概要
- chainer標準のEvaluatorを継承して,Evaluator関数を自作しました
- 分類タスク時の,epoch毎の学習結果をConfusionMatrixにし,適合率, 再現率を算出する評価関数を作成しました
下記の様な出力がされ, cmrecall, cmaccuracyが適合率と再現率を表しています。
epoch main/loss main/accuracy elapsed_time cmrecall cmaccuracy
1 11.7993 0.616536 205.322 0.991 0.648
2 0.608019 0.652384 403.316 0.975 0.668
3 0.518719 0.707642 602.897 0.941 0.91
.
.
.
Confusion Matrix
ConfusionMatrixの説明は,以下のページがわかりやすいです。
ConfusionMatrixとは,クラス分類の結果をまとめた表のことです。
作成した識別器の,誤識別の傾向を見たいときに参考になります。取りこぼしが多いのか,それとも誤認識が多いのか。
例えば,製品の傷の有無を調べるといった異常検知タスクだと,
誤認識の種類
1. 傷がついているけれど, スルーしてしまう
2. 傷がついていないけれど, 傷がついていると判定してしまう
といったことが考えられます。この場合だと,1をなくすことが重要なのではないかと考えます。この様に,タスクによってどちらを優先して減らすべきかが変わってくるのでこういった指標を取り入れることは重要です。
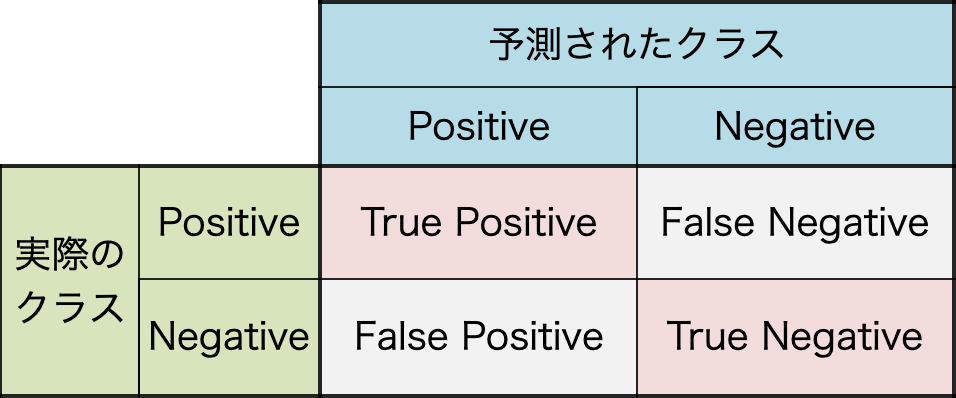
再現率
先の例で言うと,実際に傷があったものの内,正しく傷があったと判定した割合になります。
\frac{TP}{TP + FN}
適合率
こちらも同じく先の例で言うと,傷があると予測したものの内,正しく傷があった割合になります。
\frac{TP}{TP + FP}
使い方
以下のように,通常の拡張機能を追加する様に書いていただければ適合率, 再現率を算出することができます。
再現率,適合率のログを追加
trainer.extend(CMEvaluator(valid_iter, model, device=gpu_id))
標準出力に再現率,適合率を表示
trainer.extend(extensions.PrintReport( entries=['epoch', 'main/loss', 'main/accuracy', 'elapsed_time', 'cmrecall', 'cmaccuracy' ]))
実装
chainer標準のEvaluatorを継承して以下のEvaluator関数を自作しました。
CMEvaluator.py
import chainer
from chainer import reporter as reporter_module
from chainer.training import extensions
from chainer import function
import numpy as np
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report, precision_score, recall_score
class CMEvaluator(extensions.Evaluator):
"""
Confusion Matrixで再現率、適合率を算出するEvaluator
"""
default_name="mycm"
def evaluate(self):
# iterator, modelを設定
iterator = self._iterators['main']
model = self._targets['main']
# 別で行う関数があるなら設定
eval_func = self.eval_func or model
if self.eval_hook:
self.eval_hook(self)
if hasattr(iterator, 'reset'):
iterator.reset()
it = iterator
else:
it = copy.copy(iterator)
summary = reporter_module.DictSummary()
recall_count = 0
accuracy_count = 0
lcount = 0
for i, batch in enumerate(it):
observation = {}
with reporter_module.report_scope(observation):
in_arrays = self.converter(batch, self.device)
with function.no_backprop_mode():
if isinstance(in_arrays, tuple):
eval_func(*in_arrays)
re, ac = self.cm(in_arrays)
elif isinstance(in_arrays, dict):
eval_func(**in_arrays)
re, ac = self.cm(in_arrays)
else:
eval_func(in_arrays)
re, ac = self.cm(in_arrays)
recall_count = recall_count + re
accuracy_count = accuracy_count + ac
summary.add(observation)
lcount = i
cm_observation = {}
cm_observation["cmrecall"] = round(recall_count / (lcount + 1) ,3)
cm_observation["cmaccuracy"] = round(accuracy_count / (lcount + 1), 3)
# print(cm_observation)
# print(summary.compute_mean())
summary.add(cm_observation)
return summary.compute_mean()
def cm(self, in_arrays):
model = self._targets['main']
_, labels = in_arrays
if self.device >= 0:
labels = chainer.cuda.to_cpu(labels)
y = model.y.data
if self.device >= 0:
y = chainer.cuda.to_cpu(y)
y = y.argmax(axis=1)
cmatrix = np.zeros((2,2))
cmatrix = np.array(confusion_matrix(labels,y))
# print(cmatrix)
recall = round(cmatrix[0,0] / (cmatrix[0,0] + cmatrix[0,1]), 3)
accuracy = round(cmatrix[0,0] / (cmatrix[0,0] + cmatrix[1,0]),3)
return recall, accuracy