードも同様にノードを変更し実行した。
考察
- 重みの初期値を変えることで学習に大きな影響を与えていることを理解した
- ニューラルネットのノードの変更が容易であることが実装して理解できた
- 順伝播の仕組みを実行することで理解できた
stochastic_gradient_descent.ipynbをもとに編集し実行した。
<変更点>
- 中間層の活性化関数をReLUもしくはシグモイド関数で実装
考察
- 活性化関数を何を用いるかで収束するかしないか理解できた
- 入力値でも収束するかしないかの影響を与えていることが理解できた