Pythonで機械学習を使ったデータ分析作業を始めるのは簡単。無料で利用できるオープンソースの開発環境があるからだ。代表的なものには、米グーグル(Google)が提供する「Google Colaboratory(グーグル・コラボレートリー)」が挙げられる。
これは、グーグルの仮想マシン上でJupyter Notebookを使える開発環境だ。Jupyter Notebookは、Pythonプログラムを対話形式で開発できるツールである。
Google Colaboratoryは定番ライブラリーが使える状態で提供されているので、Pythonライブラリーを使って分析/機械学習を学ぶといった用途には最適だろう。Googleアカウントがあれば利用できるのも大きなメリットだ。そこで筆者もプログラムを実際に記述してみることにした。
scikit-learnでモデル作成
作成したプログラムは線形回帰分析のプログラムである。
回帰分析とは、結果データと結果に影響を及ぼすデータの関係性を統計的に求める手法である。結果のデータを「目的変数」、結果に影響を及ぼすデータを「説明変数」と呼ぶ。
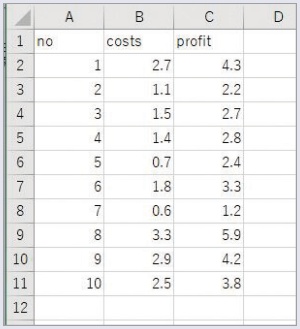
モデルを作成するための教師データを下記に示す。このCSVファイルを読み込ませて学習し、モデルから予想できる結果を表示する。
Jupyter Notebookに記載したプログラムを下記に示す。プログラムは「ライブラリーの読み込み」「CSVファイルの読み込み」「モデルの作成」「グラフ表示」のパートに分けられる。
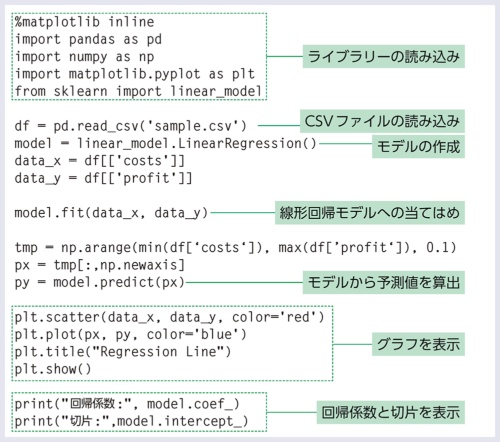
使っているライブラリーは「pandas(パンダス)」「scikit-learn(サーキットラーン)」「NumPy(ナムパイ)」「Matplotlib(マットプロットリブ)」という定番の4つである。pandasを使ってCSVファイルをデータフレームに読み込んでデータを整形する、scikit-learnのモデルを使って予測する、NumPyを使って計算する、Matplotlibで表示する、という処理を実装している。
scikit-learnには、回帰分析を実現するモデルとして「線形回帰モデル」が搭載されている。線形回帰とは、全てのデータにできるだけ近い直線を引くことで予測を行うモデルのことだ。直線の式は、最小2乗法を用いて求めている。