趣味の範疇ですが、着実にデータ加工おじさんとなりつつある筆者です。
「データ加工が楽しくなってきたし、次はAmazonでもスクレイピングしてみっか!」と意気込んだまではよかったのですが、すでに偉人が成し遂げられていたことが判明しまして、速攻で轟沈した次第。
諦め悪くも楽天のレビューデータをスクレイピングしてみたので、どなたかのご参考にでもなれば幸いです。
参照先のレビューデータ
Amazonに比べてレビュー数が少なくてアレですが
今回参考に使用するデータはサンクチュアリ社から出版されているミニマリストしぶさんの『手ぶらで生きる。 見栄と財布を捨てて、自由になる50の方法』を参照先にしました。
面白いから未読の人は読んでみてね。
実装
では、早速実装してみます。
まずはパッケージの宣言、それから読み込みたいWebページの情報をread_html関数により抽出します。
rakuten_review.r
# ライブラリ -------------------------------------------------------------------
pacman::p_load(pipeR,textreadr,rvest,lubridate,tidyverse)
# ソース本文 -------------------------------------------------------------------
url_txt <- "https://review.rakuten.co.jp/item/1/213310_19053873/1.1/"
#ページの読み込み
data <- read_html(url_txt)
次に投稿者、内容、使いみち、使う人、購入した回数の情報それぞれの情報を下記のコードのように抽出します。
できれば評価(星〇点)も抽出したかったのですが、構造を見たところ画像データが埋め込まれているようでして、どうやったら抽出できるかわからなかったので断念しました。
(2019/06/19修正)大変ありがたくコメントいただける方がいらっしゃいまして、星の数も無事取得することができました。
ご指摘くださった方、ありがとうございます。
rakuten_review.r
#投稿者
name <-data %>>%
html_nodes(xpath = "//dt[@class = 'revUserFaceName reviewer']") %>%
html_text(.,trim = FALSE)
#内容
review <-data %>>%
html_nodes(xpath = "//dd[@class = 'revRvwUserEntryCmt description']") %>%
html_text(.,trim = FALSE)
#使いみち
use <-data %>>%
html_nodes("#revRvwSec .revRvwMain .revRvwMainInr .revRvwUserMain .revRvwUserDisp .revUserDispList") %>%
html_text(.,trim = FALSE) %>>%
as.data.frame() %>>%
filter(grepl("商品の使いみち", .))
#商品を使う人
user <-data %>>%
html_nodes("#revRvwSec .revRvwMain .revRvwMainInr .revRvwUserMain .revRvwUserDisp .revUserDispList") %>%
html_text(.,trim = FALSE) %>>%
as.data.frame() %>>%
filter(grepl("商品を使う人", .))
#購入した回数
nof <-data %>>%
html_nodes("#revRvwSec .revRvwMain .revRvwMainInr .revRvwUserMain .revRvwUserDisp .revUserDispList") %>%
html_text(.,trim = FALSE) %>>%
as.data.frame() %>>%
filter(grepl("購入した回数", .))
#星の数
stars <- data %>>%
html_nodes(xpath = '//*[contains(concat( " ", @class, " " ), concat( " ", "value", " " ))]') %>%
html_text(.,trim = FALSE)
データを抽出したら最後に結合し、確認してみます。
rakuten_review.r
df <- tibble(name, review, use, user, nof,stars)
view(df)
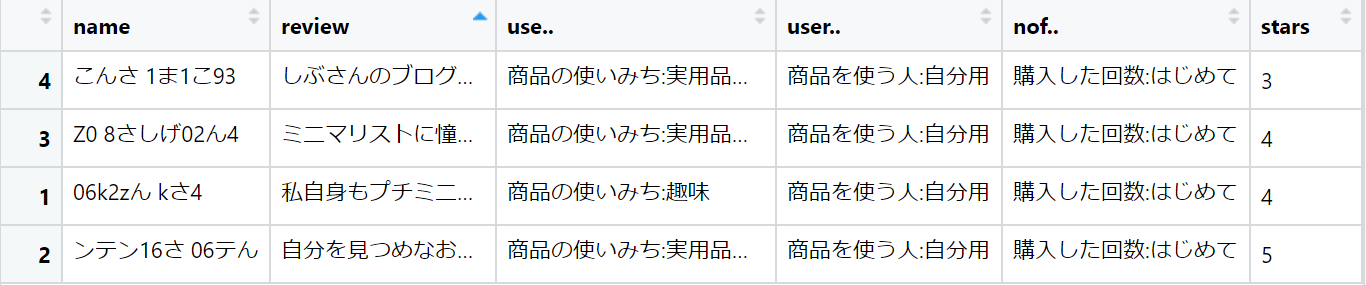
できました!
ここまで出来れば解析が捗りそうですね。
やっていきましょう。