スクレイピング記事を立て続けに2本書かせていただいたのですが、それでも飽き足らずにスクレイピングを続けております。
今回は食べログさんのサイトから美味いラーメン屋をスクレイピングにより抽出してみます。
筆者は埼玉県民なので、埼玉のラーメン屋をターゲットにしています。
抽出項目
店名:store_name
星の数:stars
レビュー件数:number_of_reviews
今回は星の数3.5以上を抽出してみます。
実装
まずはパッケージの宣言から。
そして自作関数の読み込みを行っておきます。
ランキングページごとに大量のデータを読み込むことになるので、関数を作成しておくと後々冗長なコードを書くことを防ぐことができます。
ramen.r
# ライブラリ -------------------------------------------------------------------
pacman::p_load(pipeR,textreadr,rvest,lubridate,tidyverse)
# ソース本文 -------------------------------------------------------------------
#関数
get_tabelog_review <- function(url_txt){
url <- read_html(url_txt)
#店名
store_name <-url %>>%
html_nodes(xpath = "//a[@class = 'list-rst__rst-name-target cpy-rst-name js-ranking-num']") %>%
html_text(.,trim = FALSE)
#星
stars <-url %>>%
html_nodes(xpath = "//span[@class = 'c-rating__val c-rating__val--strong list-rst__rating-val']") %>%
html_text(.,trim = FALSE)
#レビュー件数
number_of_reviews <-url %>>%
html_nodes(xpath = "//a[@class = 'list-rst__rvw-count-target']") %>%
html_text(.,trim = FALSE)
df <- tibble(store_name,stars, number_of_reviews)
return(df)
}
次に、ランキングの読み込むページ数を設定します。
1ページにつき20項目がずらっと表示されるので総件数 ÷ 20(小数点以下切り捨て)で読み込むページ数を決定できるはずです。
その後URLを定義しますが、「(URL前半) / ページ番号 / (URL後半)」で各ページが構成されている都合上、URLの前半部、後半部でそれぞれ変数を定義する必要があります。
ramen.r
url_txt <- "https://tabelog.com/saitama/rstLst/ramen/?Srt=D&SrtT=rt&sort_mode=1&svd=20190617&svt=1900&svps=2"
data <- read_html(url_txt)
#ページ番号の決定
pages_num <-data %>>%
html_nodes(xpath = "//span[@class = 'list-condition__count']") %>%
html_text(.,trim = FALSE) %>>%
as.numeric()
pages_num <- round(pages_num / 20)
#URLの構成上、前半部分と後半部分に分ける
url_first_half <- "https://tabelog.com/saitama/rstLst/ramen/"
url_latter_half <- "/?Srt=D&SrtT=rt&sort_mode=1&svd=20190617&svt=1900&svps=2"
df_reviews <- data.frame()
準備ができたらfor文による繰り返しにより、ページ数分関数を読み込みデータフレーム結合を行っていきます。
ramen.r
#for文による繰り返し
for(i in 1:pages_num){
url <- paste0(url_first_half, i,url_latter_half)
tmp <- get_tabelog_review(url)
df_reviews <- rbind(df_reviews, tmp)
}
最後の仕上げに星3.5以上のラーメン屋のみを抽出します。
ramen.r
#星3.5以上のラーメン屋に絞る
df_reviews2 <- df_reviews[df_reviews$stars >= 3.50,]
変数df_review2の中身はどうなっているでしょうか。見てみましょう。
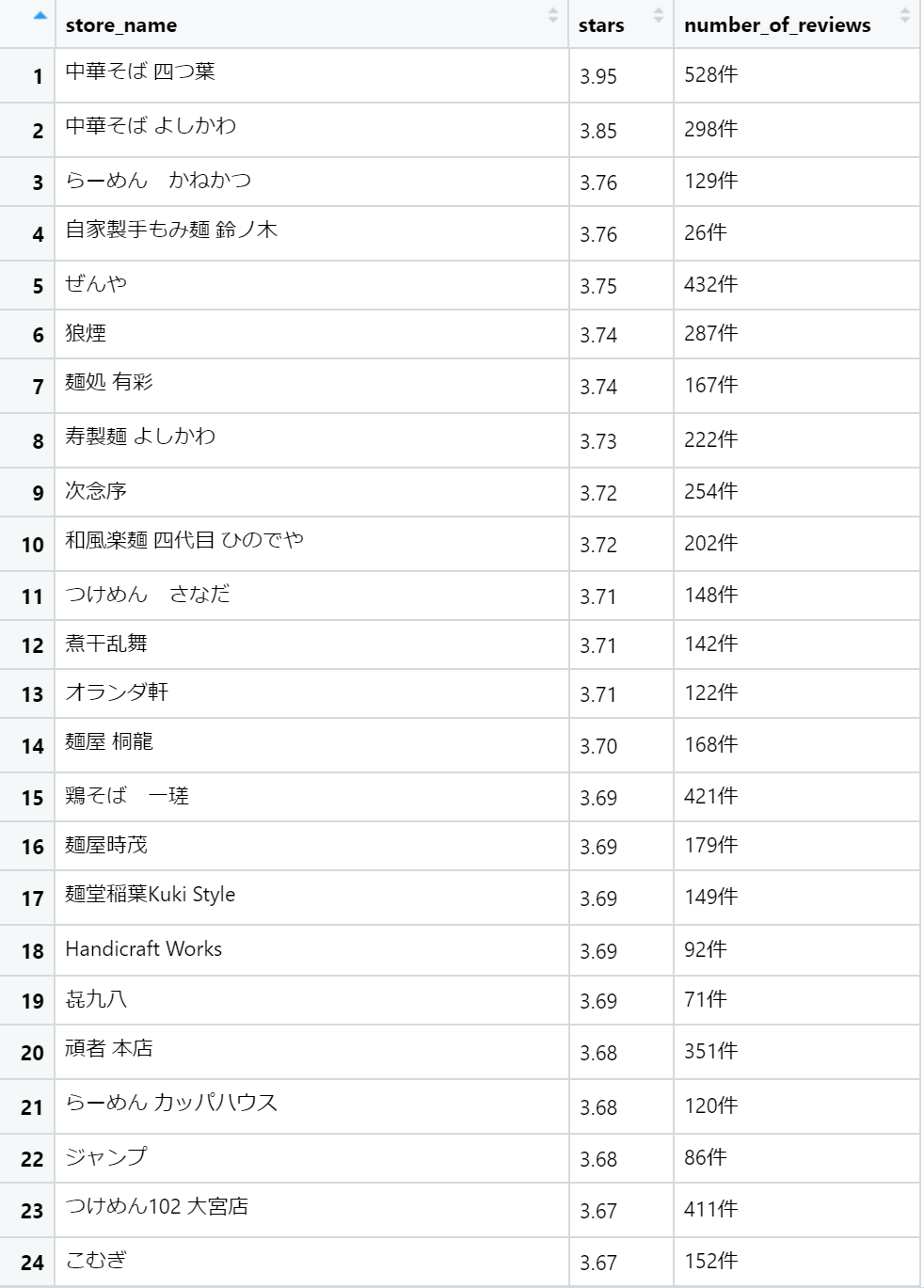
…
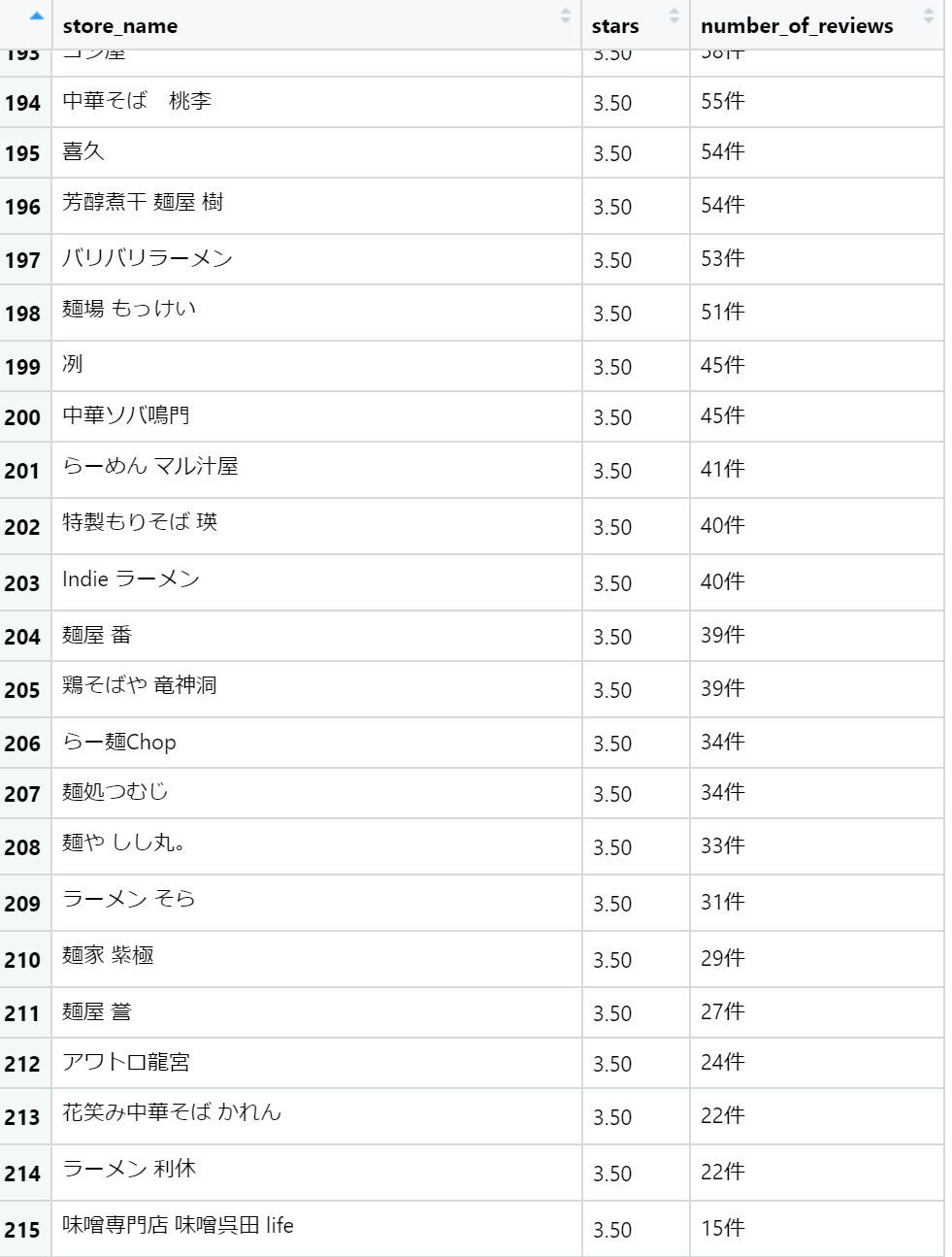
できているようですね。
やりました!