概要
2019年1~6月までの期間で出演数の多い声優さんをR言語でピックアップしてみました。
「ヒャア!プログラミングなんて興味ねえ!俺は結果だけ見てえんだよォ!」という方におかれましては基本ルールをさっとお読みの上、「出演数が多い声優ベスト100」、「可視化」のリンクに飛んでいただければ良いかなと。
基本ルール
・作品データベースからデータを抽出
・ジャンルは「アニメ」に限る
・期間は2019年1月~6月まで
データクレンジングの難点
大量のデータを取得する、ということはやってみると非常に難しいものでした。
データが思うように取れなかったり、声優に紐づく出演作品のデータが一件も登録されていなかったり。
以下、つまづいた点を挙げてみたいと思います。
データの欠落
データは登録されているものの、出演作品が一つも登録されていない声優さんが散見されました。
そのことでフォーマット揺れが発生し、対策する必要がありました。
有志の善意で登録されているということで、正確さには欠けるデータをクレンジングする際は注意が必要だということ。
出演作品の登録漏れ
出演作品は登録されているものの、今年の出演作品について登録が行われていない、もしくは承認待ちのステータスになっており、Webに反映されていない状態が結構見受けられました。

たとえば声優のゆかなさん(画像は公式ブログから引用)ですが、有名なアニメ映画である『コードギアス』のC.C.役や『プリキュア』の雪城ほのか/キュアホワイト役を演じられていますが、今年の分が反映されていません。
一件ずつチェックして出演作品を加味していくのは現実的ではないので諦めるしかなかったです。
HTTP502エラー/タイムアウトエラー
扱うデータが述べ10万件にもおよび、データを取得・処理する過程で「HTTP502」のBad GateWayエラー、タイムアウトエラーが頻発しました。
PCのスペックはメモリが8GBと結構いいスペックだと思うのですが、容量の大きいデータの処理に適したマシンスペックでは決してありません。
PCへの負荷を意識してコーディングする必要がありました。
実装ソースコード
では、実装したソースコードを展開します。
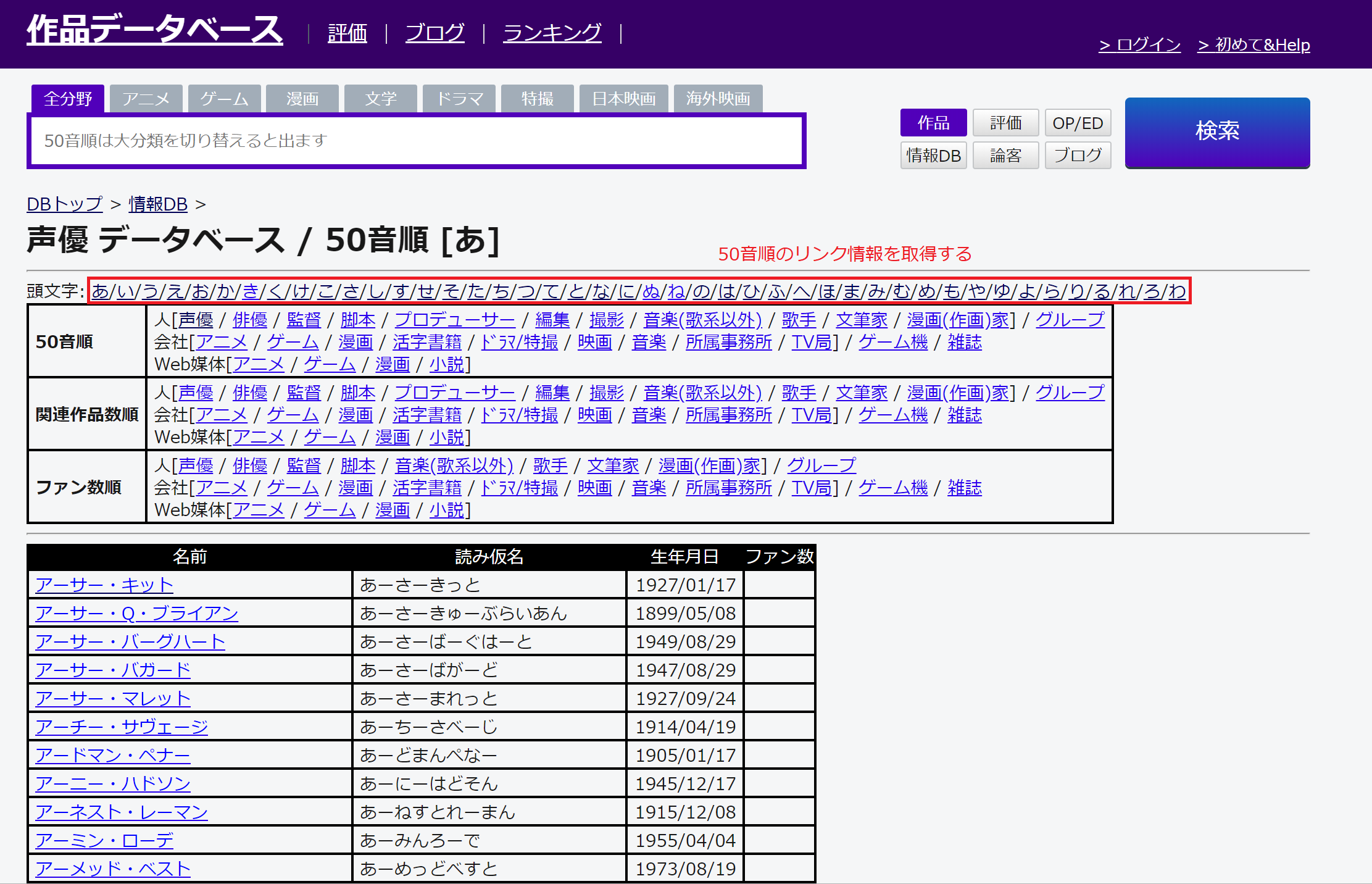
ページの先頭部に50音順にリンクが並んでいるのですが、全ての声優情報を網羅するためにリンク先のURL情報を取得します。
# ライブラリ -------------------------------------------------------------------
pacman::p_load(tidyverse,pipeR,rvest,DataExplorer)
# 集約処理 --------------------------------------------------------------------
#読み込み対象のページURL
url_txt <- "https://sakuhindb.com/anime/alph_info/j/people_voice_a.html"
#ページの読み込み
data <- read_html(url_txt)
#50順のurl情報を取得
sound_order <-data %>>%
#ノード情報を取得
html_nodes(xpath = "//div[@class = 'article container'] //a") %>>%
#属性情報を取得
html_attr("href") %>>%
#データフレーム化
as.data.frame() %>>%
#50音順のURLだけ取得できるようフィルタする
filter(grepl("/anime/alph_info/j/people_voice_",.)) %>>%
filter(!grepl("//sakuhindb.com/",.))
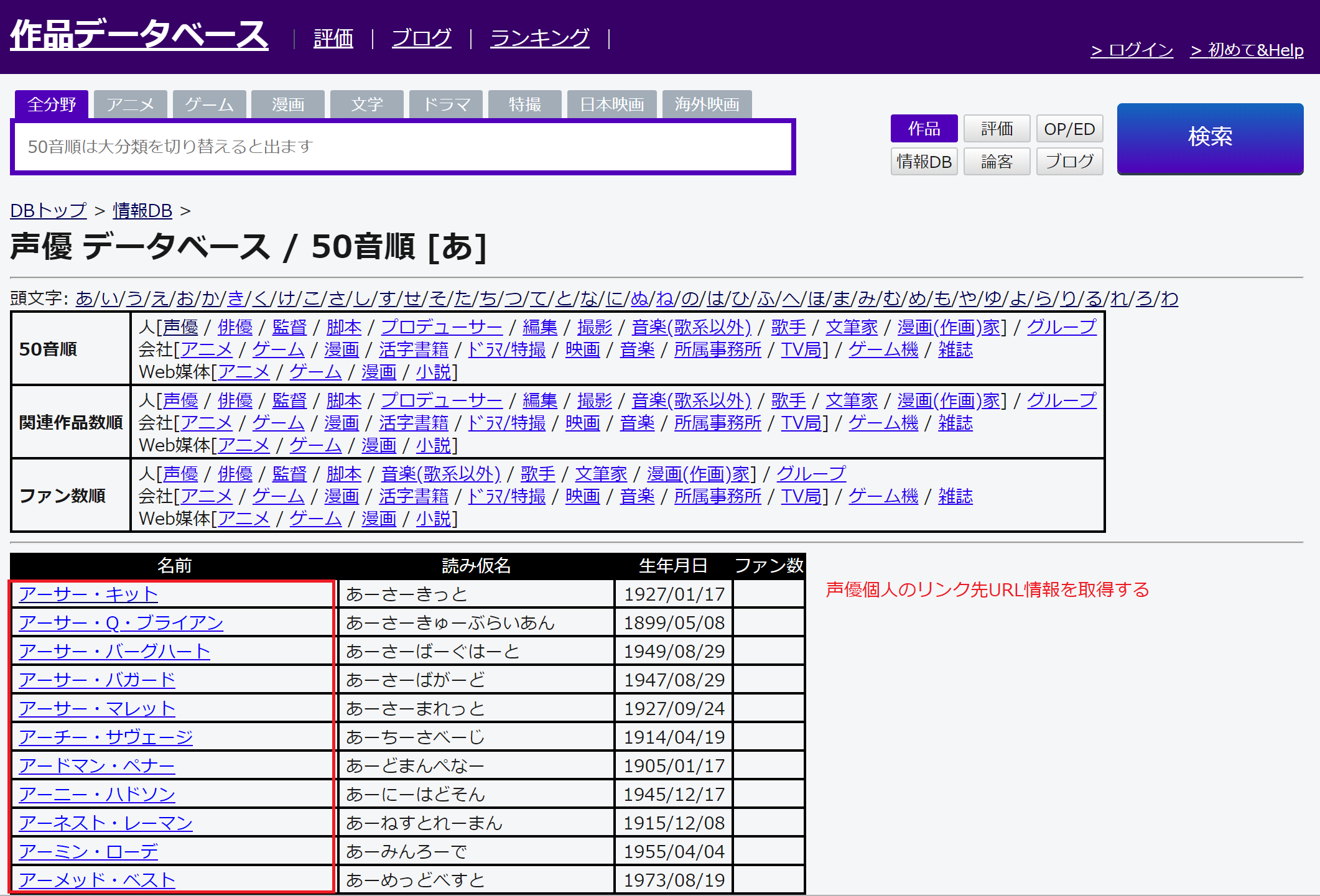
次に50音順に一覧ページが表示された上で声優個人のリンク先URL情報を取得します。
#集約用データフレーム
df_all <- data_frame()
#繰り返し処理 声優の「名前」、声優の「リンク先URL情報」を取得
for (i in 1:nrow(sound_order)) {
url_sound_order <- sound_order$.[i]
data2 <- read_html(paste0("https://sakuhindb.com/",url_sound_order))
#声優の名前
voice_actor_name <-data2 %>>%
#ノード情報を取得
html_nodes(xpath = "//table[@class = 'table']") %>>%
#テーブル情報を取得
html_table() %>>%
#2番目のリスト情報に声優の名前一覧が入っている
'[['(2) %>>%
#名前の列だけ取得
select(名前)
#声優のリンク先URL情報
voice_actor_link <- data2 %>>%
#ノード情報を取得
html_nodes(xpath = "//table[@class = 'table'] //tr //td //a") %>>%
#属性情報を取得
html_attr("href") %>>%
#データフレーム化
as.data.frame() %>>%
#声優のリンク先URL情報だけ取得できるようフィルタする
filter(grepl("/tj/", .))
#「声優の名前」と声優の「リンク先URL情報」を結合する
df <- bind_cols(voice_actor_name,voice_actor_link)
df_all <- merge(df_all,df,all = T)
}
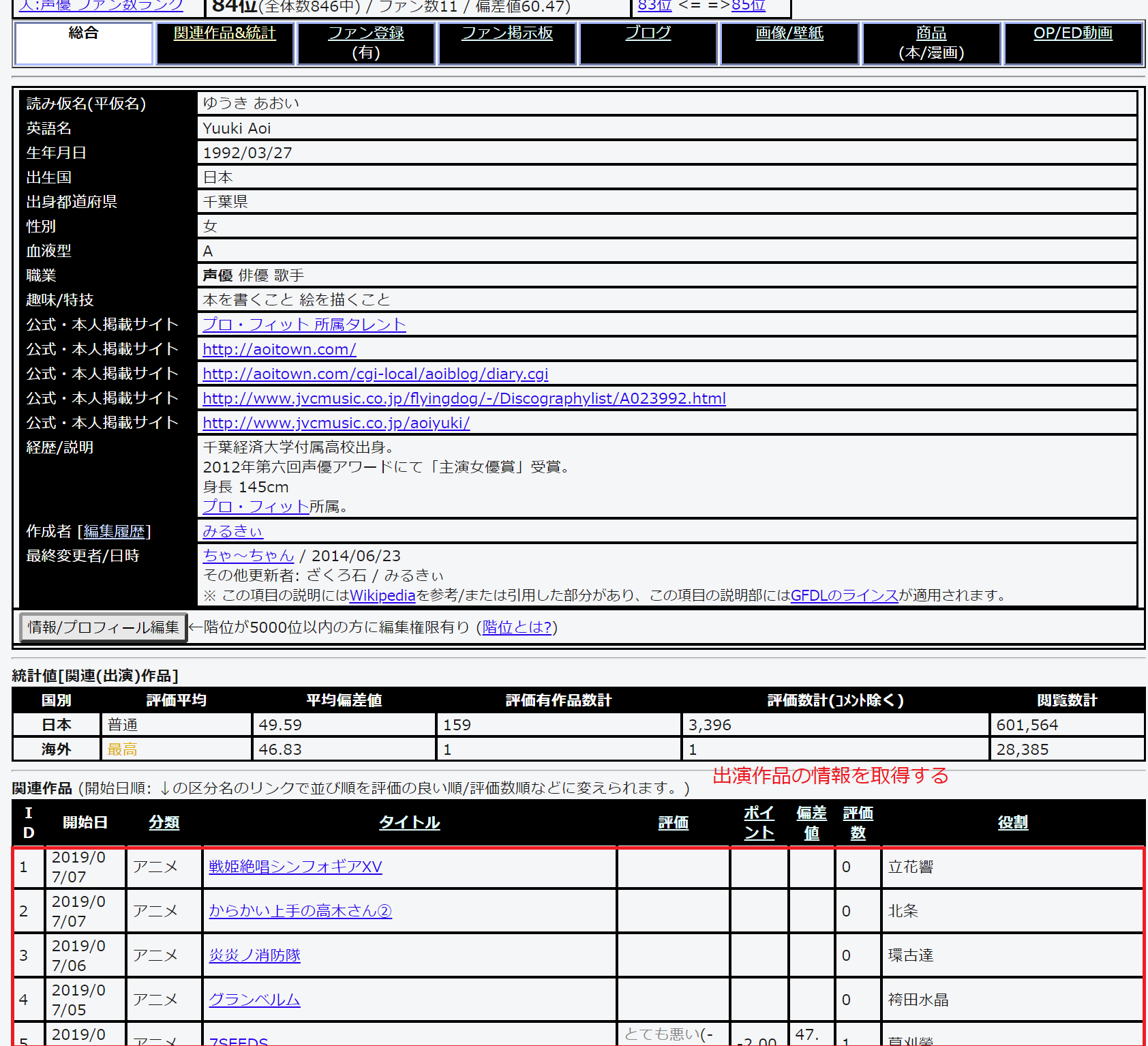
声優個人のURL情報を読み込みながら、出演作品の情報を読み込みます。
出演作品が登録されていない声優に対してはURLを読み込まないようにします。
最終的に「出演作品」プラス誰が演じているのかわかるように「出演している声優」のセットになるようにデータフレームを処理します。
何度もHTTP502とタイムアウトエラーが出て大変だった…
#リンク先に遷移した後の処理(タイムアウトおよびHTTP502エラー発生防止のため、上の繰り返し処理で一度に処理するのは避ける)
#集約用のデータフレーム
df_all2 <- data_frame()
#繰り返し処理 「声優の名前」、声優の「出演作品」でデータフレームを結合する
for(i in 1:nrow(df_all)){
#URL情報の読み込み
url_voice_actor_link_path <- paste0("https://sakuhindb.com",df_all$.[i])
data3 <- read_html(url_voice_actor_link_path)
#以下に該当する声優は出演している作品が登録されていないので除外する
if(df_all$名前[i] != "everying" &&
df_all$名前[i] != "エディ・キャロル" &&
df_all$名前[i] != "エルヴィア・オールマン" &&
df_all$名前[i] != "ゲーリー・オールドマン" &&
df_all$名前[i] != "ジョアキム・デ・アルメイラ" &&
df_all$名前[i] != "スタッピー・ケイ" &&
df_all$名前[i] != "須藤沙耶" &&
df_all$名前[i] != "関幸司" &&
df_all$名前[i] != "タイ・バレール" &&
df_all$名前[i] != "ディック・ビリングズリー" &&
df_all$名前[i] != "とべこ-じ" &&
#カタカナの「ニ」のようなので登録件数が0だった。登録ミス?
df_all$名前[i] != "ニ又一成" &&
df_all$名前[i] != "パトリシア・パリス" &&
df_all$名前[i] != "ファイブスピリッツ" &&
df_all$名前[i] != "ブリジット・バーコ" &&
df_all$名前[i] != "ベン・ステイン" &&
df_all$名前[i] != "相原玲" &&
df_all$名前[i] != "安永憲自" &&
df_all$名前[i] != "朝宮咲" &&
df_all$名前[i] != "阿部健太" &&
df_all$名前[i] != "あんべあつし" &&
df_all$名前[i] != "羽鳥佑" &&
df_all$名前[i] != "鵜飼久美子" &&
df_all$名前[i] != "石川雄也"&&
df_all$名前[i] != "梶村ひろ子" &&
df_all$名前[i] != "岩本規人" &&
df_all$名前[i] != "響綾香" &&
df_all$名前[i] != "古屋家臣" &&
df_all$名前[i] != "五島慎" &&
df_all$名前[i] != "呉林卓美" &&
#高橋美紀で文字化け発生。今年のデータ登録数は少なくランク外となるため除外としたい。
df_all$名前[i] != "高橋美紀" &&
df_all$名前[i] != "高村保裕" &&
df_all$名前[i] != "佐藤里緒" &&
df_all$名前[i] != "斎藤静江" &&
df_all$名前[i] != "三浦エリ" &&
df_all$名前[i] != "山下恵理子" &&
df_all$名前[i] != "山路清子" &&
df_all$名前[i] != "鹿島梵" &&
df_all$名前[i] != "手塚茂雄" &&
#小笠原良智で文字化け発生。今年のデータは一件も登録されていないため除外対象とする。
df_all$名前[i] != "小笠原良智" &&
df_all$名前[i] != "小珠ひかる" &&
df_all$名前[i] != "小泉一郎太" &&
df_all$名前[i] != "小倉直寛" &&
df_all$名前[i] != "小沢友誉" &&
df_all$名前[i] != "松島広明" &&
df_all$名前[i] != "松本聖" &&
df_all$名前[i] != "真優" &&
df_all$名前[i] != "杉原睦" &&
df_all$名前[i] != "星野健一" &&
df_all$名前[i] != "西尾尚子" &&
#西脇政敏で文字化け発生。今年のデータは一件も登録されていないため除外対象とする。
df_all$名前[i] != "西脇政敏" &&
df_all$名前[i] != "西澤由香" &&
df_all$名前[i] != "前島清志" &&
df_all$名前[i] != "大越多佳子" &&
df_all$名前[i] != "大竹みゆ" &&
df_all$名前[i] != "大田啓治" &&
df_all$名前[i] != "沢口りえ" &&
df_all$名前[i] != "辰巳千佐子" &&
df_all$名前[i] != "中澤薫" &&
df_all$名前[i] != "町風佳奈" &&
df_all$名前[i] != "渡辺友里江" &&
df_all$名前[i] != "土井友加里" &&
df_all$名前[i] != "土門敬子" &&
df_all$名前[i] != "納屋悟郎" &&
df_all$名前[i] != "白河真由" &&
df_all$名前[i] != "帆足新一" &&
#風祭修一で文字化け発生。今年のデータは一件も登録されていないため除外対象とする。
df_all$名前[i] != "風祭修一" &&
df_all$名前[i] != "服部潤" &&
df_all$名前[i] != "本田千秋" &&
df_all$名前[i] != "鈴木智晴" &&
df_all$名前[i] != "鈴木博紀" &&
df_all$名前[i] != "鷲崎健" &&
df_all$名前[i] != "渕崎有里子"){
voice_actor_data <- data3 %>>%
#ノード情報を取得
html_nodes(xpath = "//table[@class = 'table width_100per']") %>>%
#テーブル情報の取得 fill=TRUEにしないとエラーが発生する
html_table(fill = TRUE) %>>%
#4番目のリスト情報に声優の出演作品情報が入っている
'[['(4) %>>%
filter(X1 != 'ID') %>>%
#声優の出演作品情報に「名前」の列を追加する
mutate(voice_actor_name = df_all$名前[i])
}
#声優の情報を行結合で集約していく
df_all2 <- bind_rows(df_all2,voice_actor_data)
}
最後にデータフレームを加工して出演数の多い声優を見せるように工夫します。
# 集約した後の処理 ----------------------------------------------------------------
df_temp <- df_all2
#列名を変更
names(df_temp) <-c("num","year","genre","title","review","review_point","dv","evaluation_num","role","voice_actor_name")
df_set <- df_temp %>>%
#2019年のデータでフィルタする
filter(grepl("2019", year)) %>>%
#2019年7月のデータは除く(2019年1月~2019年6月までが対象であるため)
filter(!grepl("2019/07",year)) %>>%
#分類が「アニメ」のデータでフィルタする
filter(grepl("アニメ",genre))
#出演数の多い声優ベスト100になるようデータフレームを加工
df_set <- table(df_set$voice_actor_name) %>>%
as.data.frame() %>>%
arrange(desc(Freq)) %>>%
head(100)
#グラフで可視化する
#ggplotで可視化(100件だとめちゃくちゃ見づらかったので50件に絞る)
ggplot(df_set %>>% head(50),mapping = aes(x=reorder(Var1, Freq),y=Freq)) +
geom_bar(stat = "identity") +
coord_flip()
出演数が多い声優ベスト100
以下の結果が得られました。
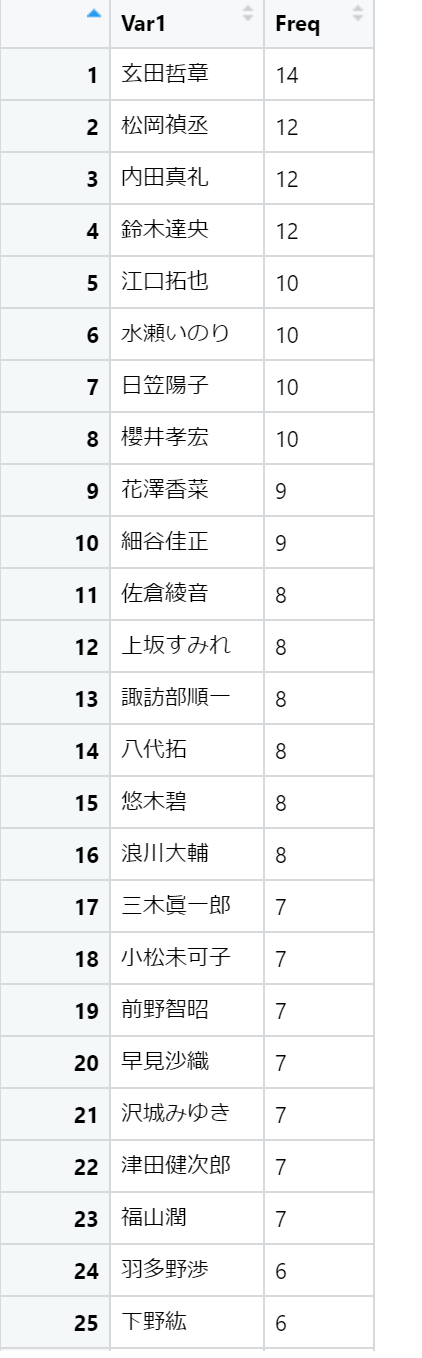
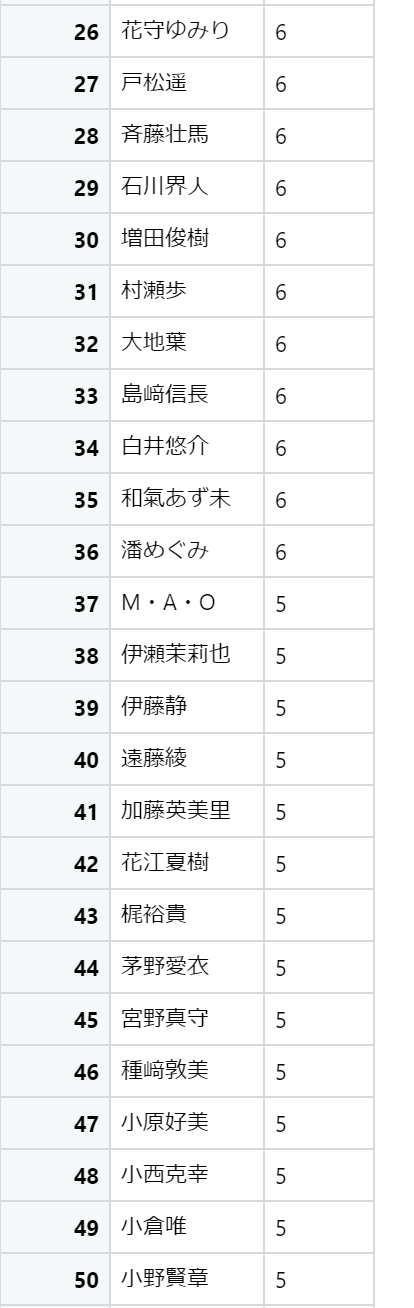
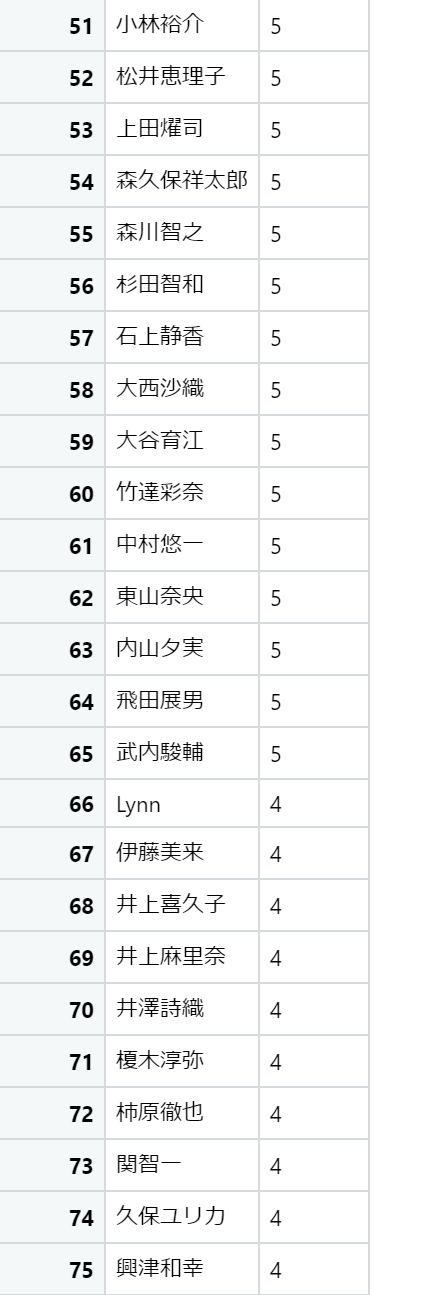
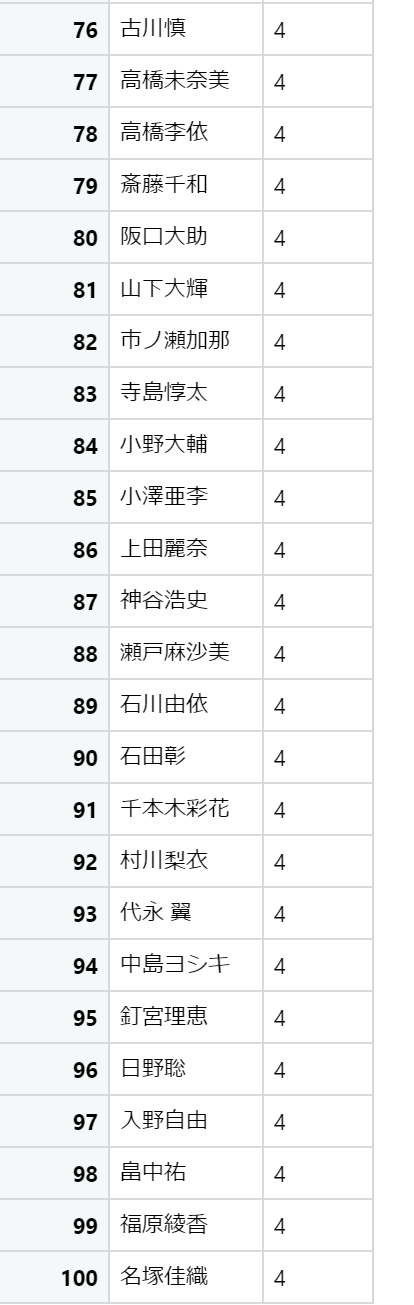
お好きな声優さんはランクインしていたでしょうか?
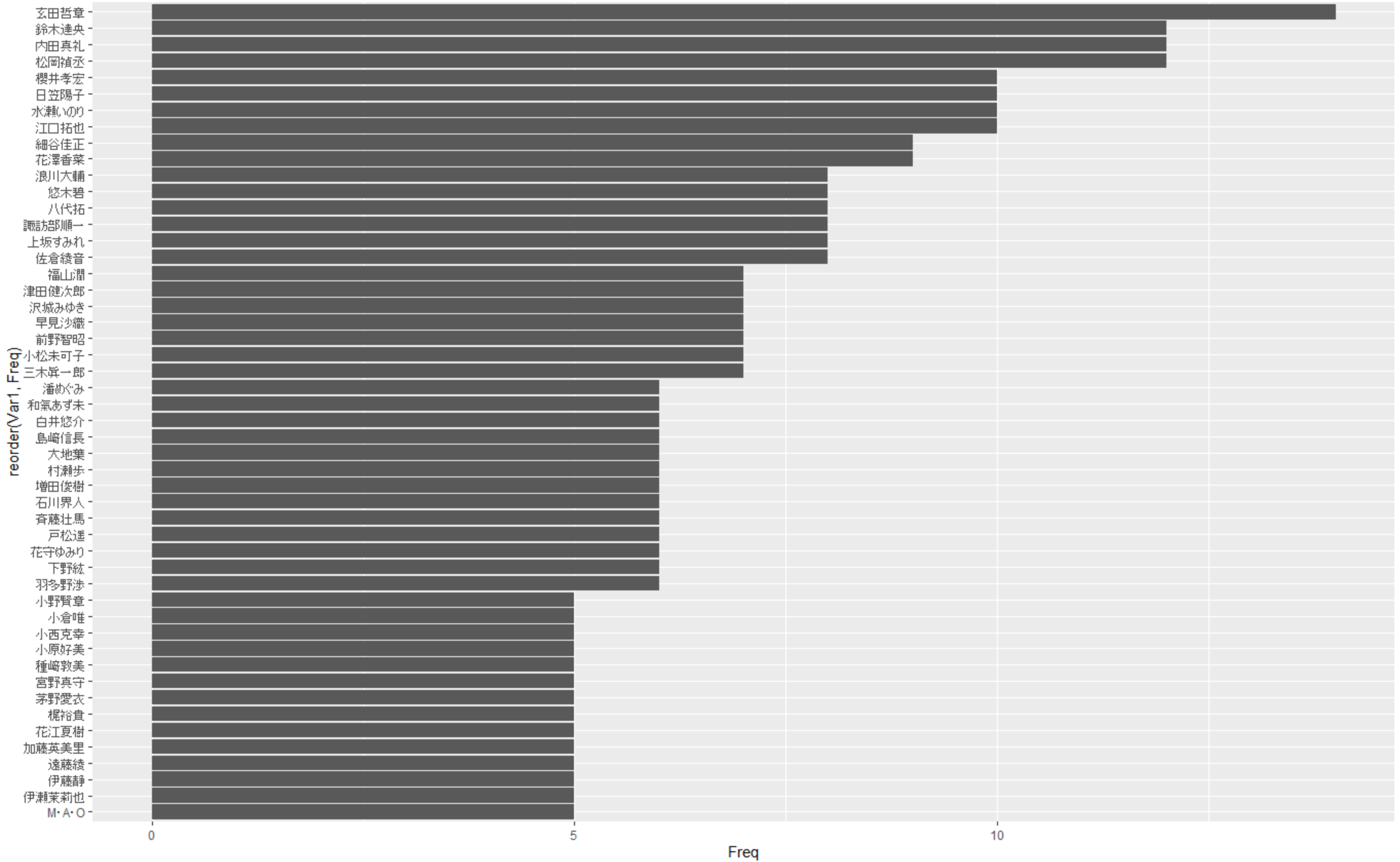
可視化
可視化した結果は以下の通りです。
上位100までを並べると文字が潰れて見づらかったので上位50を表示するようにしました。
上では最後まで結果を見せているし、別にいい…よね。
おわりに
大きな容量のデータを扱ったのは久しぶりでして、実装時間よりもHTTP502とタイムアウトエラーと戦っていた時間が長かったくらいですwモウヤリタクナイ( ^ω^)・・・
で、結果について触れますとぼくはあまりアニメに詳しくはないのですが、玄田さんがトップに輝くとは思いもよりませんでした(まぁ大好きなので良いんですが!)。
全体的にベテラン声優が根強く上位に食い込んでいたのは満足だったとして、若手と思しき方もいらっしゃるようで、少し詳しく追っていきたいなと思いました。
個人的には『鬼滅の刃』が物凄く良い満足度の高い作品で、花江夏樹さんが演じる竈門炭治郎の活躍には今後とも注目です。未視聴の方は是非視聴していただきたいです。