概要
LINEからメッセージ送信して、その入力値を元にスクレイピングしてクーポンの情報を返信するLINE Botを作成してみました!!
ちなみに今回クーポン取得対象のサイトは、Benefit Station というサイトです。
LINE Botの設定は、以下の記事で詳しく書きましたので、
この記事ではLambda内のスクレイピング処理をメインに書いていきます。
【Python3】LINE APIとLambda連携〜最速・速習メソッド〜
アジェンダ
・作ったものはどんな感じなの?
・使ったライブラリ&環境
・ソース
・苦労したこと
・終わりに
作ったものはどんな感じなの?
LINEからメッセージ(探したいクーポン名)送信。
*ここではカラオケと入力。
⬇︎検索結果が返ってくる。そして"View detail"を押下すると。。。
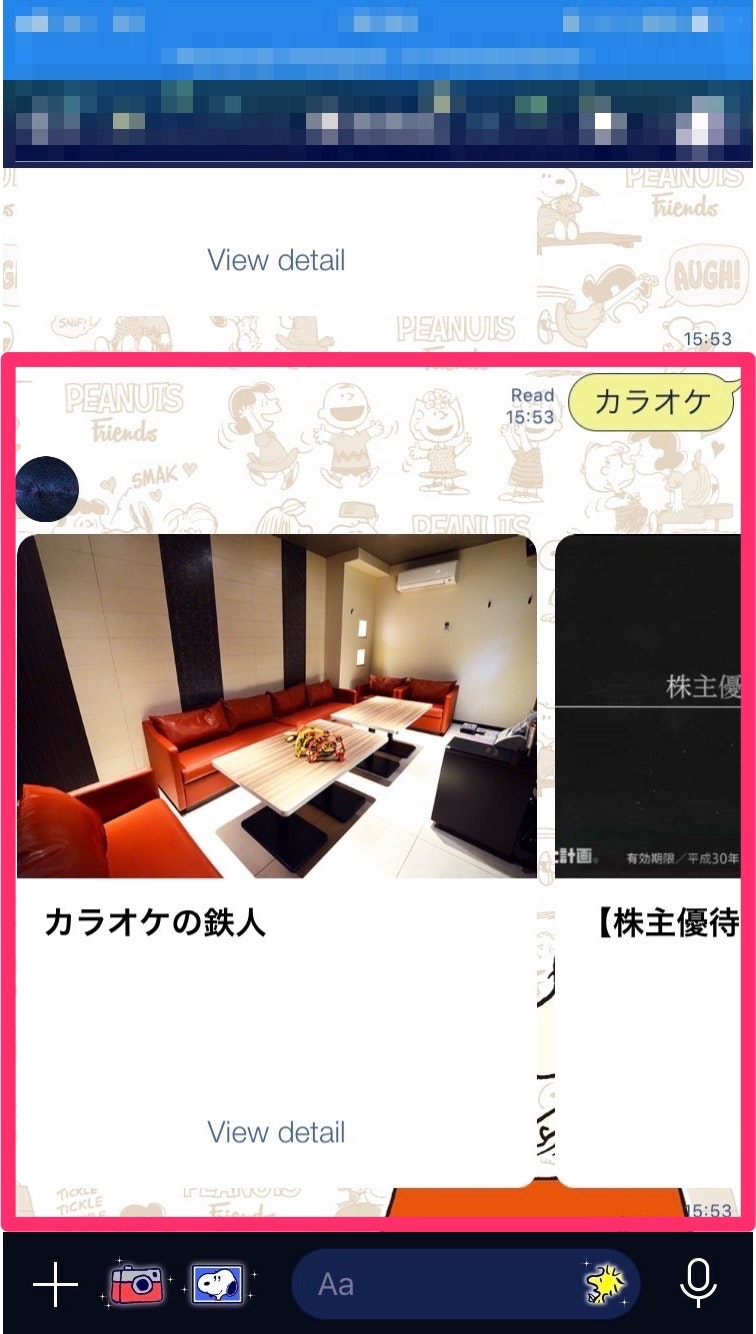
⬇︎スクレイピングで取得した検索結果のBenefit StationのURLに遷移!!
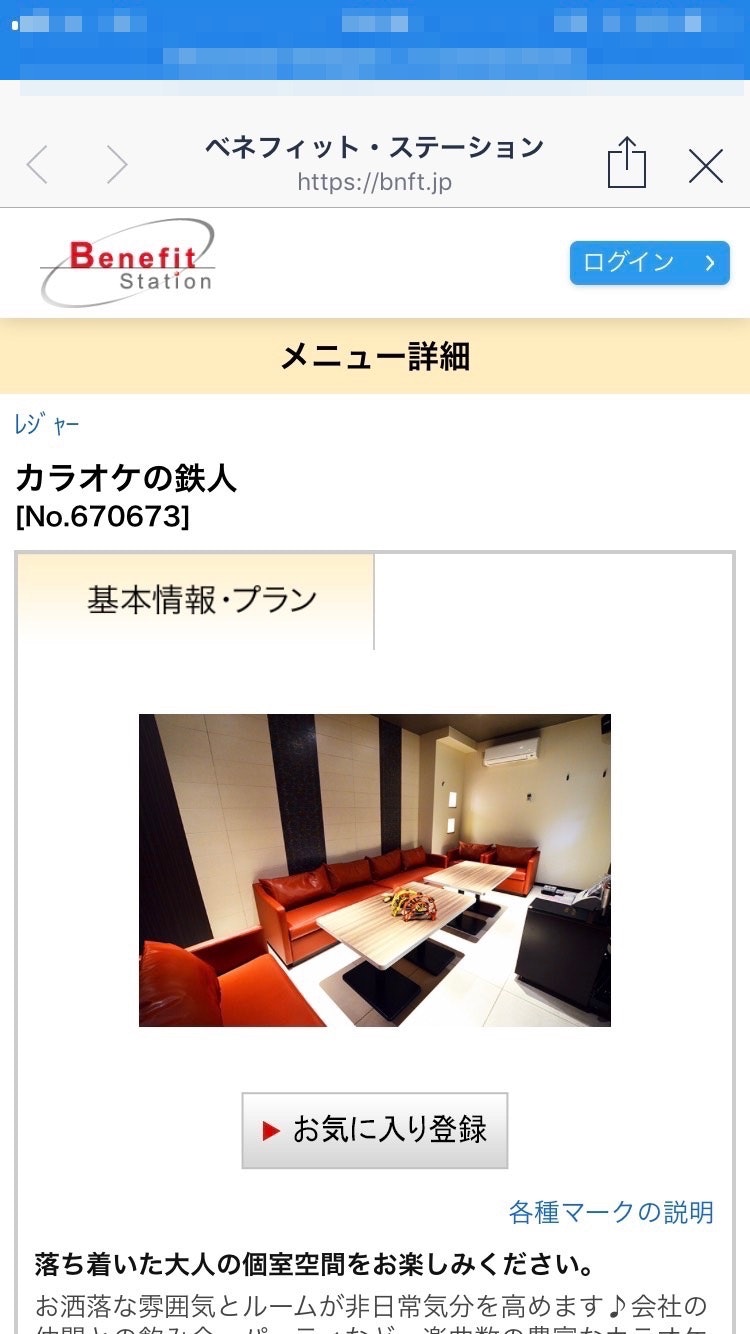
ちなみに
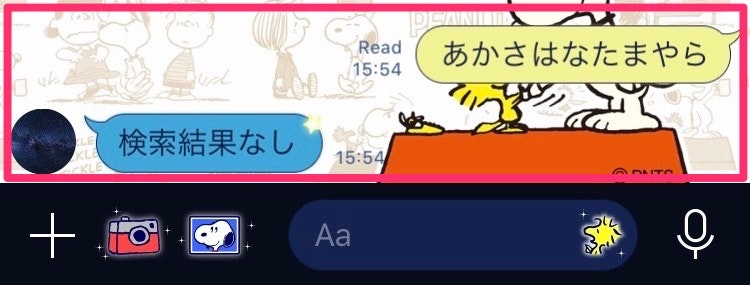
検索結果に該当するものがないと。。
⬇︎”検索結果なし”とメッセージを返す。
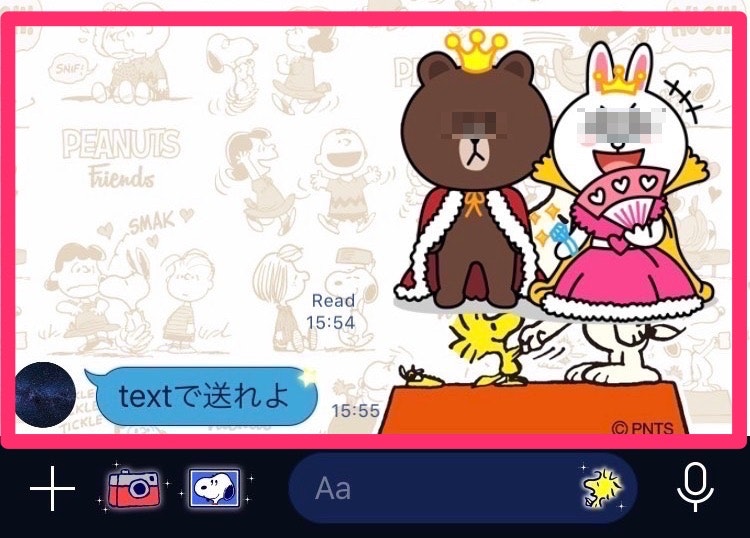
文字以外で送ると。。
⬇︎”textで送れよ”とメッセージを返すww
使ったライブラリ&環境
Selenium
Webブラウザを使いWebアプリケーションをテストするツール。
人の手を使ってテストしていた部分をSeleniumがブラウザ操作してくれる。
バージョンは、3.141.0 です。
chrome & chromedriver
chromeバージョン → v1.0.0-37
chromedriverバージョン → 2.37
以下、参考にさせていただきました!
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047d
ソース
少々ソースが長いですが、スクレイピングの処理はほぼlambda_handler関数内だけです!
(他のところはLINEの処理→【Python3】LINE APIとLambda連携〜最速・速習メソッド〜)
流れとしては
(1)Chromeの起動オプションを設定して、WebDriverのパスを指定しChromeを起動。
↓
(2)スクレイピング対象のURLをChromeで開く。
↓
(3)検索の入力フォームにLINEから送信したキーワードを入力し、Enterキー押下。
↓
(4)LINEに返却する必要な情報(ここではサービス名、URL、アイコン写真)を取得。
↓
(5)返却用フォーマットに格納し、返却
import logging
import os
import urllib.request
import json
import base64
import hashlib
import hmac
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# グローバル変数
LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN']
LINE_CHANNEL_SECRET = os.environ['LINE_CHANNEL_SECRET']
logger = logging.getLogger()
logger.setLevel(logging.INFO)
# グローバル変数
LINE_CHANNEL_ACCESS_TOKEN = os.environ['LINE_CHANNEL_ACCESS_TOKEN']
LINE_CHANNEL_SECRET = os.environ['LINE_CHANNEL_SECRET']
def lambda_handler(request, context):
options = webdriver.ChromeOptions()
options.binary_location = '/opt/headless/python/bin/headless-chromium'
# (1) Chromeの起動オプションを設定
options.add_argument('--headless')
options.add_argument("--no-sandbox")
options.add_argument("--single-process")
#ChromeのWebDriverオブジェクトを作成する。
driver = webdriver.Chrome(
executable_path = '/opt/headless/python/bin/chromedriver',
chrome_options = options
)
# (2) ベネフィットの検索ページを開く。
driver.get('https://bnft.jp/smp/m/t/top.faces')
#検索の入力フォームを取得。
input_element = driver.find_element_by_name('keyword')
logger.info(json.dumps(request))
# LINEからのリクエストか検証
if not validateReq(request) :
logger.info("LINE 以外からのアクセス")
return {'statusCode': 200, 'body': '{}'}
# LINEのevent回数分繰り返す
for event in json.loads(request['body'])['events']:
logger.info(json.dumps(event))
# textメッセージの場合
if event["message"]["type"] == "text":
# (3) Lineから入力された検索ワードを送信。
input_element.send_keys(event['message']['text'])
input_element.send_keys(Keys.RETURN)
# (4) 検索結果(サービス名,URL,写真)を格納する。
name = []
url = []
photo = []
for a in driver.find_elements_by_css_selector('.detail h3'):
if a is not None:
# 全角スペースを置換
name.append(a.text.replace('\u3000', ''))
for b in driver.find_elements_by_css_selector('.listboxMenu a'):
if b is not None:
url.append(b.get_attribute('href'))
for c in driver.find_elements_by_css_selector('.photo img'):
if c is not None:
photo.append(c.get_attribute('src'))
# ブラウザーを終了する。
driver.quit()
# 検索結果(サービス名)がなければ、なしと返却。
if name == []:
textMessage = "検索結果なし"
replyLine(event,makeLineMessage(event,textMessage))
# (5) 検索結果があれば返却用のメッセージを生成。
replyLine(event,replyLineCarlCell(event,name,url,photo))
else:
textMessage = "textで送れよ"
replyLine(event,makeLineMessage(event,textMessage))
return {'statusCode': 200, 'body': '{}'}
#LINEへ送るメッセージ作成
def makeLineMessage(event,textMessage):
return {
'replyToken': event['replyToken'],
'messages': [
{
"type": "text",
"text": textMessage
}
]
}
# LINEへReply
def replyLine(event,body):
url = 'https://api.line.me/v2/bot/message/reply'
headers = {
'Content-Type': 'application/json',
'Authorization': 'Bearer ' + LINE_CHANNEL_ACCESS_TOKEN
}
req = urllib.request.Request(url, data=json.dumps(body).encode('utf-8'), method='POST', headers=headers)
with urllib.request.urlopen(req) as res:
logger.info(res.read().decode("utf-8"))
# 署名の検証
def validateReq(request):
# 検証結果
validateResult = False
try:
# Request情報取得
body = request['body']
header = request['headers']
# リクエストBodyのハッシュ化(SHA256)
hash = hmac.new(LINE_CHANNEL_SECRET.encode('utf-8'),
body.encode('utf-8'), hashlib.sha256).digest()
# エンコーディング(base64)
signature = base64.b64encode(hash).decode('utf-8')
#検証
if signature == header['X-Line-Signature'] :
validateResult = True
except:
logger.info(e.args)
validateResult = False
finally:
return validateResult
# 検索結果を返す
def replyLineCarlCell(event,name,url,photo):
meg_list = []
# 検索結果件数分、リストに格納。
for (na, ur , pho) in zip(name, url, photo):
messages = {
"thumbnailImageUrl": pho,
"imageBackgroundColor": "#FFFFFF",
"title": na,
"text": " ",
"defaultAction": {
"type": "uri",
"label": "View detail",
"uri": ur
},
"actions": [
{
"type": "uri",
"label": "View detail",
"uri": ur
}
]
}
meg_list.append(messages)
# 検索結果分のリストを返却用フォーマットに格納
messages1 = {
"type": "template",
"altText": "Search Result",
"template": {
"type": "carousel",
"columns": meg_list ,
"imageAspectRatio": "rectangle",
"imageSize": "cover"
}
}
return {
'replyToken': event['replyToken'],
'messages': [messages1]
}
苦労したこと
①PhantomJSが使えない
Seleniumを使うなら、PhantomJSというヘッドレスブラウザとセットで使うことが多かったらしいですが、メンテナンスが終了して今では使えなくなってます。。
【解決法】
代わりにheadless chromeを利用。
②外部ライブラリなどのサイズが大きく、Lambda関数にアップロードできない
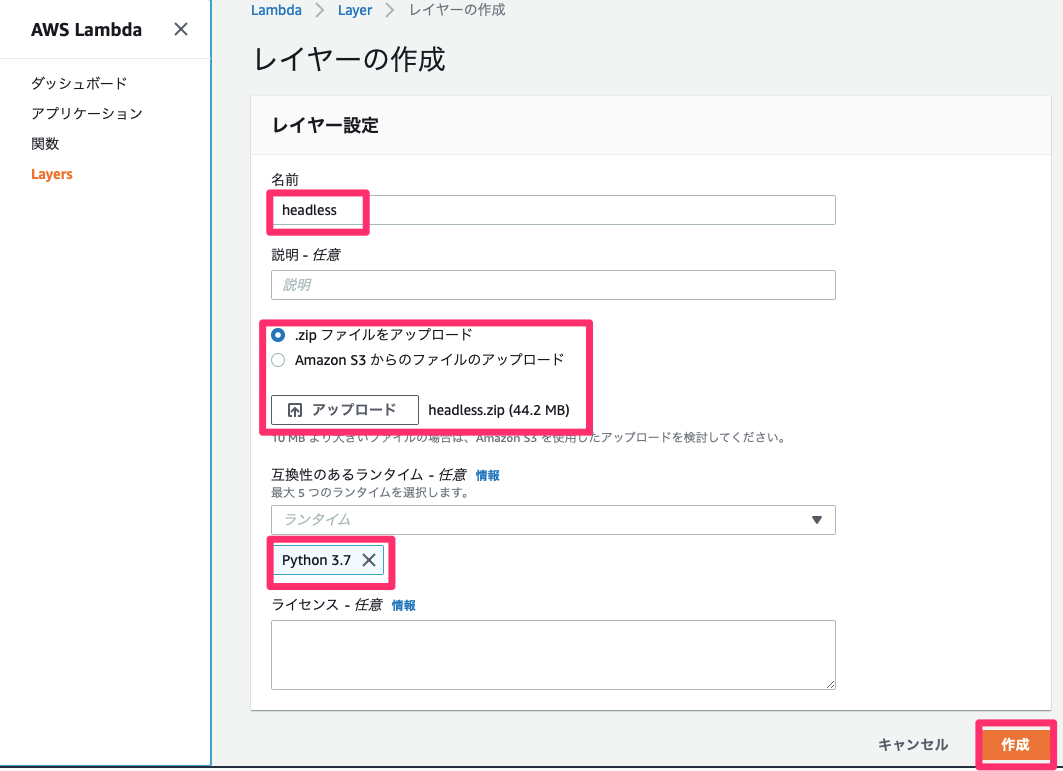
スクレイピングするために、「headless-chromium」と「chromedriver」をzip化してLambdaにアップしようとしましたが、サイズが50MBほどでアップできず。(Lambda関数は10MBが限度。。)
【解決法】
サイズが大きいものはLambdaのLayerにアップロード!!
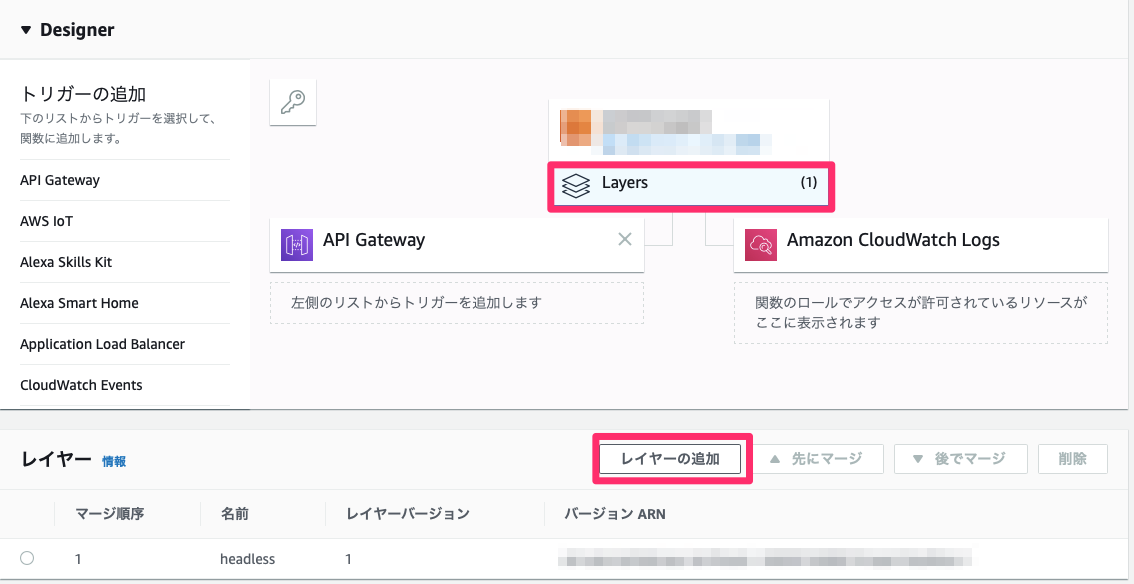
Lambda関数からLayerのモジュールを読み込むことが可能。
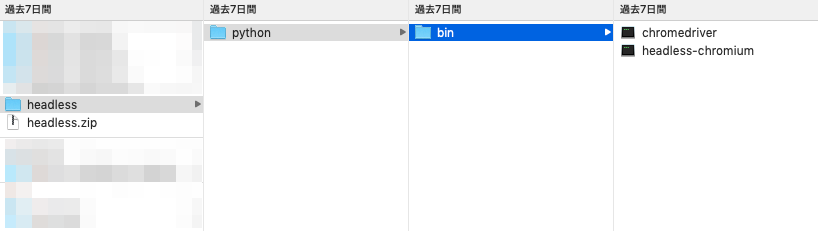
ちなみにLayerのディレクトリ構成は「/opt/layerに格納したモジュールのパス 」になる。
今回だと、Layerに「/headless/python/bin」のディレクトリ構成で、配下にheadless-chromiumとchromedriverを格納しアップした。
そのためLambda関数からLayerを呼び出すためには以下のパスを書いた。
options.binary_location = '/opt/headless/python/bin/headless-chromium'
...(中略)
executable_path = '/opt/headless/python/bin/chromedriver'
↓ディレクトリ構成。
↓zipで圧縮したディレクトリをLambdaのLayerにアップ。
↓Lambda関数からLayerを読み込みための設定。
③Chromeのエラー
初めはchromeの起動オプションは「--headless」だけでしたが、
実行してみると以下のエラーが出ました。。
ちなみに起動オプションは色々あるらしいです。
chrome起動オプション一覧
・「unknown error: Chrome failed to start: exited abnormally」
【解決法】
以下のオプションを追加。
options.add_argument("--no-sandbox")
・「unable to discover open window in chrome」
【解決法】
以下のオプションを追加。
options.add_argument("--single-process")
④ HTMLの解析
取得したいデータをスクレイピングするために、今回Benefit StationのHTMLを解析しました。(解析とちょっとカッコいいこと言いましたが、単純にクラス名は何なのか等を調べるだけですw)
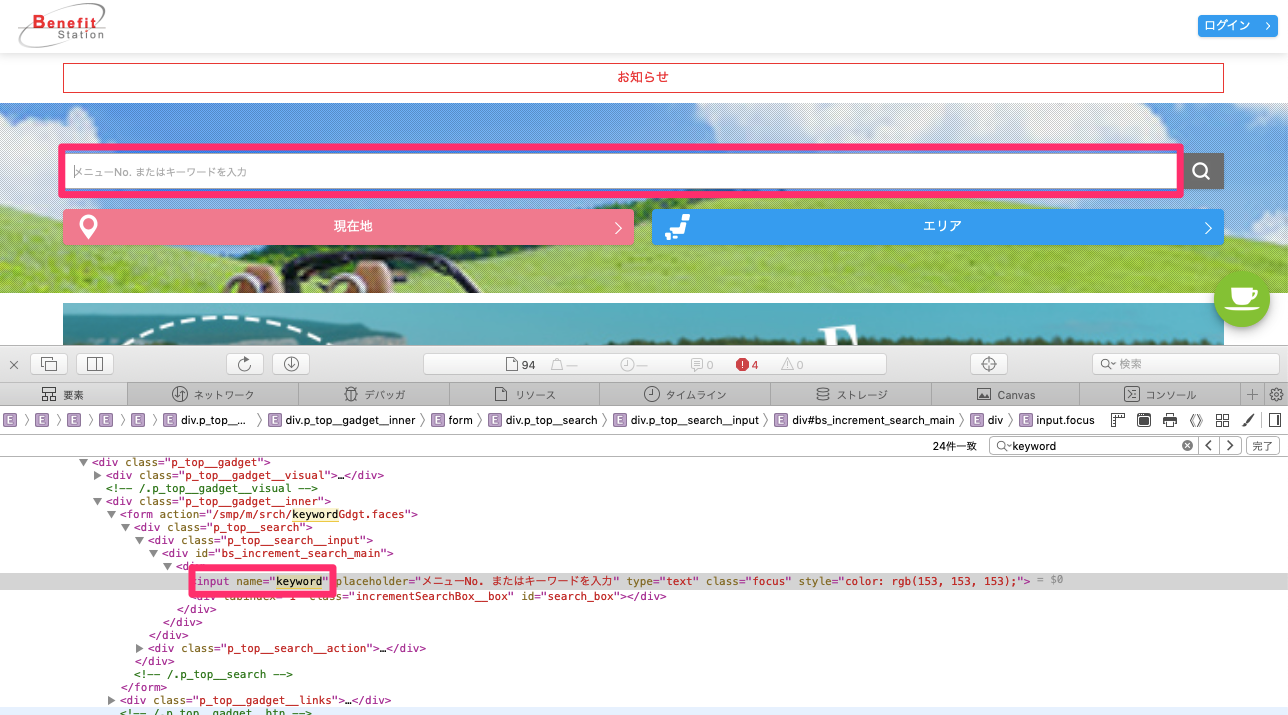
Macだと メニューバー>開発>Webインスペクタを表示 でソースを見れるので、今回だと最初の
検索の入力フォームは以下のように取得します。これと同じ要領で他に取得したいデータの属性を探していきます。
#検索の入力フォームを取得。
input_element = driver.find_element_by_name('keyword')
⑤ Lambdaのタイムアウト
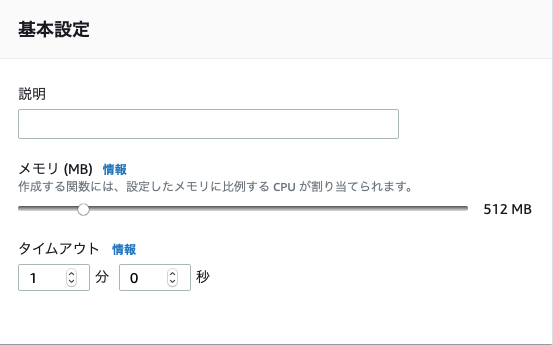
スクレイピングするため処理時間が少しかかります。
そのため基本設定のタイムアウトはデフォルトだと3秒のため以下のエラーが発生。
・「Task timed out after 3.00 seconds」
なので、以下のようにLambda関数のメモリとタイムアウトを延ばしました。
ちなみに今回作成した関数は処置時間約20秒弱かかります。。
終わりに
今回初めてスクレイピングを実装してみましたが、HTMLを解析したりと楽しく、また比較的容易に取り組むことができました!
今回は特定のサイトで、ページ遷移しない単純なスクレイピングであったため、いずれはもう少し複雑な(不特定のサイトを対象にスクレイピングなど)に挑戦できればなと思います。
あとスクレイピングの検索をもう少し早くできる方法があれば。。。
そしてBeautifulSoupやScrapyなどスクレイピングのライブラリが色々あるので使っていこうかなと!