fluentdやらkinesis firehoseやらELKやらathenaやら、いろいろ考えてるとややこしくなってきました。
例えば、新規にaws上にサービスを構築するとして、あまり作りこむこともなく、お金をかけることもなく、って場合にどれがいいのやら。
そういうのを考えながらやってみるエントリでございます。
前提
- elb配下でec2がauto scaling構成で稼働している
- ec2はステートレス
- ec2上でapacheが稼働している
要件
- apacheのログを自動で集約したい
- ログはDLせずにクラウド上で調査したい
- 導入は1~2時間くらいで
- コストは最小限
- 拡張性もほしい
- ログが複数行にわたる場合にも対応したい
構成検討
構成としてはec2に何らかのエージェントを入れて、そこからpushする方式とします。
エージェントとして検討するのは、
- fluentd
- kinesis agent
- CloudWatch Logs agent
- logstash
の4つのエージェントとしました。
fluentdはトレジャーデータ社が開発したデータ収集ミドルウェアでプラグインも豊富で拡張性もある。
logstashはelastic社が開発したデータ収集ミドルウェアで、elastic search、kibanaを合わせて使う構成がELKと呼ばれていて一般的だったりする。
上記二つはどちらもrubyにスクリプトです。
kinesis agent、CloudWatch Logs agentはawsのツールで、前者はjava、後者はpythonみたいです。
次に検討したいものとしてはデータの保存方法。これによってエージェントも絞れそうです。
- (とりあえず)S3
- Elastic search
- redshift
他にも考えれるとは思いますがとりあえず。
ただ、コストはなるべく抑えるという要件がありまして、そうなるとec2インスタンスやらDBインスタンスやらを用いるようなサーバータイプのものは消したいです。
つまり(とりあえず)S3にしたいです。
S3に入れておけばAthenaで調査ができたりQuickSightで可視化ができるかなと思います。
Athenaだとクエリーで課金なのは少し気になりますが、S3のライフサイクルポリシー設定や、ログの圧縮、glueを使って形式変換(json -> parquet)とかやるとほぼ気にならない程度になるのではないでしょうか。
そんなわけでagentに戻ります。
kinesis firehoseとかを使う事も考えてたんだけど、これは使わなくても良さそうかな。
kinesis agent外しときましょう。極力、シンプルにする。
CloudWatchLogsは、cloudwatchに出力した後にs3にエクスポートという事はできそうなのですが、基本的にはcloudwatchに出力するためのツールでしょうか。これはこれで便利だと思うけど、ちょっと方向性が違うので外しましょう。
fluentdかlogstashか。
jsonに変換できてS3に保存できればどちらでもよいのだけど、elastic searchに流すのが本筋なlogstashに比べて、多用途に作られてるfluentdの方が扱いやすそうには思える。
fluent/fluent-plugin-s3:
https://github.com/fluent/fluent-plugin-s3
S3 output plugin:
https://www.elastic.co/guide/en/logstash/current/plugins-outputs-s3.html
というわけで、
fluentd + S3 + aws Athenaにしようと思います。
fluentd インストール
https://docs.fluentd.org/v1.0/articles/before-install
/etc/security/limits.confとか編集します
そして下記のAmazon Linux 2の部分を参考にしてインストール
https://docs.fluentd.org/v1.0/articles/install-by-rpm
$ sudo curl -L https://toolbelt.treasuredata.com/sh/install-amazon2-td-agent3.sh | sh
$ sudo systemctl start td-agent.service
$ /opt/td-agent/usr/sbin/td-agent --version
td-agent 1.3.3
あっさりと起動しました。
あとはapacheのログを拾ってjsonとしてS3に投げるconfigを作る。
ここにだいたい書かれてます
https://docs.fluentd.org/v0.12/articles/apache-to-s3
$ sudo /opt/td-agent/usr/sbin/td-agent-gem install fluent-plugin-s3
<source>
@type tail
format apache2
keep_time_key true
time_format %d/%b/%Y:%H:%M:%S %z
path /var/log/httpd/access_log
pos_file /var/log/td-agent/apache2.access_log.pos
tag s3.apache.access
</source>
<match s3.*.*>
@type s3
s3_bucket apache-fluentd-athena-example
time_slice_format "%Y/%m/%d/%H"
path logs/%Y/%m/%d/
s3_object_key_format %{path}%{time_slice}_%{index}.%{file_extension}
<buffer time>
@type file
path /var/log/fluent/s3
timekey 60
timekey_wait 1m
timekey_use_utc false
timekey_zone Asia/Tokyo
</buffer>
<format>
@type json
</format>
</match>
S3bucketはapache-fluentd-athena-exampleと名付けました。
インスタンスはiamロール割り当ててるので設定がシンプルです。検証なので掃き出し間隔も短め。
config書いたらtd-agent.serviceをリスタートします。
その後、ab -c 10 -n 100000 http://localhost/とかやってログを増し増しします。
なお、td-agentユーザーだとaccess.log読めなかったので/lib/systemd/system/td-agent.serviceのUserとGroupはrootにしました。
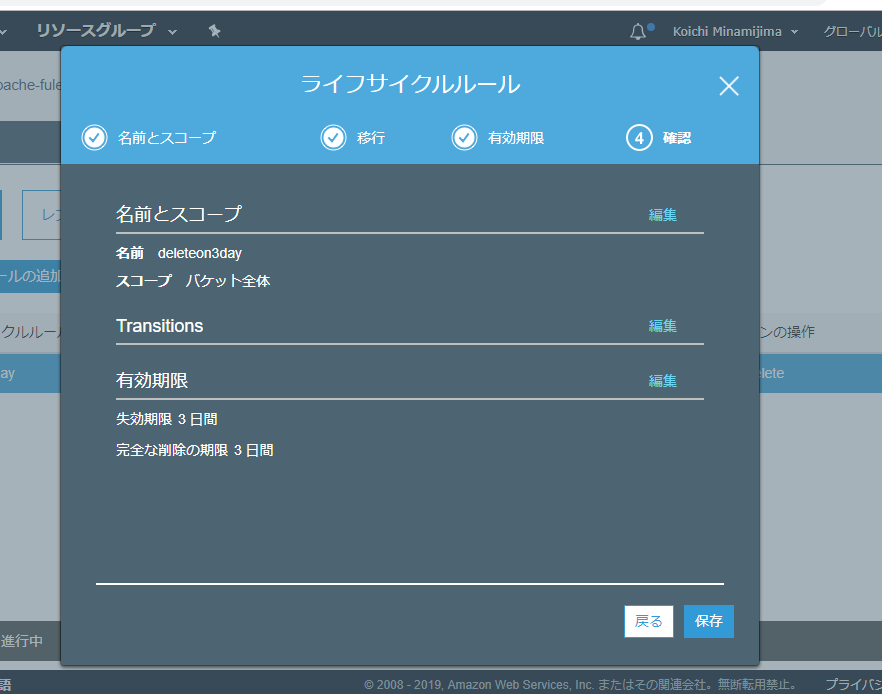
データは3日で消えるようにしました。
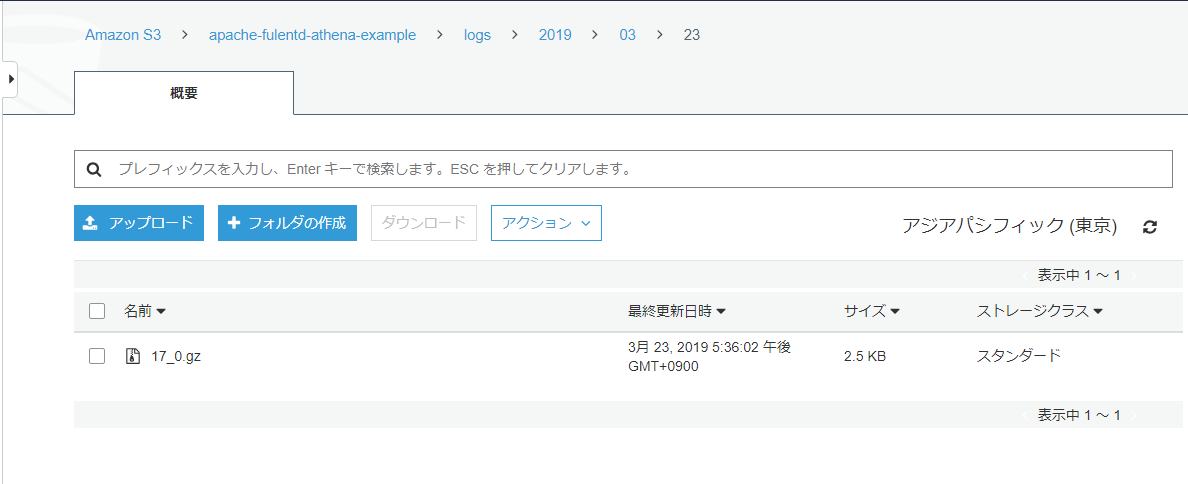
ログも保存できてるようです。
aws glue
クロールするとathenaのschemaを勝手に作ってくれるみたいなので、glueを使ってみます。
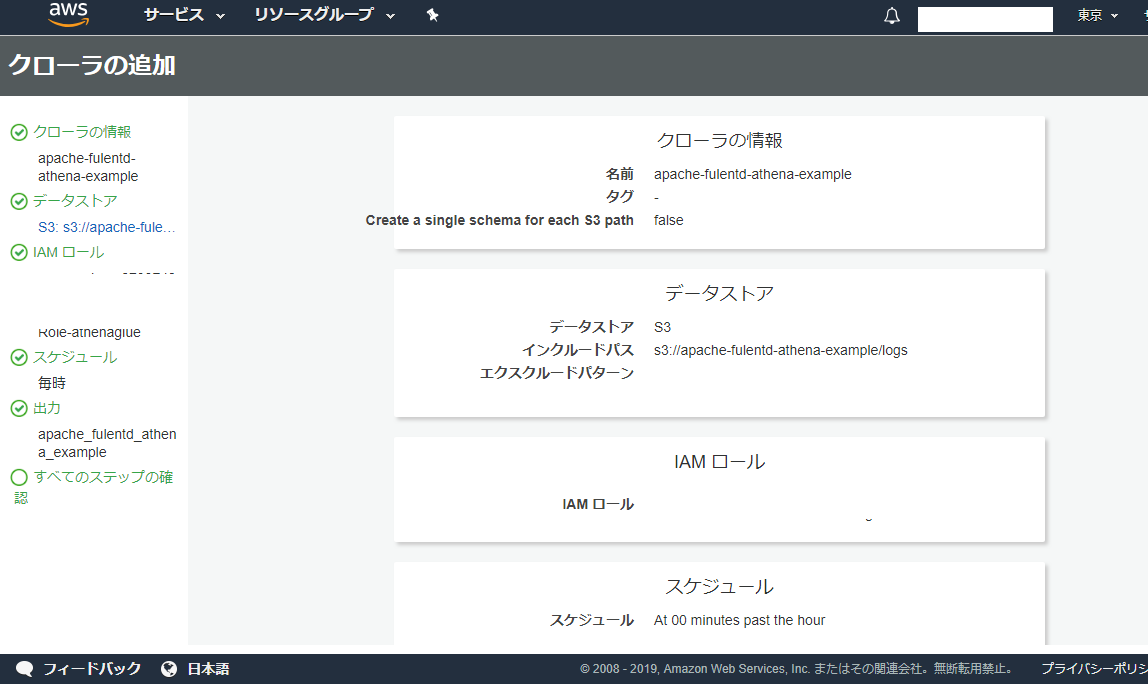
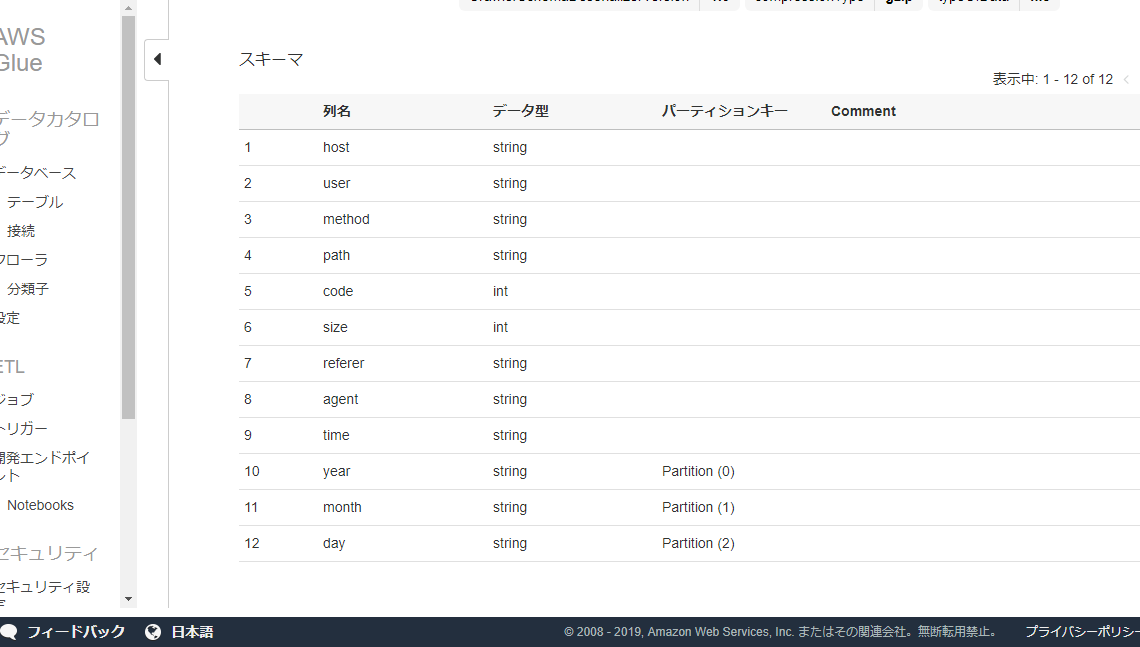
良い感じに解析してくれました。
partitionのとこはpartition1みたいな名前になってたので編集してyearとかmonthに変えておきました。
athena
ではathenaでquery投げてみます。
ほぼ、ただのSQLですね。
https://docs.aws.amazon.com/ja_jp/athena/latest/ug/select.html
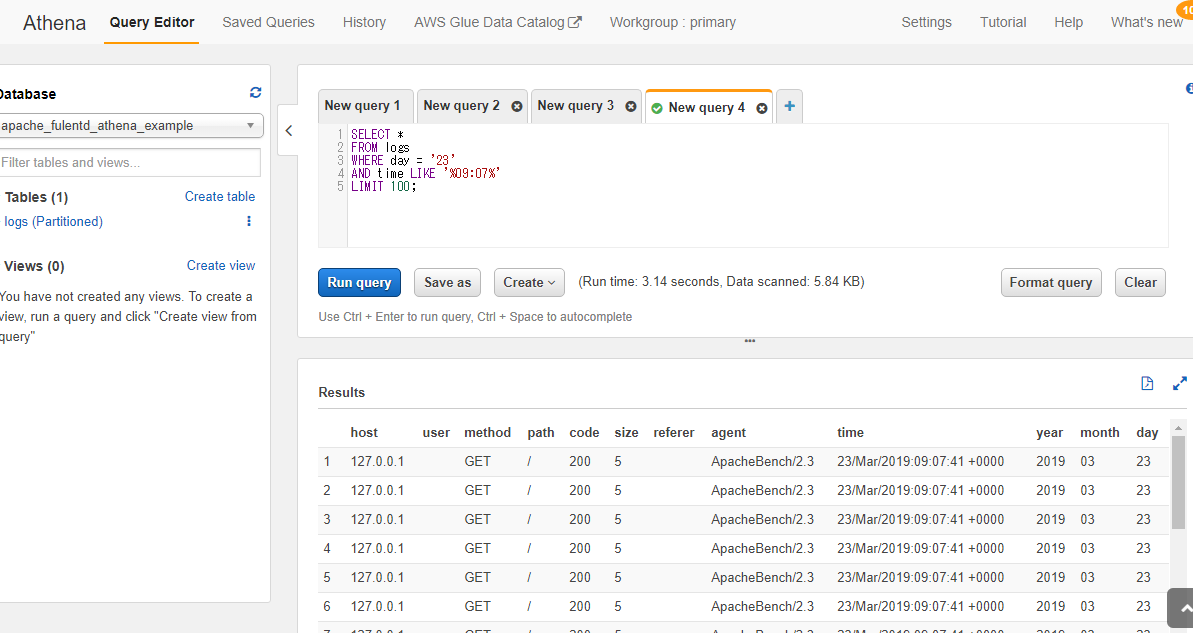
ちょっとデータが適当すぎてつまらないけど一応できました。
ちなみにAthenaは1TBをスキャン(の対象に)した場合に5USDらしいです。
ついうっかりどでかいデータにフルスキャンとかしちゃった日には無事死亡できますね。
圧縮とかパーティショニングとか怠らないようにしましょう。