MobileNetV2-PoseEstimation 
1.Introduction
複数の過去記事の検証により、 IntelのCPUとOpenVINOを組み合わせた場合、半端なGPUや外付けブースタによるパフォーマンスを遥かに凌駕したり、Tensorflow Liteの8ビット量子化を行った場合の驚異的なパフォーマンスを体感してきました。
(国内外でとても有名な日本人エンジニアの方が Tensorflow Lite のGPU対応に尽力されています。 私見ではありますが、Tensorflow Lite は、今後とても可能性を秘めている存在だと考えています。)
ご興味がある奇特な方は下記の過去記事をご覧ください。
[24 FPS, 48 FPS] RaspberryPi3 + Neural Compute Stick 2 一本で真の力を引き出し、悟空が真のスーパーサイヤ「人」となった日
Tensorflow Lite v1.11.0 を自力でカスタマイズしてPython API にMultiThread機能を追加→オフィシャルの2.5倍にパフォーマンスアップ
「がんばる人のための画像検査機 presented by shinmura0」をラズパイ単体でパワーアップして異常検出 (RaspberryPi3のCPUのみ) その2
今回も無茶なチャレンジを行ってみたいと思います。 検証期間が長くなりそうで、モチベーションを維持するのが大変になってきましたので、学習とモデルの変換→検証という2部構成に記事を分けようと思います。 最終的には自身のGithubリポジトリへ成果物一式をPushしようと思いますので少しお時間をください。
RaspberryPi3などのエッジデバイス上で Openpose を高速に動作させたかったため、モデルを VGG から MobileNetV2 ベースに置き換えて軽量化します。 この手順を実施すると、 OpenVINO, Tensorflow Lite の2種類のモデルが生成されます。
Google Edge TPU モデルへの変換にもかなりの時間を割きましたが、残念ながら現時点では成功していません。
TensorflowのQuantize処理後のTPUモデルコンパイラによる変換がどうにもうまくいきません。。。
なお、それぞれのフレームワーク特性に応じて作業過程の各種コマンドに差異が有ります。
記事の内容は試行錯誤の結果が露骨に表れていますので、つたない部分が有ります点はご容赦願います。
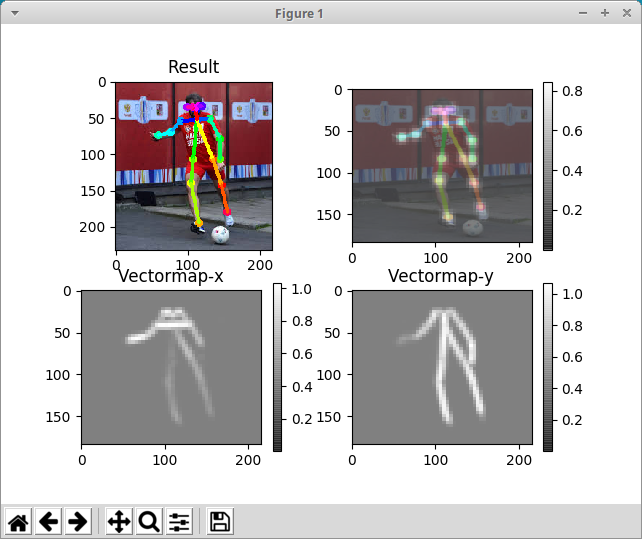
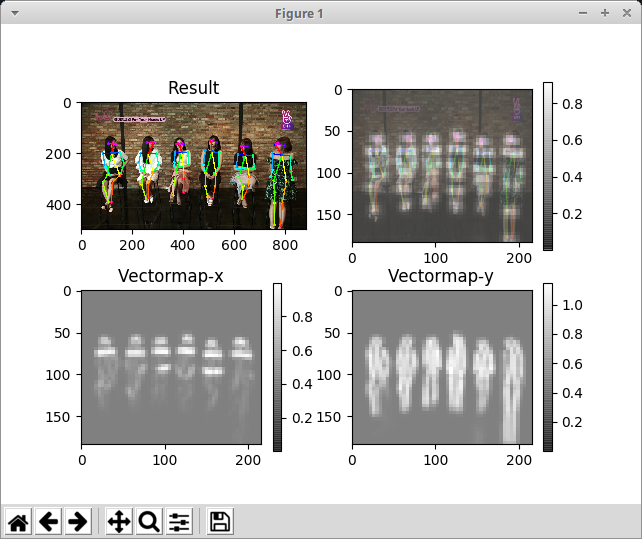
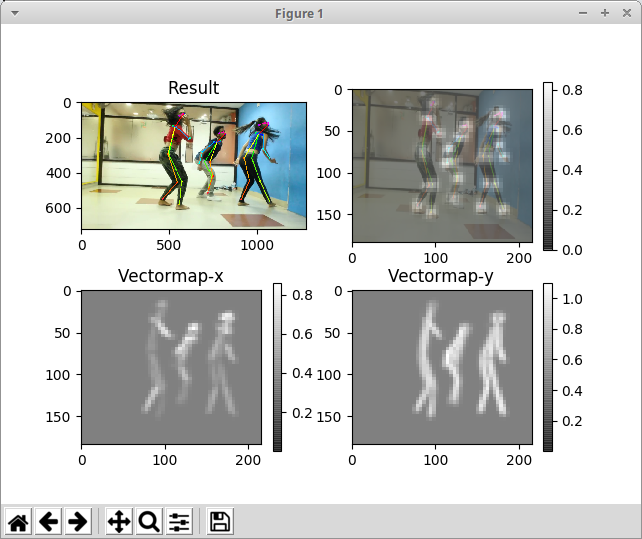
下図の姿勢推定をエッジデバイスでリアルタイムに実行することを目指します。
下図はこの記事の手順で生成された Tensorflow のプロトコルバッファ形式のモデルファイルを使用して実行した例です。
入力画像のサイズが大きいと、表示される骨がかなり細くなります。
MobileNetV2ベースに置き換えているため、モデル全体のサイズが驚異的な小ささになりました。
Tensorflow用 .pbファイルのサイズ = 9.3 MB
OpenVINO用(FP16) .binファイルのサイズ = 4.4 MB
OpenVINO用(FP32) .binファイルのサイズ = 8.8 MB
Tensorflow Lite用(UINT8) .tfliteファイルのサイズ = 2.4 MB
NVIDIA Tesla K80 x4, vCPU x4, MEM 32GB, 64 batch, 10 epochs, 19021 steps
Tensorflow-GPU's Test GTX 1070 FP32 (disabled OpenVINO/Tensorflow Lite)
Youtube: https://youtu.be/LOYc1lMt_84

Tensorflow-CPU's Test Core i7 FP32 (disabled OpenVINO/Tensorflow Lite)
Youtube: https://youtu.be/nEKc7VIm42A

2.Environment
-
Training exam environment
- Ubuntu 16.04 x86_64
- MEM 16 GB
- Geforce GTX 1070
- OpenCV 4.1.0-openvino
- Tensorflow-GPU v1.12.0
- CUDA 9.0
- cuDNN 7.2
-
Training production environment
- GCE
- Ubuntu 16.04 x86_64
- MEM 256 GB
- Tesla K80 x4
- OpenCV 4.1.0-openvino
- Tensorflow-GPU v1.12.0
- CUDA 9.0
- cuDNN 7.2
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 410.104 Driver Version: 410.104 CUDA Version: 10.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 |
| N/A 62C P8 31W / 149W | 16MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 1 Tesla K80 Off | 00000000:00:05.0 Off | 0 |
| N/A 43C P8 27W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 2 Tesla K80 Off | 00000000:00:06.0 Off | 0 |
| N/A 62C P8 33W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
| 3 Tesla K80 Off | 00000000:00:07.0 Off | 0 |
| N/A 72C P8 33W / 149W | 0MiB / 11441MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 1774 G /usr/lib/xorg/Xorg 14MiB |
+-----------------------------------------------------------------------------+
3.Training procedure
$ cd ~
$ git clone https://github.com/ildoonet/tf-pose-estimation.git
$ cd tf-pose-estimation
$ sudo apt-get install -y libcap-dev
$ sudo -H pip3 install python-prctl
$ sudo -H pip3 install setuptools --upgrade
$ sudo -H pip3 install tensorflow-gpu==1.12.0 --upgrade
$ sudo -H pip3 install -r requirements.txt
$ cd tf_pose/pafprocess
$ sudo apt-get install -y swig
$ swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplace
$ cd ../..
$ git clone https://github.com/cocodataset/cocoapi.git
$ cd cocoapi/PythonAPI
$ sudo python3 setup.py build_ext --inplace
$ sudo python3 setup.py build_ext install
$ cd ../..
### Downloads MS-COCO Dataset
$ mkdir dataset;cd dataset
$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1llUu6071hd0QY2DY5vs_7VPaceI7EVst" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1llUu6071hd0QY2DY5vs_7VPaceI7EVst" -o train2017.zip
$ unzip train2017.zip
$ rm train2017.zip
$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1bB8M-WG2LJwmB6YpLMsxUTWwIX3BwYkr" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1bB8M-WG2LJwmB6YpLMsxUTWwIX3BwYkr" -o val2017.zip
$ unzip val2017.zip
$ rm val2017.zip
$ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1P5pir4LVhev_S1Yvu_K3q_hGERAcFpg6" > /dev/null
$ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)"
$ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1P5pir4LVhev_S1Yvu_K3q_hGERAcFpg6" -o annotations_trainval2017.zip
$ unzip annotations_trainval2017.zip
$ rm annotations_trainval2017.zip
$ cd ..
$ mkdir -p models/train
$ mkdir -p models/pretrained/mobilenet_v2_1.4_224;cd models/pretrained/mobilenet_v2_1.4_224
$ wget https://storage.googleapis.com/mobilenet_v2/checkpoints/mobilenet_v2_1.4_224.tgz
$ tar -xzvf mobilenet_v2_1.4_224.tgz;rm mobilenet_v2_1.4_224.tgz
$ cd ../../..
$ mv tf_pose/pose_dataset.py tf_pose/BK_pose_dataset.py
$ mv tf_pose/train.py tf_pose/BK_train.py
$ nano tf_pose/pose_dataset.py
import logging
import math
import multiprocessing
import struct
import sys
import threading
try:
from StringIO import StringIO
except ImportError:
from io import StringIO
from contextlib import contextmanager
import os
import random
import requests
import cv2
import numpy as np
import time
import tensorflow as tf
from tensorpack.dataflow import MultiThreadMapData
from tensorpack.dataflow.image import MapDataComponent
from tensorpack.dataflow.common import BatchData, MapData
from tensorpack.dataflow.parallel import PrefetchData
from tensorpack.dataflow.base import RNGDataFlow, DataFlowTerminated
from pycocotools.coco import COCO
from pose_augment import pose_flip, pose_rotation, pose_to_img, pose_crop_random, \
pose_resize_shortestedge_random, pose_resize_shortestedge_fixed, pose_crop_center, pose_random_scale
from numba import jit
logging.getLogger("requests").setLevel(logging.WARNING)
logger = logging.getLogger('pose_dataset')
logger.setLevel(logging.INFO)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
mplset = False
class CocoMetadata:
# __coco_parts = 57
__coco_parts = 19
__coco_vecs = list(zip(
[2, 9, 10, 2, 12, 13, 2, 3, 4, 3, 2, 6, 7, 6, 2, 1, 1, 15, 16],
[9, 10, 11, 12, 13, 14, 3, 4, 5, 17, 6, 7, 8, 18, 1, 15, 16, 17, 18]
))
@staticmethod
def parse_float(four_np):
assert len(four_np) == 4
return struct.unpack('<f', bytes(four_np))[0]
@staticmethod
def parse_floats(four_nps, adjust=0):
assert len(four_nps) % 4 == 0
return [(CocoMetadata.parse_float(four_nps[x*4:x*4+4]) + adjust) for x in range(len(four_nps) // 4)]
def __init__(self, idx, img_url, img_meta, annotations, sigma):
self.idx = idx
self.img_url = img_url
self.img = None
self.sigma = sigma
self.height = int(img_meta['height'])
self.width = int(img_meta['width'])
joint_list = []
for ann in annotations:
if ann.get('num_keypoints', 0) == 0:
continue
kp = np.array(ann['keypoints'])
xs = kp[0::3]
ys = kp[1::3]
vs = kp[2::3]
joint_list.append([(x, y) if v >= 1 else (-1000, -1000) for x, y, v in zip(xs, ys, vs)])
self.joint_list = []
transform = list(zip(
[1, 6, 7, 9, 11, 6, 8, 10, 13, 15, 17, 12, 14, 16, 3, 2, 5, 4],
[1, 7, 7, 9, 11, 6, 8, 10, 13, 15, 17, 12, 14, 16, 3, 2, 5, 4]
))
for prev_joint in joint_list:
new_joint = []
for idx1, idx2 in transform:
j1 = prev_joint[idx1-1]
j2 = prev_joint[idx2-1]
if j1[0] <= 0 or j1[1] <= 0 or j2[0] <= 0 or j2[1] <= 0:
new_joint.append((-1000, -1000))
else:
new_joint.append(((j1[0] + j2[0]) / 2, (j1[1] + j2[1]) / 2))
new_joint.append((-1000, -1000))
self.joint_list.append(new_joint)
# logger.debug('joint size=%d' % len(self.joint_list))
@jit
def get_heatmap(self, target_size):
heatmap = np.zeros((CocoMetadata.__coco_parts, self.height, self.width), dtype=np.float32)
for joints in self.joint_list:
for idx, point in enumerate(joints):
if point[0] < 0 or point[1] < 0:
continue
CocoMetadata.put_heatmap(heatmap, idx, point, self.sigma)
heatmap = heatmap.transpose((1, 2, 0))
# background
heatmap[:, :, -1] = np.clip(1 - np.amax(heatmap, axis=2), 0.0, 1.0)
if target_size:
heatmap = cv2.resize(heatmap, target_size, interpolation=cv2.INTER_AREA)
return heatmap.astype(np.float16)
@staticmethod
@jit(nopython=True)
def put_heatmap(heatmap, plane_idx, center, sigma):
center_x, center_y = center
_, height, width = heatmap.shape[:3]
th = 4.6052
delta = math.sqrt(th * 2)
x0 = int(max(0, center_x - delta * sigma))
y0 = int(max(0, center_y - delta * sigma))
x1 = int(min(width, center_x + delta * sigma))
y1 = int(min(height, center_y + delta * sigma))
for y in range(y0, y1):
for x in range(x0, x1):
d = (x - center_x) ** 2 + (y - center_y) ** 2
exp = d / 2.0 / sigma / sigma
if exp > th:
continue
heatmap[plane_idx][y][x] = max(heatmap[plane_idx][y][x], math.exp(-exp))
heatmap[plane_idx][y][x] = min(heatmap[plane_idx][y][x], 1.0)
@jit
def get_vectormap(self, target_size):
vectormap = np.zeros((CocoMetadata.__coco_parts*2, self.height, self.width), dtype=np.float32)
countmap = np.zeros((CocoMetadata.__coco_parts, self.height, self.width), dtype=np.int16)
for joints in self.joint_list:
for plane_idx, (j_idx1, j_idx2) in enumerate(CocoMetadata.__coco_vecs):
j_idx1 -= 1
j_idx2 -= 1
center_from = joints[j_idx1]
center_to = joints[j_idx2]
if center_from[0] < -100 or center_from[1] < -100 or center_to[0] < -100 or center_to[1] < -100:
continue
CocoMetadata.put_vectormap(vectormap, countmap, plane_idx, center_from, center_to)
vectormap = vectormap.transpose((1, 2, 0))
nonzeros = np.nonzero(countmap)
for p, y, x in zip(nonzeros[0], nonzeros[1], nonzeros[2]):
if countmap[p][y][x] <= 0:
continue
vectormap[y][x][p*2+0] /= countmap[p][y][x]
vectormap[y][x][p*2+1] /= countmap[p][y][x]
if target_size:
vectormap = cv2.resize(vectormap, target_size, interpolation=cv2.INTER_AREA)
return vectormap.astype(np.float16)
@staticmethod
@jit(nopython=True)
def put_vectormap(vectormap, countmap, plane_idx, center_from, center_to, threshold=8):
_, height, width = vectormap.shape[:3]
vec_x = center_to[0] - center_from[0]
vec_y = center_to[1] - center_from[1]
min_x = max(0, int(min(center_from[0], center_to[0]) - threshold))
min_y = max(0, int(min(center_from[1], center_to[1]) - threshold))
max_x = min(width, int(max(center_from[0], center_to[0]) + threshold))
max_y = min(height, int(max(center_from[1], center_to[1]) + threshold))
norm = math.sqrt(vec_x ** 2 + vec_y ** 2)
if norm == 0:
return
vec_x /= norm
vec_y /= norm
for y in range(min_y, max_y):
for x in range(min_x, max_x):
bec_x = x - center_from[0]
bec_y = y - center_from[1]
dist = abs(bec_x * vec_y - bec_y * vec_x)
if dist > threshold:
continue
countmap[plane_idx][y][x] += 1
vectormap[plane_idx*2+0][y][x] = vec_x
vectormap[plane_idx*2+1][y][x] = vec_y
class CocoPose(RNGDataFlow):
@staticmethod
def display_image(inp, heatmap, vectmap, as_numpy=False):
global mplset
# if as_numpy and not mplset:
# import matplotlib as mpl
# mpl.use('Agg')
mplset = True
import matplotlib.pyplot as plt
fig = plt.figure()
a = fig.add_subplot(2, 2, 1)
a.set_title('Image')
plt.imshow(CocoPose.get_bgimg(inp))
a = fig.add_subplot(2, 2, 2)
a.set_title('Heatmap')
plt.imshow(CocoPose.get_bgimg(inp, target_size=(heatmap.shape[1], heatmap.shape[0])), alpha=0.5)
tmp = np.amax(heatmap, axis=2)
plt.imshow(tmp, cmap=plt.cm.gray, alpha=0.5)
plt.colorbar()
tmp2 = vectmap.transpose((2, 0, 1))
tmp2_odd = np.amax(np.absolute(tmp2[::2, :, :]), axis=0)
tmp2_even = np.amax(np.absolute(tmp2[1::2, :, :]), axis=0)
a = fig.add_subplot(2, 2, 3)
a.set_title('Vectormap-x')
plt.imshow(CocoPose.get_bgimg(inp, target_size=(vectmap.shape[1], vectmap.shape[0])), alpha=0.5)
plt.imshow(tmp2_odd, cmap=plt.cm.gray, alpha=0.5)
plt.colorbar()
a = fig.add_subplot(2, 2, 4)
a.set_title('Vectormap-y')
plt.imshow(CocoPose.get_bgimg(inp, target_size=(vectmap.shape[1], vectmap.shape[0])), alpha=0.5)
plt.imshow(tmp2_even, cmap=plt.cm.gray, alpha=0.5)
plt.colorbar()
if not as_numpy:
plt.show()
else:
fig.canvas.draw()
data = np.fromstring(fig.canvas.tostring_rgb(), dtype=np.uint8, sep='')
data = data.reshape(fig.canvas.get_width_height()[::-1] + (3,))
fig.clear()
plt.close()
return data
@staticmethod
def get_bgimg(inp, target_size=None):
inp = cv2.cvtColor(inp.astype(np.uint8), cv2.COLOR_BGR2RGB)
if target_size:
inp = cv2.resize(inp, target_size, interpolation=cv2.INTER_AREA)
return inp
def __init__(self, path, img_path=None, is_train=True, decode_img=True, only_idx=-1):
self.is_train = is_train
self.decode_img = decode_img
self.only_idx = only_idx
if is_train:
whole_path = os.path.join(path, 'person_keypoints_train2017.json')
else:
whole_path = os.path.join(path, 'person_keypoints_val2017.json')
self.img_path = (img_path if img_path is not None else '') + ('train2017/' if is_train else 'val2017/')
self.coco = COCO(whole_path)
logger.info('%s dataset %d' % (path, self.size()))
def size(self):
return len(self.coco.imgs)
def get_data(self):
idxs = np.arange(self.size())
if self.is_train:
self.rng.shuffle(idxs)
else:
pass
keys = list(self.coco.imgs.keys())
for idx in idxs:
img_meta = self.coco.imgs[keys[idx]]
img_idx = img_meta['id']
ann_idx = self.coco.getAnnIds(imgIds=img_idx)
if 'http://' in self.img_path:
img_url = self.img_path + img_meta['file_name']
else:
img_url = os.path.join(self.img_path, img_meta['file_name'])
anns = self.coco.loadAnns(ann_idx)
meta = CocoMetadata(idx, img_url, img_meta, anns, sigma=8.0)
total_keypoints = sum([ann.get('num_keypoints', 0) for ann in anns])
if total_keypoints == 0 and random.uniform(0, 1) > 0.2:
continue
yield [meta]
class MPIIPose(RNGDataFlow):
def __init__(self):
pass
def size(self):
pass
def get_data(self):
pass
def read_image_url(metas):
for meta in metas:
img_str = None
if 'http://' in meta.img_url:
# print(meta.img_url)
for _ in range(10):
try:
resp = requests.get(meta.img_url)
if resp.status_code // 100 != 2:
logger.warning('request failed code=%d url=%s' % (resp.status_code, meta.img_url))
time.sleep(1.0)
continue
img_str = resp.content
break
except Exception as e:
logger.warning('request failed url=%s, err=%s' % (meta.img_url, str(e)))
else:
img_str = open(meta.img_url, 'rb').read()
if not img_str:
logger.warning('image not read, path=%s' % meta.img_url)
raise Exception()
nparr = np.fromstring(img_str, np.uint8)
meta.img = cv2.imdecode(nparr, cv2.IMREAD_COLOR)
return metas
def get_dataflow(path, is_train, img_path=None):
ds = CocoPose(path, img_path, is_train) # read data from lmdb
if is_train:
ds = MapData(ds, read_image_url)
ds = MapDataComponent(ds, pose_random_scale)
ds = MapDataComponent(ds, pose_rotation)
ds = MapDataComponent(ds, pose_flip)
ds = MapDataComponent(ds, pose_resize_shortestedge_random)
ds = MapDataComponent(ds, pose_crop_random)
ds = MapData(ds, pose_to_img)
# augs = [
# imgaug.RandomApplyAug(imgaug.RandomChooseAug([
# imgaug.GaussianBlur(max_size=3)
# ]), 0.7)
# ]
# ds = AugmentImageComponent(ds, augs)
ds = PrefetchData(ds, 1000, multiprocessing.cpu_count() * 1)
else:
ds = MultiThreadMapData(ds, nr_thread=16, map_func=read_image_url, buffer_size=1000)
ds = MapDataComponent(ds, pose_resize_shortestedge_fixed)
ds = MapDataComponent(ds, pose_crop_center)
ds = MapData(ds, pose_to_img)
ds = PrefetchData(ds, 100, multiprocessing.cpu_count() // 4)
return ds
def _get_dataflow_onlyread(path, is_train, img_path=None):
ds = CocoPose(path, img_path, is_train) # read data from lmdb
ds = MapData(ds, read_image_url)
ds = MapData(ds, pose_to_img)
# ds = PrefetchData(ds, 1000, multiprocessing.cpu_count() * 4)
return ds
def get_dataflow_batch(path, is_train, batchsize, img_path=None):
logger.info('dataflow img_path=%s' % img_path)
ds = get_dataflow(path, is_train, img_path=img_path)
ds = BatchData(ds, batchsize)
# if is_train:
# ds = PrefetchData(ds, 10, 2)
# else:
# ds = PrefetchData(ds, 50, 2)
return ds
class DataFlowToQueue(threading.Thread):
def __init__(self, ds, placeholders, queue_size=5):
super().__init__()
self.daemon = True
self.ds = ds
self.placeholders = placeholders
self.queue = tf.FIFOQueue(queue_size, [ph.dtype for ph in placeholders], shapes=[ph.get_shape() for ph in placeholders])
self.op = self.queue.enqueue(placeholders)
self.close_op = self.queue.close(cancel_pending_enqueues=True)
self._coord = None
self._sess = None
self.last_dp = None
@contextmanager
def default_sess(self):
if self._sess:
with self._sess.as_default():
yield
else:
logger.warning("DataFlowToQueue {} wasn't under a default session!".format(self.name))
yield
def size(self):
return self.queue.size()
def start(self):
self._sess = tf.get_default_session()
super().start()
def set_coordinator(self, coord):
self._coord = coord
def run(self):
with self.default_sess():
try:
while not self._coord.should_stop():
try:
self.ds.reset_state()
while True:
for dp in self.ds.get_data():
feed = dict(zip(self.placeholders, dp))
self.op.run(feed_dict=feed)
self.last_dp = dp
except (tf.errors.CancelledError, tf.errors.OutOfRangeError, DataFlowTerminated):
logger.error('err type1, placeholders={}'.format(self.placeholders))
sys.exit(-1)
except Exception as e:
logger.error('err type2, err={}, placeholders={}'.format(str(e), self.placeholders))
if isinstance(e, RuntimeError) and 'closed Session' in str(e):
pass
else:
logger.exception("Exception in {}:{}".format(self.name, str(e)))
sys.exit(-1)
except Exception as e:
logger.exception("Exception in {}:{}".format(self.name, str(e)))
finally:
try:
self.close_op.run()
except Exception:
pass
logger.info("{} Exited.".format(self.name))
def dequeue(self):
return self.queue.dequeue()
if __name__ == '__main__':
os.environ['CUDA_VISIBLE_DEVICES'] = ''
from pose_augment import set_network_input_wh, set_network_scale
# set_network_input_wh(368, 368)
set_network_input_wh(432, 368)
set_network_scale(8)
# df = get_dataflow('/data/public/rw/coco/annotations', True, '/data/public/rw/coco/')
df = _get_dataflow_onlyread('dataset/annotations', True, 'dataset/')
# df = get_dataflow('/root/coco/annotations', False, img_path='http://gpu-twg.kakaocdn.net/braincloud/COCO/')
from tensorpack.dataflow.common import TestDataSpeed
TestDataSpeed(df).start()
sys.exit(0)
with tf.Session() as sess:
df.reset_state()
t1 = time.time()
for idx, dp in enumerate(df.get_data()):
if idx == 0:
for d in dp:
logger.info('%d dp shape={}'.format(d.shape))
print(time.time() - t1)
t1 = time.time()
CocoPose.display_image(dp[0], dp[1].astype(np.float32), dp[2].astype(np.float32))
print(dp[1].shape, dp[2].shape)
pass
logger.info('done')
$ nano tf_pose/train.py
import matplotlib as mpl
mpl.use('Agg') # training mode, no screen should be open. (It will block training loop)
import argparse
import logging
import os
import time
import cv2
import numpy as np
import tensorflow as tf
from tqdm import tqdm
from pose_dataset import get_dataflow_batch, DataFlowToQueue, CocoPose
from pose_augment import set_network_input_wh, set_network_scale
from common import get_sample_images
from networks import get_network
logger = logging.getLogger('train')
logger.handlers.clear()
logger.setLevel(logging.DEBUG)
ch = logging.StreamHandler()
ch.setLevel(logging.DEBUG)
formatter = logging.Formatter('[%(asctime)s] [%(name)s] [%(levelname)s] %(message)s')
ch.setFormatter(formatter)
logger.addHandler(ch)
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Training codes for Openpose using Tensorflow')
parser.add_argument('--model', default='mobilenet_v2_1.4', help='model name')
parser.add_argument('--datapath', type=str, default='/data/public/rw/coco/annotations')
parser.add_argument('--imgpath', type=str, default='/data/public/rw/coco/')
parser.add_argument('--batchsize', type=int, default=64)
parser.add_argument('--gpus', type=int, default=4)
parser.add_argument('--max-epoch', type=int, default=600)
parser.add_argument('--lr', type=str, default='0.001')
parser.add_argument('--tag', type=str, default='test')
parser.add_argument('--checkpoint', type=str, default='')
parser.add_argument('--input-width', type=int, default=432)
parser.add_argument('--input-height', type=int, default=368)
parser.add_argument('--quant-delay', type=int, default=-1)
args = parser.parse_args()
modelpath = logpath = './models/train/'
if args.gpus <= 0:
raise Exception('gpus <= 0')
# define input placeholder
set_network_input_wh(args.input_width, args.input_height)
scale = 4
if args.model in ['cmu', 'vgg'] or 'mobilenet' in args.model:
scale = 8
set_network_scale(scale)
output_w, output_h = args.input_width // scale, args.input_height // scale
logger.info('define model+')
with tf.device(tf.DeviceSpec(device_type="CPU")):
input_node = tf.placeholder(tf.float32, shape=(args.batchsize, args.input_height, args.input_width, 3), name='image')
vectmap_node = tf.placeholder(tf.float32, shape=(args.batchsize, output_h, output_w, 38), name='vectmap')
heatmap_node = tf.placeholder(tf.float32, shape=(args.batchsize, output_h, output_w, 19), name='heatmap')
# prepare data
df = get_dataflow_batch(args.datapath, True, args.batchsize, img_path=args.imgpath)
enqueuer = DataFlowToQueue(df, [input_node, heatmap_node, vectmap_node], queue_size=100)
q_inp, q_heat, q_vect = enqueuer.dequeue()
df_valid = get_dataflow_batch(args.datapath, False, args.batchsize, img_path=args.imgpath)
df_valid.reset_state()
validation_cache = []
val_image = get_sample_images(args.input_width, args.input_height)
logger.debug('tensorboard val image: %d' % len(val_image))
logger.debug(q_inp)
logger.debug(q_heat)
logger.debug(q_vect)
# define model for multi-gpu
q_inp_split, q_heat_split, q_vect_split = tf.split(q_inp, args.gpus), tf.split(q_heat, args.gpus), tf.split(q_vect, args.gpus)
output_vectmap = []
output_heatmap = []
losses = []
last_losses_l1 = []
last_losses_l2 = []
outputs = []
for gpu_id in range(args.gpus):
with tf.device(tf.DeviceSpec(device_type="GPU", device_index=gpu_id)):
with tf.variable_scope(tf.get_variable_scope(), reuse=(gpu_id > 0)):
net, pretrain_path, last_layer = get_network(args.model, q_inp_split[gpu_id])
if args.checkpoint:
pretrain_path = args.checkpoint
vect, heat = net.loss_last()
output_vectmap.append(vect)
output_heatmap.append(heat)
outputs.append(net.get_output())
l1s, l2s = net.loss_l1_l2()
for idx, (l1, l2) in enumerate(zip(l1s, l2s)):
loss_l1 = tf.nn.l2_loss(tf.concat(l1, axis=0) - q_vect_split[gpu_id], name='loss_l1_stage%d_tower%d' % (idx, gpu_id))
loss_l2 = tf.nn.l2_loss(tf.concat(l2, axis=0) - q_heat_split[gpu_id], name='loss_l2_stage%d_tower%d' % (idx, gpu_id))
losses.append(tf.reduce_mean([loss_l1, loss_l2]))
last_losses_l1.append(loss_l1)
last_losses_l2.append(loss_l2)
outputs = tf.concat(outputs, axis=0)
with tf.device(tf.DeviceSpec(device_type="GPU")):
# define loss
total_loss = tf.reduce_sum(losses) / args.batchsize
total_loss_ll_paf = tf.reduce_sum(last_losses_l1) / args.batchsize
total_loss_ll_heat = tf.reduce_sum(last_losses_l2) / args.batchsize
total_loss_ll = tf.reduce_sum([total_loss_ll_paf, total_loss_ll_heat])
# define optimizer
step_per_epoch = 121745 // args.batchsize
global_step = tf.Variable(0, trainable=False)
if ',' not in args.lr:
starter_learning_rate = float(args.lr)
# learning_rate = tf.train.exponential_decay(starter_learning_rate, global_step,
# decay_steps=10000, decay_rate=0.33, staircase=True)
learning_rate = tf.train.cosine_decay(starter_learning_rate, global_step, args.max_epoch * step_per_epoch, alpha=0.0)
else:
lrs = [float(x) for x in args.lr.split(',')]
boundaries = [step_per_epoch * 5 * i for i, _ in range(len(lrs)) if i > 0]
learning_rate = tf.train.piecewise_constant(global_step, boundaries, lrs)
if args.quant_delay >= 0:
logger.info('train using quantized mode, delay=%d' % args.quant_delay)
g = tf.get_default_graph()
tf.contrib.quantize.create_training_graph(input_graph=g, quant_delay=args.quant_delay)
# optimizer = tf.train.RMSPropOptimizer(learning_rate, decay=0.0005, momentum=0.9, epsilon=1e-10)
optimizer = tf.train.AdamOptimizer(learning_rate, epsilon=1e-8)
# optimizer = tf.train.MomentumOptimizer(learning_rate, momentum=0.8, use_locking=True, use_nesterov=True)
update_ops = tf.get_collection(tf.GraphKeys.UPDATE_OPS)
with tf.control_dependencies(update_ops):
train_op = optimizer.minimize(total_loss, global_step, colocate_gradients_with_ops=True)
logger.info('define model-')
# define summary
tf.summary.scalar("loss", total_loss)
tf.summary.scalar("loss_lastlayer", total_loss_ll)
tf.summary.scalar("loss_lastlayer_paf", total_loss_ll_paf)
tf.summary.scalar("loss_lastlayer_heat", total_loss_ll_heat)
tf.summary.scalar("queue_size", enqueuer.size())
tf.summary.scalar("lr", learning_rate)
merged_summary_op = tf.summary.merge_all()
valid_loss = tf.placeholder(tf.float32, shape=[])
valid_loss_ll = tf.placeholder(tf.float32, shape=[])
valid_loss_ll_paf = tf.placeholder(tf.float32, shape=[])
valid_loss_ll_heat = tf.placeholder(tf.float32, shape=[])
sample_train = tf.placeholder(tf.float32, shape=(4, 640, 640, 3))
sample_valid = tf.placeholder(tf.float32, shape=(12, 640, 640, 3))
train_img = tf.summary.image('training sample', sample_train, 4)
valid_img = tf.summary.image('validation sample', sample_valid, 12)
valid_loss_t = tf.summary.scalar("loss_valid", valid_loss)
valid_loss_ll_t = tf.summary.scalar("loss_valid_lastlayer", valid_loss_ll)
merged_validate_op = tf.summary.merge([train_img, valid_img, valid_loss_t, valid_loss_ll_t])
saver = tf.train.Saver(max_to_keep=1000)
config = tf.ConfigProto(allow_soft_placement=True, log_device_placement=False)
config.gpu_options.allow_growth = True
with tf.Session(config=config) as sess:
logger.info('model weights initialization')
sess.run(tf.global_variables_initializer())
if args.checkpoint and os.path.isdir(args.checkpoint):
logger.info('Restore from checkpoint...')
# loader = tf.train.Saver(net.restorable_variables())
# loader.restore(sess, tf.train.latest_checkpoint(args.checkpoint))
saver.restore(sess, tf.train.latest_checkpoint(args.checkpoint))
logger.info('Restore from checkpoint...Done')
elif pretrain_path:
logger.info('Restore pretrained weights... %s' % pretrain_path)
if '.npy' in pretrain_path:
net.load(pretrain_path, sess, False)
else:
try:
loader = tf.train.Saver(net.restorable_variables(only_backbone=False))
loader.restore(sess, pretrain_path)
except:
logger.info('Restore only weights in backbone layers.')
loader = tf.train.Saver(net.restorable_variables())
loader.restore(sess, pretrain_path)
logger.info('Restore pretrained weights...Done')
logger.info('prepare file writer')
file_writer = tf.summary.FileWriter(os.path.join(logpath, args.tag), sess.graph)
logger.info('prepare coordinator')
coord = tf.train.Coordinator()
enqueuer.set_coordinator(coord)
enqueuer.start()
logger.info('Training Started.')
time_started = time.time()
last_gs_num = last_gs_num2 = 0
initial_gs_num = sess.run(global_step)
last_log_epoch1 = last_log_epoch2 = -1
while True:
_, gs_num = sess.run([train_op, global_step])
curr_epoch = float(gs_num) / step_per_epoch
if gs_num > step_per_epoch * args.max_epoch:
break
if gs_num - last_gs_num >= 500:
train_loss, train_loss_ll, train_loss_ll_paf, train_loss_ll_heat, lr_val, summary = sess.run([total_loss, total_loss_ll, total_loss_ll_paf, total_loss_ll_heat, learning_rate, merged_summary_op])
# log of training loss / accuracy
batch_per_sec = (gs_num - initial_gs_num) / (time.time() - time_started)
logger.info('epoch=%.2f step=%d, %0.4f examples/sec lr=%f, loss=%g, loss_ll=%g, loss_ll_paf=%g, loss_ll_heat=%g' % (gs_num / step_per_epoch, gs_num, batch_per_sec * args.batchsize, lr_val, train_loss, train_loss_ll, train_loss_ll_paf, train_loss_ll_heat))
last_gs_num = gs_num
if last_log_epoch1 < curr_epoch:
file_writer.add_summary(summary, curr_epoch)
last_log_epoch1 = curr_epoch
if gs_num - last_gs_num2 >= 2000:
# save weights
saver.save(sess, os.path.join(modelpath, args.tag, 'model_latest'), global_step=global_step)
average_loss = average_loss_ll = average_loss_ll_paf = average_loss_ll_heat = 0
total_cnt = 0
if len(validation_cache) == 0:
for images_test, heatmaps, vectmaps in tqdm(df_valid.get_data()):
validation_cache.append((images_test, heatmaps, vectmaps))
df_valid.reset_state()
del df_valid
df_valid = None
# log of test accuracy
for images_test, heatmaps, vectmaps in validation_cache:
lss, lss_ll, lss_ll_paf, lss_ll_heat, vectmap_sample, heatmap_sample = sess.run(
[total_loss, total_loss_ll, total_loss_ll_paf, total_loss_ll_heat, output_vectmap, output_heatmap],
feed_dict={q_inp: images_test, q_vect: vectmaps, q_heat: heatmaps}
)
average_loss += lss * len(images_test)
average_loss_ll += lss_ll * len(images_test)
average_loss_ll_paf += lss_ll_paf * len(images_test)
average_loss_ll_heat += lss_ll_heat * len(images_test)
total_cnt += len(images_test)
logger.info('validation(%d) %s loss=%f, loss_ll=%f, loss_ll_paf=%f, loss_ll_heat=%f' % (total_cnt, args.tag, average_loss / total_cnt, average_loss_ll / total_cnt, average_loss_ll_paf / total_cnt, average_loss_ll_heat / total_cnt))
last_gs_num2 = gs_num
#sample_image = [enqueuer.last_dp[0][i] for i in range(4)]
#outputMat = sess.run(
# outputs,
# feed_dict={q_inp: np.array((sample_image + val_image) * max(1, (args.batchsize // 16)))}
#)
#pafMat, heatMat = outputMat[:, :, :, 19:], outputMat[:, :, :, :19]
#
#sample_results = []
#for i in range(len(sample_image)):
# test_result = CocoPose.display_image(sample_image[i], heatMat[i], pafMat[i], as_numpy=True)
# test_result = cv2.resize(test_result, (640, 640))
# test_result = test_result.reshape([640, 640, 3]).astype(float)
# sample_results.append(test_result)
#
#test_results = []
#for i in range(len(val_image)):
# test_result = CocoPose.display_image(val_image[i], heatMat[len(sample_image) + i], pafMat[len(sample_image) + i], as_numpy=True)
# test_result = cv2.resize(test_result, (640, 640))
# test_result = test_result.reshape([640, 640, 3]).astype(float)
# test_results.append(test_result)
# save summary
#summary = sess.run(merged_validate_op, feed_dict={
# valid_loss: average_loss / total_cnt,
# valid_loss_ll: average_loss_ll / total_cnt,
# valid_loss_ll_paf: average_loss_ll_paf / total_cnt,
# valid_loss_ll_heat: average_loss_ll_heat / total_cnt,
# sample_valid: test_results,
# sample_train: sample_results
#})
if last_log_epoch2 < curr_epoch:
#file_writer.add_summary(summary, curr_epoch)
last_log_epoch2 = curr_epoch
saver.save(sess, os.path.join(modelpath, args.tag, 'model'), global_step=global_step)
logger.info('optimization finished. %f' % (time.time() - time_started))
$ python3 tf_pose/train.py \
--model=mobilenet_v2_1.4 \
--datapath=dataset/annotations/ \
--imgpath=dataset/ \
--batchsize=2 \
--gpus=1 \
--max-epoch=5 \
--lr=0.001
$ python3 tf_pose/train.py \
--model=mobilenet_v2_1.4 \
--datapath=dataset/annotations/ \
--imgpath=dataset/ \
--batchsize=64 \
--gpus=4 \
--max-epoch=5 \
--lr=0.001
$ python3 tf_pose/train.py \
--model=mobilenet_v2_1.4 \
--datapath=dataset/annotations/ \
--imgpath=dataset/ \
--batchsize=2 \
--gpus=1 \
--max-epoch=5 \
--lr=0.001 \
--quant-delay=180000
$ python3 tf_pose/train.py \
--model=mobilenet_v2_1.4 \
--datapath=dataset/annotations/ \
--imgpath=dataset/ \
--batchsize=4 \
--gpus=1 \
--max-epoch=10 \
--lr=0.001 \
--quant-delay=180000
$ nano model_compression.py
import tensorflow as tf
from tf_pose.networks import get_network
#######################################################################################
### $ python3 model_compression.py
#######################################################################################
def main():
graph = tf.Graph()
with graph.as_default():
input_node = tf.placeholder(tf.float32, shape=(1, 368, 432, 3), name='image')
net, pretrain_path, last_layer = get_network("mobilenet_v2_1.4", input_node, None, False)
saver = tf.train.Saver(tf.global_variables())
sess = tf.Session()
sess.run(tf.global_variables_initializer())
sess.run(tf.local_variables_initializer())
saver.restore(sess, 'models/train/test/model-19021')
saver.save(sess, 'models/train/test/model-final-19021')
graphdef = graph.as_graph_def()
tf.train.write_graph(graphdef, 'models/train/test', 'model-final.pbtxt', as_text=True)
if __name__ == '__main__':
main()
$ sed -i s/"(slim.batch_norm,): {'center': True, 'scale': True},"/"(slim.batch_norm,): {'center': True, 'scale': True, 'is_training': False},"/ tf_pose/mobilenet/mobilenet_v2.py
$ python3 model_compression.py
$ sed -i s/"(slim.batch_norm,): {'center': True, 'scale': True, 'is_training': False},"/"(slim.batch_norm,): {'center': True, 'scale': True},"/ tf_pose/mobilenet/mobilenet_v2.py
$ python3 freeze_graph.py \
--input_graph=models/train/test/model-final.pbtxt \
--input_checkpoint=models/train/test/model-final-19021 \
--output_graph=models/train/test/frozen-model.pb \
--output_node_names=Openpose/concat_stage7 \
--input_binary=False \
--clear_devices=True

$ cd ..
$ git clone https://github.com/PINTO0309/Bazel_bin.git
$ Bazel_bin/0.19.2/Ubuntu1604_x86_64/install.sh
$ git clone -b v1.12.0 https://github.com/tensorflow/tensorflow.git
$ cd tensorflow
$ git checkout -b v1.12.0
$ sudo bazel build tensorflow/tools/graph_transforms:transform_graph
$ bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=../tf-pose-estimation/models/train/test/frozen-model.pb \
--out_graph=../tf-pose-estimation/models/train/test/frozen-opt-model.pb \
--inputs='image' \
--outputs='Openpose/concat_stage7' \
--transforms='strip_unused_nodes(type=float, shape="1,368,432,3")
fold_old_batch_norms
fold_batch_norms
fold_constants(ignoreError=False)
remove_nodes(op=Identity, op=CheckNumerics)'

$ cd ~/tf-pose-estimation
$ mkdir -p models/train/test/tflite
$ tflite_convert \
--output_file="models/train/test/tflite/output_tflite_graph.tflite" \
--graph_def_file="models/train/test/frozen-model.pb" \
--inference_type=QUANTIZED_UINT8 \
--input_arrays="image" \
--output_arrays="Openpose/concat_stage7" \
--mean_values=128 \
--std_dev_values=128 \
--default_ranges_min=0 \
--default_ranges_max=6 \
--input_shapes=1,368,432,3 \
--change_concat_input_ranges=false \
--allow_nudging_weights_to_use_fast_gemm_kernel=true
or
$ cd ~/tf-pose-estimation
$ mkdir -p models/train/test/tflite
$ toco \
--graph_def_file=models/train/test/frozen-model.pb \
--output_file=models/train/test/tflite/output_tflite_graph.tflite \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TFLITE \
--inference_type=QUANTIZED_UINT8 \
--input_shapes="1,368,432,3" \
--input_array=image \
--output_array=Openpose/concat_stage7 \
--std_dev_values=127.5 \
--mean_values=127.5 \
--default_ranges_min=0 \
--default_ranges_max=6 \
--post_training_quantize
or
$ cd ~/tensorflow
$ bazel-bin/tensorflow/tools/graph_transforms/transform_graph \
--in_graph=../tf-pose-estimation/models/train/test/frozen-model.pb \
--out_graph=../tf-pose-estimation/models/train/test/frozen-quant-model.pb \
--inputs='image' \
--outputs='Openpose/concat_stage7' \
--transforms='quantize_weights quantize_nodes'
$ cd ../tf-pose-estimation
$ mkdir -p models/train/test/openvino/FP16
$ sudo python3 /opt/intel/openvino/deployment_tools/model_optimizer/mo_tf.py \
--input_model models/train/test/frozen-model.pb \
--output_dir models/train/test/openvino/FP16 \
--data_type FP16 \
--input_shape [1,368,432,3]
$ mkdir -p models/train/test/openvino/FP32
$ sudo python3 /opt/intel/openvino/deployment_tools/model_optimizer/mo_tf.py \
--input_model models/train/test/frozen-model.pb \
--output_dir models/train/test/openvino/FP32 \
--data_type FP32 \
--input_shape [1,368,432,3]
4.Finally
次回は、OpenVINO と Tensorflow Lite による USB Camera のリアルタイム動作の検証を行います。
モデルのサイズがかなり小さくなりましたので、動作確認をする前からそこそこ早く動作しそうな予感がしています。
5.Reference articles
https://coral.withgoogle.com/web-compiler/
https://github.com/tensorflow/tensorflow/tree/r1.13/tensorflow/contrib/quantize#quantization-aware-training
https://github.com/tensorflow/tensorflow/issues/20867
https://github.com/tensorflow/models/blob/master/research/object_detection/export_tflite_ssd_graph.py
https://github.com/tensorflow/models/blob/master/research/object_detection/export_tflite_ssd_graph_lib.py
https://github.com/tensorflow/models/blob/master/research/object_detection/builders/graph_rewriter_builder.py
https://github.com/tensorflow/models/blob/master/research/object_detection/exporter.py
https://github.com/ildoonet/tf-pose-estimation/blob/master/etcs/training.md
https://github.com/ildoonet/tf-pose-estimation/blob/master/etcs/experiments.md
https://github.com/tensorflow/tensorflow/issues/24477
https://github.com/tensorflow/tensorflow/blob/r1.13/tensorflow/contrib/quantize/python/quantize_graph.py
TensorFlowで学習してモデルファイルを小さくしてコマンドラインアプリを作るシンプルな流れ
http://tensorflow.classcat.com/2019/01/20/cc-tf-onnx-hub-person-pose-estimation/
https://tech-blog.optim.co.jp/entry/2018/12/03/162348
https://www.tensorflow.org/lite/models/pose_estimation/overview
https://github.com/ildoonet/tf-pose-estimation/issues/132
https://github.com/ildoonet/tf-pose-estimation/issues/174
Linuxでコマンドラインからマシンスペックを確認する方法
https://github.com/tensorflow/tensorflow/tree/r1.13/tensorflow/contrib/quantize
https://github.com/tensorflow/models/tree/master/research/slim/nets/mobilenet
https://www.tensorflow.org/api_docs/python/tf/contrib/quantize/create_training_graph