概要
Feature scalingとは、機械学習アルゴリズムへ入力する前に特徴量に対して行う前処理のこと。
このレッスンでは、最初にT-シャツを例にして、直感的な説明を行う。
その後、Mini-Projectで、Lesson9: Clustering まとめ Intro to Machine learning@Udacityにて取り上げたK-meansクラスタリングで、Feature scalingを実施する。
内容
T-シャツ問題
例えば下記のように、ChrisがLサイズのT-シャツを着るべきか、SサイズのT-シャツを着るべきかわからない状態を考えてみる。どちらのサイズを着るべきかのヒントとして、Cameron, Sarahの身長(ft:フィート)と体重(lbs:ポンド)、そして、彼らのT-シャツのサイズが与えられているとする。
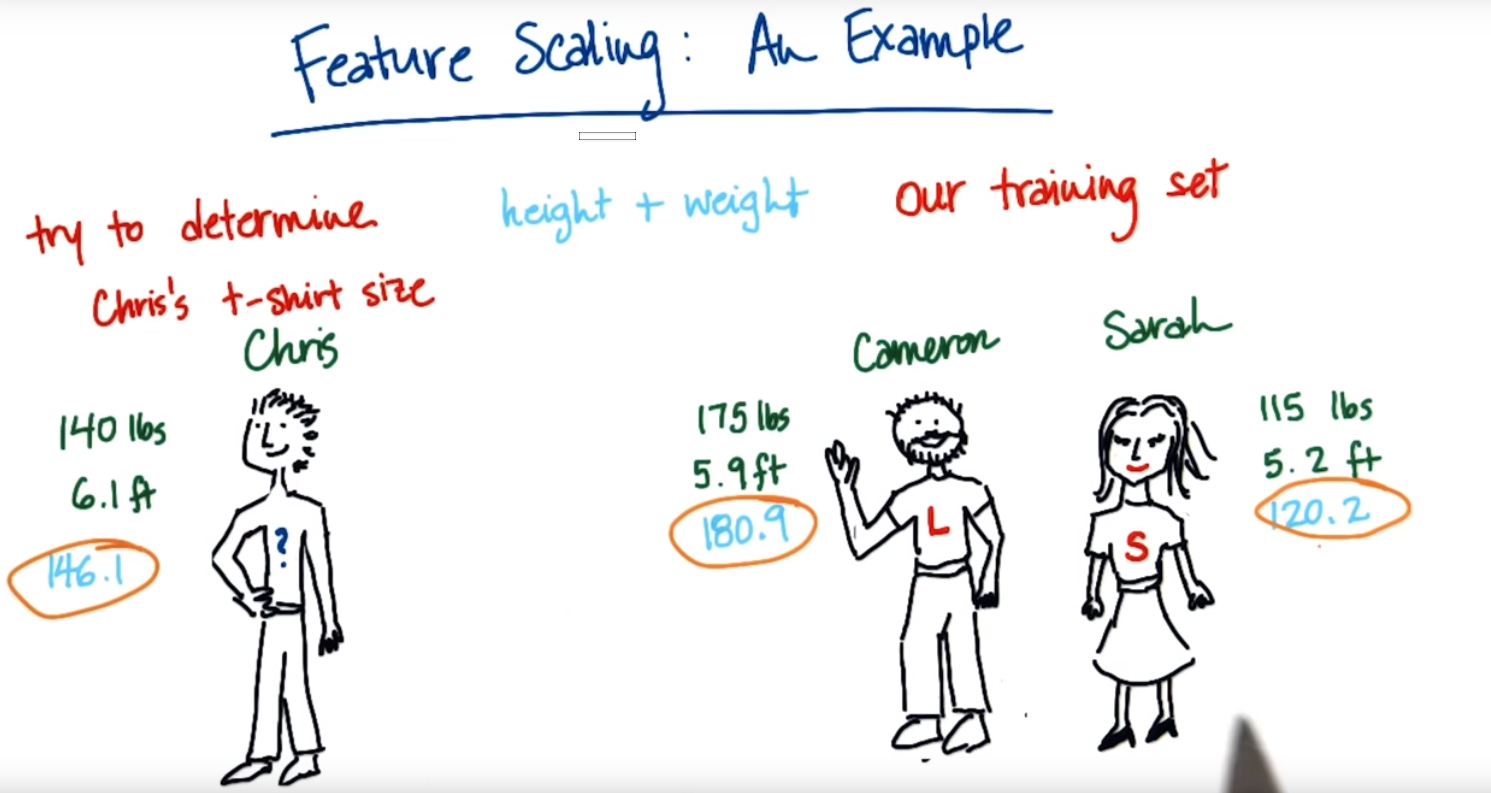
<直感的説明>
直感的には、身長と体重から、ChrisはCameronに近いので、Lを着るべきだと感じる。
そこで、これを数字の計算で裏付けてみる。
<数値での説明>
例えば「身長+体重」という値を考えてみると、
Cameronは 175[lbs] + 5.9[ft] = 180.9
Sarahは 115[lbs] + 5.2 [ft] = 120.2
ここで、
Chrisは 140[lbs] + 6.1[ft] = 146.1
この「身長+体重」という評価指標を用いるとChrisはSarahにより近く、サイズSを着るべきとなってしまい、直感値とずれる。なぜなら、この指標だと、身長がほとんどの値を占めていて、体重は誤差範囲くらいの影響しかないから。言い換えると身長の重みづけが多いから。これを、身長、体重両方とも同じくらいの重みづけで計算できるように、Feature Scalingを用いる。
具体的な計算式
Xをスケーリング前の特徴量、X'をスケーリング後の特徴量とすると
X' = \frac{X - X_{min}}{X_{max} - X_{min}}
となる。
これで先ず[Chris, Cameron, Sara]でデータがあるとすると、
身長は[6.1, 5.9, 5.2]
体重は[140, 175, 115]
それぞれスケーリングすると、
身長は[1, 0.222, 0]
体重は[0.417, 1, 0]
この時値は0~1の値になる。
ただし、外れ値がある場合は、スケーリングをするとデータがおかしくなってしまう。
上記のスケーリングした状態でもう一度 身長+体重 で計算してみると
Cameronは 0.222 + 1 = 1.222
Sarahは 0 + 0 = 0
Chrisは 1 + 0.417 = 1.417
Chrisは圧倒的にCameronに近いことがわかる。
コーディング:Quiz10
上記の体重のコーディングをしてみる。
### FYI, the most straightforward implementation might
### throw a divide-by-zero error, if the min and max
### values are the same
### but think about this for a second--that means that every
### data point has the same value for that feature!
### why would you rescale it? Or even use it at all?
def featureScaling(arr):
mini = min(arr)
maxi = max(arr)
deno = maxi-mini
x = []
if deno != 0:
for i in arr:
temp = (i-mini)*1.0/deno#1.0をかけないと少数以下が切り捨てられる。
x.append(temp)
else:
print "Every data point has the same value!it's 0.5"
for i in arr:
x.append(0.5)
return x
# tests of your feature scaler--line below is input data
data = [115, 140, 175]
print featureScaling(data)
<出力>
[0.0, 0.4166666666666667, 1.0]
Something to think about: What if x_max and x_min are the same? For example, suppose the list of input features is [10, 10, 10]--the denominator will be zero. Our suggestion would be in general to assign each new feature to 0.5 (halfway between 0.0 and 1.0), but it's really your call. The main point is that this exact formula can be broken.
と書いてあったので、全部同じデータの時は0.5を返すようにした。
Scalerの実装
上記はライブラリがある。sklearnのmin_max_scaler
sklearn:4.3. Preprocessing dataの4.3.1.1. Scaling features to a rangeを参照して実装すること。
この時にスケーリングされるデータがint型だと小数点以下は表示されなくなるので、1.0をかけたり、2.0等.0をつけたりしてfloat型にしておくこと。
Scalingの影響を受けやすいアルゴリズム
・SVM with RBF kernel
・K-means clustering
両方ともデータの2次元以上の距離を計算するため、影響を多大に受ける。
・決定木は常に1次元で切っていくので、影響を受けない。
・線形回帰は共分散でそれぞれの特徴量が独立だから、影響を受けないと言っていたがよくわからん
Mini-Project
lesson9にて行ったように、Enronのfinantial dataにK-meansクラスタリングを適用して、分類してみる。
Quiz16
"salary" と、"exercised_stock_options"をスケーリングして、そのtransformerを使って、"salary"= $200,000, "exercised_stock_options"=1 millionの場合、スケーリングの後にどのくらいの値になるのか見る。
lesson9のQuiz22,23のコードの後に下記を付け加えた。
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
arr_ex_st_op = np.array(list_ex_st_op).reshape(-1, 1)
ex_st_op_min_max = scaler.fit_transform(arr_ex_st_op)
one_mil_ex_st_op = 1000000
one_mil_ex_st_op = scaler.transform(one_mil_ex_st_op)
print("1,000,000 stock op:"+str(one_mil_ex_st_op))
arr_sal = np.array(list_sal).reshape(-1, 1)
arr_sal_min_max = scaler.fit_transform(arr_sal)
two_hand_th_sal = 200000
two_hand_th_sal = scaler.transform(two_hand_th_sal)
print("200,000 sal:"+str(two_hand_th_sal))
<出力>
1,000,000 stock op:[[0.02902059]]
200,000 sal:[[0.17962407]]
MinMaxScalerは2次元のnp.array型じゃないと受け付けないみたいで、list型をnp.arrayに変換と、2次元にreshapeしている。
nanがあるとMinMaxScalerは動かなくなるので、Data Frameにへんかんして、.dropna等で処理してからのスケーラー実行になる。今回は、if文を書いて要素それぞれがnanでないとき格納するようにしてnanを除去した。
感想
MiniMaxScalerの使い方がわかった。nanの処理をどうするかが課題だね。
調べた英単語
susceptible・・・adv, 感受性の強い、多感な、敏感な
ex)She's susceptible to colds.彼女はかぜをひきやすい
substantially・・・adj,実質上、大体は、十分に、
ex)This criticism is substantially correct.この批評はおおむね的を射ている.