
本記事はSSD物体検出と物体追跡の実行例を用いて両者の違いについて解説します。SSDは物体検出としてよく利用されるアルゴリズムですが、場合によって、物体追跡アルゴリズムとして流用することも可能。本記事はSSD検出と、SSD検出+追跡とで、両方サンプル動画を作成し、両者の違いについて考察してみます。
*本記事はこちらの記事を和訳したものです。
Introduction
SSD物体検出は過去の記事で取り上げましたが、基本的にSSDは入力された動画に対してフレーム単位で検出を行い、フレームごとのBoundingBoxが取得できます。Nフレームが経過した後、N個のBoundingBoxが得られるはずなので、BoundBoxを解析すれば、物体の動きとしてTrajectoryを取得できます。Trajectoryがあると、これまで物体の動きはもちろん、未来の動きもある程度予測することができます。
物体追跡技術は物体検出とは非常に似ています。画像上に興味のある場所(ROI: Region of Interest)を予め定義しておき、次のフレーム領域の中で定義されたROIの特徴と一番類似している領域を検索するのが、物体追跡の目的です。こちらOpenCVのTrackerについてわかりやすい記事があります。
Comparison
直感的にSSDで物体検出を行い、検出された物体を追跡するというのが一般的だが、前述したようにSSDのみでも行けそうなので、これからいくつかの具体例を通じて検証していきます。下の例では青のbboxがSSDの検出結果で、物体が検出されるたびに、その物体に追跡をかけます。追跡結果は赤のbboxに示す。
左:SSD
右:SSD+Tracking
例1:高画質動画+低速運動
全て検出できたわけではありませんが、それを一旦良いとして、優勝した7番コースの選手に注目することにします。ほぼ全てのフレームにおいて、左のSSD検出も右のSSD+trackingも問題なくターゲットのbboxを取得出来ています。この動画はカメラ位置が固定で、選手も安定した動きをしているから、前のフレームで人を検出できれば、次のフレームも検出できるはずです。また、Trackingもうまく出来ています。

例2:高画質動画+低速運動
この動画は、カメラ角度とともに被写体の姿勢もも大きく変わっています。ある角度からみると、検出精度が著しく落ちているということから、この角度からみた被写体が教師データに存在する確率が低いとも言える。一方、Trackingは狙った物体のbboxを正しく推定している

例3:高画質動画+低速運動+鳥瞰図
この例は画質的には例1とほぼ同じだが、唯一の違いはカメラ角度です。したがって、この角度から撮った被写体はおそらく教師データ全体の中にわずかしかなく、ほぼ検出不可になっています。一方、1フレームさえ検出できれば、Trackingはカメラ角度などとは関係なく、ちゃんと追跡ができています。

例4:低画質動画+高速運動
この動画は他より一番難易度の高いもの。ピンぼけが多数見受けられているので、検出率が極めて低い。Trackingは最初ある程度正確におこなっていますが、その後ランナーが重なることによって追跡していたターゲットが他のランナーに移してしまうことが発生しました。また、全体的にTrackingの結果がやや不安定。

下記の動画はこれまでのサンプルを大きい解像度でまとめたものです。

Tracking Algorithm
本記事で使用したTrackingのアルゴリズムはCNNを利用するTracking手法です。ネットワークのアーキテクチャを簡単にご紹介します。
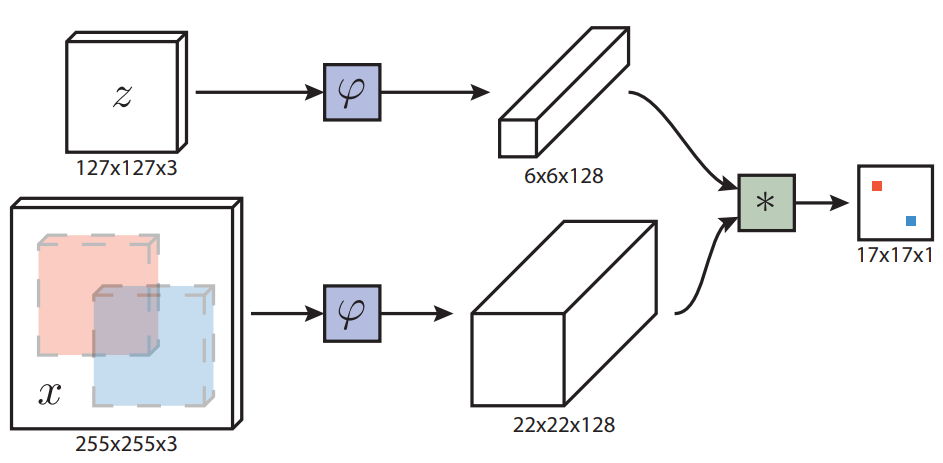
論文:Fully-Convolutional Siamese Networks for Object Tracking
実装:Tensorflow実装
特徴:GPUでリアルタイム処理が可能
アーキテクチャ:“z“はターゲットのtemplate(追跡しようとする人物)。”x”は探索領域(追跡する人物が存在するフレーム)。Trackingの基本は、探索領域”x”の中で、“z“に一番類似している領域を見つけることです。これを実現するために、教師データとして”x”と“z“を両方用意して、"φ"に入力します。"φ"はニューラルネットワークを表し、入力データの画素値を特徴空間にマッピングします。特徴空間を表すのが6x6x128 と 22x22x128のブロックです。論文によると、この2つのブロックは同じ構造(conv+pool layers)からなっていて、サイズだけ異なる。"*"は畳み込み演算で、6x6x128の特徴マップを畳み込みのカーネルとして用いて22x22x128の特徴マップに畳み込みをかけます。最終的に17x17x1のscore mapが生成され、“x”の各領域の中に、template “z”との類似度を表しています。最も高い得点は、“z”と一番類似している領域中心を表す。
Discussions
- 物体の動き 上記の例では、速い動きをする物体だと、検出に失敗することがあります。そうすると、次に検出されるまでの時間経過が長くなってしまうので、最終的に得られたTrajectoryの精度が落ちてしまう。ところが、Trackingは物体が必ず次のフレームのどこかに存在すると仮定し、速い動きをしても、templateに似ていれば追跡可能です。
- 画質 悪い画質だと、SSDもTrackingも精度が落ちます。物体検出も追跡も、実質的に、画像から何らかのターゲットを見つけ出すことが目的なので、この工程をスムーズに進めるために、できるだけ情報が落ちないように画像をRaw品質、又はそれに近い品質で保つ必要があります。圧縮やピンぼけ、縮小など、画像に大きく劣化させることは、検出及び追跡に精度が落ちたり、不安定になったりする原因となりますので、できるだけ避けるべきです。したがって、コンピュータビジョンのアルゴリズムを導入する前に、まず入力画像の品質を確保することが望ましいです。
Conclusion
冒頭で言及しましたが、SSDでは物体を追跡することができるかということについて、以下の要素が考えられる
1. カメラは常に動いているか?(例えば車載カメラ)
2. ターゲットとなる物体は高速運動をしているか
3. 正確なTrajectoryが必要か
上記の3点とも、Yesなら、安定性を保つのに、SSD検出の後で物体追跡を追加する必要があると考えられます。ただし、実際のシーンにもよりますが、こちらの例のようなシンプルなターゲットの場合はSSDだけでも十分かもしれません。その理由としては車の形は人間よりシンプルで検出しやすいからです。このほか、本記事で使用した追跡アルゴリズムは、類似した物体が重なった時にうまく追跡できないことが多いので、これによって深刻な問題となりうる場面では、きちんとこれを考慮して実装しなければなりません。