以前作ったけど環境がない
前に作って動かしてました→Hiroya_AI
が、Windowsを初期化→Linuxぶちこんだせいで動かしてた環境がない
そんな時にまた最近こんな記事を見つけた
マルコフ連鎖を使って自分らしい文章を生成する(Python3)
またやってみるかなって思って、Python書こうと思ったけど...。
Pythonの始め方ってどうやるんだっけ?
Pythonは入ってる。VSCodeで書けるようにはなってる。そこまでは知ってる。
仮想環境どうやって作るん?Pythonの補完出てこないやん?
フォーマットも効かへん。どないなってるんや?
Githubでのプロジェクト管理どうするんやっけ???
とまあひどい有様だったので、思い出すのも兼ねて書き留めます。
環境
とりあえずscreenfetchの出力でも記載しておきます。
$ screenfetch
██████████████████ ████████ hiroya@hiroya-pc
██████████████████ ████████ OS: Manjaro 18.0.4 Illyria
██████████████████ ████████ Kernel: x86_64 Linux 4.19.45-1-MANJARO
██████████████████ ████████ Uptime: 3h 45m
████████ ████████ Packages: 1418
████████ ████████ ████████ Shell: zsh 5.7.1
████████ ████████ ████████ Resolution: 1920x2160
████████ ████████ ████████ DE: Cinnamon 4.0.10
████████ ████████ ████████ WM: Muffin
████████ ████████ ████████ WM Theme: Arc-Dark-solid (Arc-Dark-solid)
████████ ████████ ████████ GTK Theme: Arc-Dark-solid [GTK2/3]
████████ ████████ ████████ Icon Theme: Papirus-Dark
████████ ████████ ████████ Font: Cantarell 10
████████ ████████ ████████ CPU: Intel Core i5-4210U @ 4x 2.7GHz [76.0°C]
GPU: Unknown
RAM: 4783MiB / 7865MiB
リポジトリの用意
Githubでリポジトリを作る
作った。
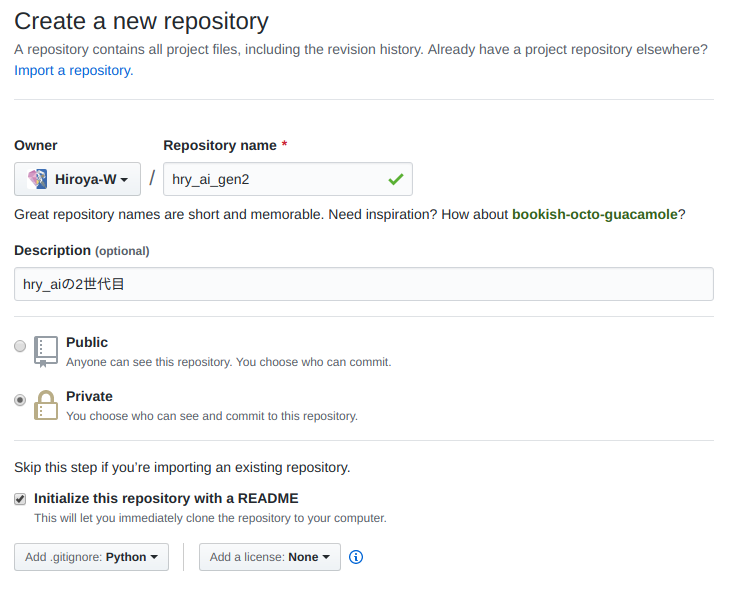
リポジトリをクローン
$ git clone git@github.com:Hiroya-W/hry_ai_gen2.git
Python仮想環境を作る
とりあえず最新verでいいかな。投稿現在(2019/06/13)では3.7.3が最新でした。
pipenvで環境構築を参考に。
$ cd hry_ai_gen2
// インストールできるバージョンの確認
$ pyenv versions
* system (set by /home/hiroya/.pyenv/version)
3.6.7
3.6.8
3.7.0
// 現在のバージョン
$ python --version
Python 3.7.3
// Pythonのインストール
$ pyenv install 3.7.3
// 仮想環境の作成
$ pipenv --python 3.7.3
// 仮想環境の有効
$ pipenv shell
VSCodeでPythonを書く準備
// VSCodeを起動
$ code .
$ mkdir src
$ touch src/helloworld.py
VSCodeが起動したら、pythonソースファイルを開くことで、Pythonの拡張機能が有効になる。
VSCodeの設定
setting.jsonを記載しておきます。
テーマや他プラグインの設定は省きましたが、僕はこんな感じに設定して使っています。
{
"editor.tabSize": 4,
"editor.formatOnPaste": true,
"editor.formatOnSave": true,
"editor.formatOnType": true,
"editor.snippetSuggestions": "inline",
"editor.tabCompletion": "on",
"editor.lineNumbers": "relative",
"python.autoComplete.addBrackets": true,
"python.linting.flake8Enabled": true,
"python.linting.pylintEnabled": false,
"python.formatting.provider": "black",
"python.linting.flake8Args": [
"--ignore=E221,E201,E203,E241,W503,E501"
],
"git.autofetch": true,
"git.enableSmartCommit": true,
"workbench.activityBar.visible": true,
"editor.renderWhitespace": "all",
}
インタープリターの選択
作成した仮想環境のインタープリターを使用する。
Ctrl + Shift + Pを入力してコマンドパレットを開き、Python: インタープリターを選択で、Python 3.7.3 64-bit('hry_ai_gen2':pipenv)を選択する。
Linterのインストール
flake8を使っているので、これを入れる。
$ pipenv install flake8
コードを書き込んでみる
Hello Worldを出力するコードを記述し、保存してみる。
print("Hello World")
フォーマッタはblackを利用しているので、これをインストールしろって表示される。おとなしくインストール。
2019年に向けてPythonのモダンな開発環境について考えるより引用。
なお、Black については記事執筆時点で正式リリースされておらず、pip install / pipenv install 時にプレリリース版をインストールするための --pre フラグが必要です。
$ pipenv install --pre black
インストール後、保存すると一番下に行が追加されたり、いらないスペースを自動で切り取ってくれたりする。
# before
print( "Hello World" )
# after
print("Hello World")
--空行
実行してみる
helloworld.pyをアクティブな状態にして、コマンドパレットからPython:ターミナルでPythonファイルを実行を選択。
VSCode上のターミナルにHello Worldが表示されることを確認する。
MeCabを入れる
python3からmecabを使ってみるを参考に。
本体
パッケージマネージャなどから、インストールする。
- mecab
- mecab-ipadic
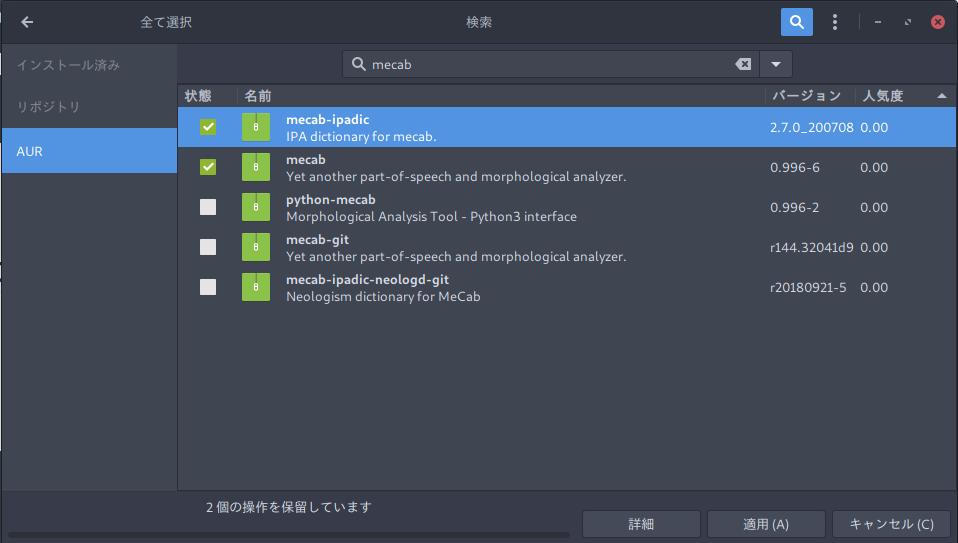
Pythonのmecabパッケージを入れる
$ pipenv install mecab-python3
インストールできてるか確認する
$ mecab --version
mecab of 0.996
$ pip list
mecab-python3
サンプルコードを実行してみる
python3からmecabを使ってみるから、コードをお借りします。
import MeCab
# mecab-python3を呼び出します。
m = MeCab.Tagger ("-Ochasen")
'''
mecabインスタンスの生成(出力フォーマットはchasen)
ヨミ:("-Oyomi")ます。
全情報:("-Odump")
わかち書き:("-O wakati")
etc... 公式ドキュメント見てください。
'''
text = input(">>")
print(m.parse (text))
# 標準入力をtextに代入し、表示させます。
実行して、適当な文章を入力してみる。
>>幾つかの文を連ねて、まとまった思想を表現したもの
幾つ イクツ 幾つ 名詞-一般
か カ か 助詞-副助詞/並立助詞/終助詞
の ノ の 助詞-連体化
文 ブン 文 名詞-一般
を ヲ を 助詞-格助詞-一般
連ね ツラネ 連ねる 動詞-自立 一段 連用形
て テ て 助詞-接続助詞
、 、 、 記号-読点
まとまっ マトマッ まとまる 動詞-自立 五段・ラ行 連用タ接続
た タ た 助動詞 特殊・タ 基本形
思想 シソウ 思想 名詞-一般
を ヲ を 助詞-格助詞-一般
表現 ヒョウゲン 表現 名詞-サ変接続
し シ する 動詞-自立 サ変・スル 連用形
た タ た 助動詞 特殊・タ 基本形
もの モノ もの 名詞-非自立-一般
EOS
ちゃんとできてる。すごい。
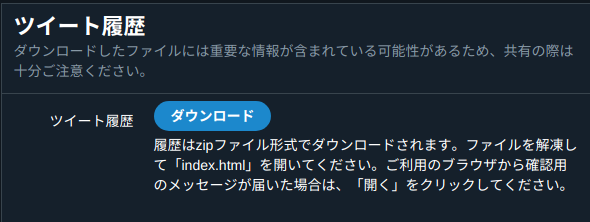
自分のツイート履歴のダウンロード
Twitter/設定から「全ツイート履歴をリクエストする」を選択する。
メールが届くので、そこからダウンロードする。
ツイート履歴前処理
ツイートの内容から以下を除外することにします。
- URLを含むツイート
- リツイート
- リプライツイートに含まれる@Userの部分
- @Youtubeを含むツイート
- 定期ツイート
意図しないハッシュタグツイートを防ぐため
- ハッシュタグの「#」の記号
URLを含むツイートの削除により、URLを除外するだけでなく、
- 診断メーカーのツイート
- 記事、動画共有のツイート
を除外でき、自分がつぶやいたツイート分のみ取り出すことにします。
また、改行ありのツイートは別々の文章として取り出します。
ツイート履歴がCSVファイルでもらえるようなので、pandasを使ってCSVファイルを読みこむようにします。
$ pipenv install pandas
ソースコードはコメントつけてみたのと、オリジナルの部分を追加したら長くなったので折りたたみました。
ソースコード
# -*- coding: utf-8 -*-
import pandas as pd
import re
# 除外用
autotweet_url = "autotweety.net"
search_keywords = ["RT", "https", "http", "@Youtube"]
replypattern = "@[\w]+"
def main():
# pandasのread_csvでCSVファイルを読み込む
df = pd.read_csv("data/tweets/tweets.csv")
# "text"の列を読み込む
tweets = df["text"]
# "source"の列を読み込む
sources = df["source"]
# 取り出したツイートを格納する配列
processedtweets = []
for i, tweet in enumerate(tweets):
# sources[i]にautotweet_urlが含まれていればcontinue
if autotweet_url in sources[i]:
continue
# ツイート除外キーワードが含まれていればcontinue
if contains_keywords(tweet):
continue
# ツイートに含まれる@Userの文字列を取り除く
processedtweet = re.sub(replypattern, "", tweet)
# #記号を取り除く
processedtweet = re.sub("#", "", processedtweet)
# 改行されているのを分割する
splittweets = processedtweet.replace("\n", ",").replace(" ", "").split(",")
# 文字列の格納
for splittweet in splittweets:
processedtweets.append(splittweet + "。")
# 1次元の配列に格納 + それぞれにindexを付与
processedtweetsDataFrame = pd.Series(processedtweets)
# textという名前でラベリングしてDataFrameを作成
newDF = pd.DataFrame({"text": processedtweetsDataFrame})
# CSVファイルとして出力
newDF.to_csv("processedtweets.csv")
# keywordsが含まれていればTureを返す
def contains_keywords(tweet):
result = False
for keyword in search_keywords:
if keyword in tweet:
result = True
break
return result
if __name__ == "__main__":
main()
実行すればいい感じになったCSVファイルができあがる。
ここらでcommitして、リモートリポジトリにpushする
後は適宜行うことを心がけておきます。
// 変更したファイルの一覧を確認
$ git status
// 差分表示
$ git diff
// 全てのファイルをステージングエリアに移動
$ git add *
// commitされるファイルの確認
$ git status
// commit前に差分の確認
$ git diff --cached
// commitする
$ git commit -a
// Vimが立ち上がるのでコミットメッセージを書いて:wq
// リモートリポジトリへpushする
$ git push origin master
DBへ保存する
ソースコード
マルコフ連鎖を使って自分らしい文章を生成する(Python3)にて、記載されているものをお借りします。
schema.sqlはプロジェクト直下に配置(processedtweets.pyと同じ階層)する。
schema.sql
drop table if exists chain_freqs;
create table chain_freqs (
id integer primary key autoincrement not null,
prefix1 text not null,
prefix2 text not null,
suffix text not null,
freq integer not null
);
PrepareChain.py
# -*- coding: utf-8 -*-
"""
与えられた文書からマルコフ連鎖のためのチェーン(連鎖)を作成して、DBに保存するファイル
"""
import re
import MeCab
import sqlite3
from collections import defaultdict
class PrepareChain(object):
"""
チェーンを作成してDBに保存するクラス
"""
BEGIN = "__BEGIN_SENTENCE__"
END = "__END_SENTENCE__"
DB_PATH = "chain.db"
DB_SCHEMA_PATH = "schema.sql"
def __init__(self, text):
"""
初期化メソッド
@param text チェーンを生成するための文章
"""
if isinstance(text, str):
text = text
self.text = text
# 形態素解析用タガー
self.tagger = MeCab.Tagger("-Ochasen")
def make_triplet_freqs(self):
"""
形態素解析から3つ組の出現回数まで
@return 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
# 長い文章をセンテンス毎に分割
sentences = self._divide(self.text)
# 3つ組の出現回数
triplet_freqs = defaultdict(int)
# センテンス毎に3つ組にする
for sentence in sentences:
# 形態素解析
self.tagger.parse("")
morphemes = self._morphological_analysis(sentence)
# 3つ組をつくる
triplets = self._make_triplet(morphemes)
# 出現回数を加算
for (triplet, n) in list(triplets.items()):
triplet_freqs[triplet] += n
return triplet_freqs
def _divide(self, text):
"""
「。」や改行などで区切られた長い文章を一文ずつに分ける
@param text 分割前の文章
@return 一文ずつの配列
"""
# 改行文字以外の分割文字(正規表現表記)
delimiter = "。|.|\."
# 全ての分割文字を改行文字に置換(splitしたときに「。」などの情報を無くさないため)
text = re.sub(r"({0})".format(delimiter), r"\1\n", text)
# 改行文字で分割
sentences = text.splitlines()
# 前後の空白文字を削除
sentences = [sentence.strip() for sentence in sentences]
return sentences
def _morphological_analysis(self, sentence):
"""
一文を形態素解析する
@param sentence 一文
@return 形態素で分割された配列
"""
morphemes = []
node = self.tagger.parseToNode(sentence)
while node:
if node.posid != 0:
morpheme = node.surface
morphemes.append(morpheme)
node = node.next
return morphemes
def _make_triplet(self, morphemes):
"""
形態素解析で分割された配列を、形態素毎に3つ組にしてその出現回数を数える
@param morphemes 形態素配列
@return 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
# 3つ組をつくれない場合は終える
if len(morphemes) < 3:
return {}
# 出現回数の辞書
triplet_freqs = defaultdict(int)
# 繰り返し
for i in range(len(morphemes) - 2):
triplet = tuple(morphemes[i : i + 3])
triplet_freqs[triplet] += 1
# beginを追加
triplet = (PrepareChain.BEGIN, morphemes[0], morphemes[1])
triplet_freqs[triplet] = 1
# endを追加
triplet = (morphemes[-2], morphemes[-1], PrepareChain.END)
triplet_freqs[triplet] = 1
return triplet_freqs
def save(self, triplet_freqs, init=False):
"""
3つ組毎に出現回数をDBに保存
@param triplet_freqs 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
# DBオープン
con = sqlite3.connect(PrepareChain.DB_PATH)
# 初期化から始める場合
if init:
# DBの初期化
with open(PrepareChain.DB_SCHEMA_PATH, "r") as f:
schema = f.read()
con.executescript(schema)
# データ整形
datas = [
(triplet[0], triplet[1], triplet[2], freq)
for (triplet, freq) in list(triplet_freqs.items())
]
# データ挿入
p_statement = "insert into chain_freqs (prefix1, prefix2, suffix, freq) values (?, ?, ?, ?)"
con.executemany(p_statement, datas)
# コミットしてクローズ
con.commit()
con.close()
def show(self, triplet_freqs):
"""
3つ組毎の出現回数を出力する
@param triplet_freqs 3つ組とその出現回数の辞書 key: 3つ組(タプル) val: 出現回数
"""
for triplet in triplet_freqs:
print("|".join(triplet), "\t", triplet_freqs[triplet])
GenerateText.py
# -*- coding: utf-8 -*-
"""
マルコフ連鎖を用いて適当な文章を自動生成するファイル
"""
import os.path
import sqlite3
import random
import sys
from PrepareChain import PrepareChain
numb_sentence = 5
class GenerateText(object):
"""
文章生成用クラス
"""
# def __init__(self, n=10):
def __init__(self):
# print ("sentence_numb=" + str(numb_sentence))
"""
初期化メソッド
@param n いくつの文章を生成するか
"""
self.n = numb_sentence
def generate(self):
"""
実際に生成する
@return 生成された文章
"""
# DBが存在しないときは例外をあげる
if not os.path.exists(PrepareChain.DB_PATH):
raise IOError("DBファイルが存在しません")
# DBオープン
con = sqlite3.connect(PrepareChain.DB_PATH)
con.row_factory = sqlite3.Row
# 最終的にできる文章
generated_text = ""
# 指定の数だけ作成する
for i in range(self.n):
text = self._generate_sentence(con)
generated_text += text
# DBクローズ
con.close()
return generated_text
def _generate_sentence(self, con):
"""
ランダムに一文を生成する
@param con DBコネクション
@return 生成された1つの文章
"""
# 生成文章のリスト
morphemes = []
# はじまりを取得
first_triplet = self._get_first_triplet(con)
morphemes.append(first_triplet[1])
morphemes.append(first_triplet[2])
# 文章を紡いでいく
while morphemes[-1] != PrepareChain.END:
prefix1 = morphemes[-2]
prefix2 = morphemes[-1]
triplet = self._get_triplet(con, prefix1, prefix2)
morphemes.append(triplet[2])
# 連結
result = "".join(morphemes[:-1])
return result
def _get_chain_from_DB(self, con, prefixes):
"""
チェーンの情報をDBから取得する
@param con DBコネクション
@param prefixes チェーンを取得するprefixの条件 tupleかlist
@return チェーンの情報の配列
"""
# ベースとなるSQL
sql = "select prefix1, prefix2, suffix, freq from chain_freqs where prefix1 = ?"
# prefixが2つなら条件に加える
if len(prefixes) == 2:
sql += " and prefix2 = ?"
# 結果
result = []
# DBから取得
cursor = con.execute(sql, prefixes)
for row in cursor:
result.append(dict(row))
return result
def _get_first_triplet(self, con):
"""
文章のはじまりの3つ組をランダムに取得する
@param con DBコネクション
@return 文章のはじまりの3つ組のタプル
"""
# BEGINをprefix1としてチェーンを取得
prefixes = (PrepareChain.BEGIN,)
# チェーン情報を取得
chains = self._get_chain_from_DB(con, prefixes)
# 取得したチェーンから、確率的に1つ選ぶ
triplet = self._get_probable_triplet(chains)
return (triplet["prefix1"], triplet["prefix2"], triplet["suffix"])
def _get_triplet(self, con, prefix1, prefix2):
"""
prefix1とprefix2からsuffixをランダムに取得する
@param con DBコネクション
@param prefix1 1つ目のprefix
@param prefix2 2つ目のprefix
@return 3つ組のタプル
"""
# BEGINをprefix1としてチェーンを取得
prefixes = (prefix1, prefix2)
# チェーン情報を取得
chains = self._get_chain_from_DB(con, prefixes)
# 取得したチェーンから、確率的に1つ選ぶ
triplet = self._get_probable_triplet(chains)
return (triplet["prefix1"], triplet["prefix2"], triplet["suffix"])
def _get_probable_triplet(self, chains):
"""
チェーンの配列の中から確率的に1つを返す
@param chains チェーンの配列
@return 確率的に選んだ3つ組
"""
# 確率配列
probability = []
# 確率に合うように、インデックスを入れる
for (index, chain) in enumerate(chains):
for j in range(chain["freq"]):
probability.append(index)
# ランダムに1つを選ぶ
chain_index = random.choice(probability)
return chains[chain_index]
if __name__ == "__main__":
param = sys.argv
if len(param) != 2:
print(("Usage: $ python " + param[0] + " number"))
quit()
numb_sentence = int(param[1])
generator = GenerateText()
gen_txt = generator.generate()
print(gen_txt)
storeTextsToDB.py
# -*- coding: utf-8 -*-
from PrepareChain import PrepareChain
import pandas as pd
from tqdm import tqdm
def storeTextsToDB():
df = pd.read_csv("processedtweets.csv")
texts = df["text"]
print(len(texts))
chain = PrepareChain(texts[0])
triplet_freqs = chain.make_triplet_freqs()
chain.save(triplet_freqs, True)
for i in tqdm(texts[1:]):
chain = PrepareChain(i)
triplet_freqs = chain.make_triplet_freqs()
chain.save(triplet_freqs, False)
if __name__ == "__main__":
storeTextsToDB()
必要なPythonのパッケージをインストール
$ pipenv install tqdm
実行
storeTextsToDB.pyを実行し、データベースを作成する。
プログレスバーが表示されるのがかっこいいですね。
処理が終了すれば、chain.dbが作成されます。
文章を作成する
引数が必要なのでVSCodeのコマンドパレットからPythonを実行するのではなく、ターミナルから実行する。
$ python src/GenerateText.py 1
うまく言葉は表せないけど流行ってるらしいじゃないかー。
それっぽいです...!
Pythonからツイートする
アクセストークンの取得
Twitter APIでアカウント認証してアクセストークン取得するサンプルを参考に進めてみます。
僕は、別のアカウントにつぶやきたかったので、確かこの方法を使ったと思います。
Windowsの頃は、XAMPPを入れて参考サイト先のphpファイルを使いました。
前に取得した記録が残っていたので、今回はそれを使う方向でいきます。
必要なPythonパッケージをインストール
$ pipenv install requests_oauthlib
ソースコード
以下のソースコードを書いてtweet.pyを実行すればTwitter上にHello, World!ってつぶやけると思う。
# -*- coding: utf-8 -*-
import config
from requests_oauthlib import OAuth1Session
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
twitter = OAuth1Session(CK, CS, AT, ATS)
params = {"status": "Hello, World!"}
req = twitter.post("https://api.twitter.com/1.1/statuses/update.json", params=params)
CONSUMER_KEY = "取得した"
CONSUMER_SECRET = "やつを"
ACCESS_TOKEN = "いれて"
ACCESS_TOKEN_SECRET = "おく"
GenerateText.pyで文章作成し、tweet.pyでツイートする
こんな感じにしてみました。作成する文章は2文がちょうどよかったので、GenerateText.pyのnumb_sentenceを2にしておきました。
# -*- coding: utf-8 -*-
import config
from requests_oauthlib import OAuth1Session
from GenerateText import GenerateText
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
twitter = OAuth1Session(CK, CS, AT, ATS)
generator = GenerateText()
gen_txt = generator.generate().replace("。", " ")
print(gen_txt)
params = {"status": gen_txt}
req = twitter.post("https://api.twitter.com/1.1/statuses/update.json", params=params)
後は、スケジュールで定期的ツイートするようにしてみます。
Scheduleを使う
cronでいいんじゃないかっていうのは言いっこなしだ
使い方
Python Scheduleライブラリでジョブ実行を参考に。
必要なPythonパッケージをインストールする
$ pipenv install schedule
ソースコード
定期的に実行したい処理部分をjob()にまとめて、main()でループを回す感じに使います。
# -*- coding: utf-8 -*-
import config
import schedule
import time
from requests_oauthlib import OAuth1Session
from GenerateText import GenerateText
CK = config.CONSUMER_KEY
CS = config.CONSUMER_SECRET
AT = config.ACCESS_TOKEN
ATS = config.ACCESS_TOKEN_SECRET
twitter = OAuth1Session(CK, CS, AT, ATS)
generator = GenerateText()
def job():
gen_txt = generator.generate().replace("。", " ")
print(gen_txt)
params = {"status": gen_txt}
twitter.post("https://api.twitter.com/1.1/statuses/update.json", params=params)
def main():
# 10分ごと
schedule.every(10).minutes.do(job)
while True:
schedule.run_pending()
time.sleep(1)
if __name__ == "__main__":
main()
できましたー!!!!
プロキシ環境で使いたい
OAuth1Sessionのpostにはプロキシ用の引数を与えることができるらしい。
略
twitter.post(
"https://api.twitter.com/1.1/statuses/update.json",
params=params,
proxies=config.proxies,
)
proxies = {"https": "http://username:password@proxy:8080"}
httpsのプロキシ設定を設定してあげることで、無事、ツイートすることができるようになりました。
Tweepyを使う
PythonでTwitter API使うならtweepyとかいうのがあるんだって?
使ってみよう。
ソースコード
こんな感じに書けば、Hello Tweepy!ってつぶやける。超簡単。
# -*- coding:utf-8 -*-
import tweepy
import config
CONSUMER_KEY = config.CONSUMER_KEY
CONSUMER_SECRET = config.CONSUMER_SECRET
auth = tweepy.OAuthHandler(CONSUMER_KEY, CONSUMER_SECRET)
ACCESS_TOKEN = config.ACCESS_TOKEN
ACCESS_SECRET = config.ACCESS_TOKEN_SECRET
auth.set_access_token(ACCESS_TOKEN, ACCESS_SECRET)
api = tweepy.API(auth)
api.update_status(status="Hello Tweepy!")