私はデータ分析が主な仕事ではないですが、簡単な集計を行い、対話的にデータを可視化して傾向をつかむような機会は度々あります。
そのたびに私はR言語やExcelで可視化を行うか、Pythonで可視化を行う必要がある際は不満も持ちつつmatplotlibの無骨なグラフを使っていました。ただ、この間「seabornがかなり便利だ」というコメントを頂き、実際にいくつかのサンプルを見てもmatplotlibをラップして簡単にggplot2のような美しいグラフが描けるようなので今回調べてみることにしました。
今回は関係ありませんが、R言語を使うのは、可視化ライブラリの問題というより、データフレームの操作がtidyverseのほうがPythonのpandasより簡潔だからという理由です。
可視化を試してみるグラフ
ソフトウェアエンジニアの仕事では複雑な統計検定をすることはほぼ無く、「(例えばエラーの原因を調べるために)データを集計して全体の傾向をつかむ」ような可視化がほとんどです。そのため、使用するグラフは限られていて、まずはシンプルなグラフで試行錯誤していきます。
そんなときに役立つ方針が『グラフをつくる前に読む本』という本にまとめられていて、こちらで薦められているグラフの描き方を調べていきます。こちらの書評ブログ(「グラフをつくる前に読む本」が名著だった話)で更にまとめられた表を引用します。
| 得意な表現方法 | 個別 | 全体 | |
|---|---|---|---|
| 実数 | 割合 | ||
| データ間の比較 | 棒グラフ | レーダーチャート | 円グラフ |
| 積み上げ棒グラフ | |||
| 時間の経過による推移 | 折れ線グラフ | 面グラフ | |
| データの偏り | ヒートマップ | ||
| データ項目同士の関係 | 散布図 | ||
これらのグラフと、データの大まかな分布を調べるときに使う「ヒストグラム」の描き方を調べていきます。上の表や本では紹介されていないのですが、「データの偏り」の一部を表現するのに役立つと思っています。
このうち、円グラフ以外の可視化方法を調べていきます。本の中でも円グラフは「積み上げ棒グラフのほうが使いやすい」と主張されていて、他の分析者の方もそういう記事を書かれていますし、自分の実体験上でもそのとおりなのでほとんど使用しません。また実は、seabornのissueでも「Sorry, no, seaborn will never support pie charts.(seabornでは円グラフを実装しない)」とバッサリ明言されているようです。
さて、これらのグラフが簡単に可視化できると私の用途では嬉しいのですが、seabornではどうなのでしょうか?
棒グラフ
データの集計をすると必ず使うグラフです。『グラフをつくる前に読む本』では以下のように紹介されています。
棒グラフでは、複数並んだ棒の高さを比べて「棒が大きい(小さい)項目はどれだろう?」と考えます。つまり棒グラフが一番得意な表現方法はデータの「比較」です。棒グラフを使えば、比べたいデータを最もわかりやすく図で表現できます。
公式のサンプルコードに欲しいものに近いものがありました。
sns.load_dataset("titanic")は、Kaggleで有名なタイタニックの生存者のデータセットをpandasのデータフレームとして読み込んでくれています。R言語に比べて「ちょっと可視化を試したい」ときのサンプルデータに困ることが多かったので助かりますね。
import seaborn as sns
sns.set(style="whitegrid")
# Load the example Titanic dataset
titanic = sns.load_dataset("titanic")
# Draw a nested barplot to show survival for class and sex
g = sns.catplot(x="class", y="survived", hue="sex", data=titanic,
height=6, kind="bar", palette="muted")
g.despine(left=True)
g.set_ylabels("survival probability")
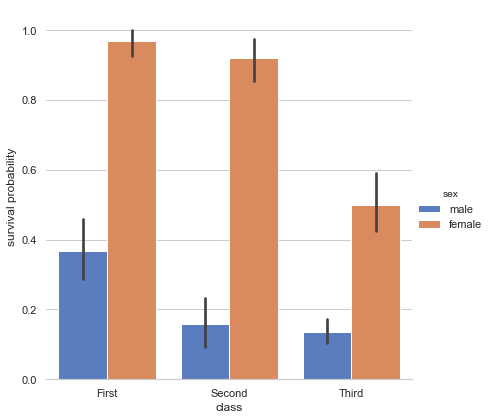
ちなみにtitanicの中身はこのようになっています。xやyではこれらのカラム名を指定しています。
| survived | pclass | sex | age | sibsp | parch | fare | embarked | class | who | adult_male | deck | embark_town | alive | alone | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 3 | male | 22.0 | 1 | 0 | 7.2500 | S | Third | man | True | NaN | Southampton | no | False |
| 1 | 1 | 1 | female | 38.0 | 1 | 0 | 71.2833 | C | First | woman | False | C | Cherbourg | yes | False |
| 2 | 1 | 3 | female | 26.0 | 0 | 0 | 7.9250 | S | Third | woman | False | NaN | Southampton | yes | True |
| 3 | 1 | 1 | female | 35.0 | 1 | 0 | 53.1000 | S | First | woman | False | C | Southampton | yes | False |
| 4 | 0 | 3 | male | 35.0 | 0 | 0 | 8.0500 | S | Third | man | True | NaN | Southampton | no | True |
また、どうやら勝手にエラーバーをつけてくれるようです。ドキュメントを読む限り、デフォルトでは95%信頼区間のようです。また、大学の研究室とかであまり把握しないまま発表してしまうと、教授から「自分が理解してない情報を載せてるのか!」って説教されると思うので気をつけてください。
また、catplot関数でkind="bar"を指定すると、barplotが呼び出されるそうです。というわけで、必要最低限の引数で可視化するときは次のようになりそうです。
sns.barplot(x="class", y="survived", hue="sex", data=titanic)
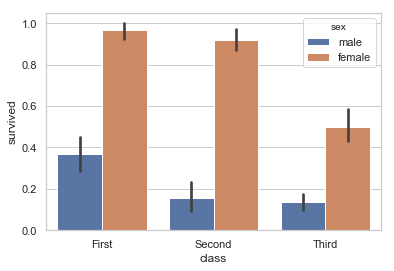
sns.barplot(x="class", y="survived", data=titanic)
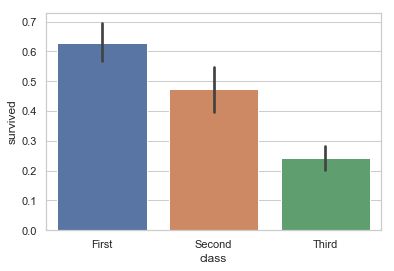
なかなか簡単ですね。
折れ線グラフ
例によって『グラフをつくる前に読む本』を引用します。
折れ線グラフでは、ある時点とある時点を左から右に線で結んで「先の傾きが大きい(小さい)時点はどれだろう?」、「傾きの傾向が変化するのはどの時点だろう?」と考えます。つまり折れ線グラフが一番得意な表現方法はデータの「推移」です。折れ線グラフを使えば、データの変化が最もわかりやすく図で表現できます。
これは公式ドキュメントに良いサンプルがありますね。
import seaborn as sns; sns.set()
fmri = sns.load_dataset("fmri")
sns.lineplot(x="timepoint", y="signal", data=fmri)
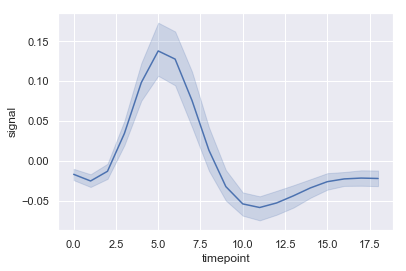
上下に書かれているのは、例によってデフォルトでは95%信頼区間だそうです。また、層別する場合はhue引数を指定します。
sns.lineplot(x="timepoint", y="signal", hue="event", data=fmri)
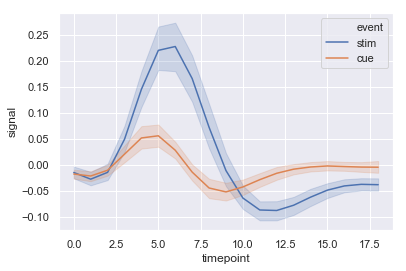
ただ、(可視化のサンプルなので問題無いといえば無いのですが)load_datasetのドキュメントを見ても、「seabornのドキュメント用のデータ」としか書かれていなくて困りますね。
ヒストグラム
他のグラフとレイヤーが違いますが、これも日常的に使うグラフだと思います。これもデータの「偏り」や「分布」を俯瞰して見るのに適したグラフだと思います。
『グラフをつくる前に読む本』で紹介されていないのは(一応)棒グラフの使い方の一種だからだということと、おそらく著者がマーケティング領域の方なので「全体を俯瞰する」ことにより重きを置いているからなんじゃないかと推察しています。
一応ヒートマップと棒グラフ(≒ヒストグラム)を比較した文章は本の中にありました。
データ項目を比較するだけなら棒グラフが適しています。棒グラフはデータ項目の比較には適していますが、全体を俯瞰して「まんべんなくデータが散らばっている」、もしくは「データが特定の項目に偏っている」と把握するのには適していません。
ただ、我々はログファイルなどの、より生データに近いデータを集計する場合が多く、そのような場合にはヒストグラムが活躍する場面が多いように思います。暮らしに役立つQC七つ道具(4) ―― ヒストグラム:「全体」の「傾向」をつかむという記事ではこのように紹介されています。余談ですが、品質管理分野ではけっこうこの手のノウハウが体系化されてて勉強になりそうですね。
今回取り上げるQC七つ道具は,「ヒストグラム」です.ヒストグラムとは,測定した値を区間(階級)に分けて,データの個数をグラフ化したもので,度数分布図とも呼ばれます.
ヒストグラムは,データの全体的な分布の傾向や偏りを確かめるのに使われ,分布の形や中心の位置,バラツキの大きさなどを見ることによって問題点を明らかにすることができます.
一般的に,製造工程のバラツキは,正規分布になるのがよいとされています.
私は、以前の上司からデータ分析についていろいろと教わったのですが、そのときに「WEBサイトの高速化の案件があった。そのときにレスポンスタイムが二つ山のある形をしていたため、『リクエストによっては時間のかかる処理(DBへ何度もリクエストしてしまっている等)があるんじゃないか?』という仮説を得ることができた」という話を聞いたことがあります。
これは平均値や中央値などだけを見ていても得られない知見ですし、ヒートマップでも(不可能ではないにせよ)難しいんじゃないかと思います。また、ヒストグラムは一次元の情報から有益な手がかり(次に調査すべきアイデア)を得られる可能性があるので、探索的にデータを分析する際に「とりあえずの一手」として使いやすいと感じています。
話が長くなりましたが、ヒストグラムはdistplot関数でプロットできます。ヒストグラムの場合は「数値の配列を、適切な粒度で集計して棒グラフにする」ような指定方法をします。
sns.distplot(titanic['fare'])
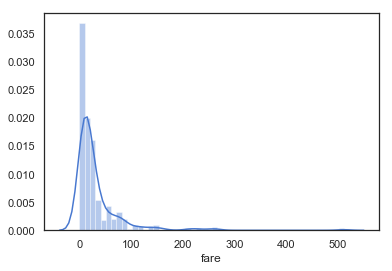
ヒストグラム以外にプロットしてしまうのは、gaussian kernel density estimateで推定した値のようです。これは初めて使ったのですが、2次元でもプロットできるようで、使いどころによってはなかなか面白そうです。
もしヒストグラムのみ表示したい場合はこうです。kde引数で、y軸のメモリが変わってしまうのはちょっと気持ち悪いですね…。
sns.distplot(titanic['fare'], kde=False)
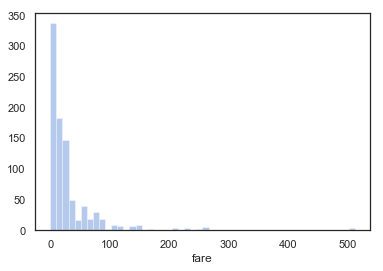
ドキュメントによるとnorm_histという引数で指定できそうだったんですが、今の私の環境では変わりませんでした。
norm_hist : bool, optional
If True, the histogram height shows a density rather than a count. This is implied if a KDE or fitted density is plotted.
「他の変数で層別してヒストグラムを作る」ような作業もFacetGridを使えばできました。
# heightが未指定だと画像が小さくなってしまう
g = sns.FacetGrid(titanic, hue="sex", height=5)
g.map(sns.distplot, "fare", kde=False)
g.add_legend()
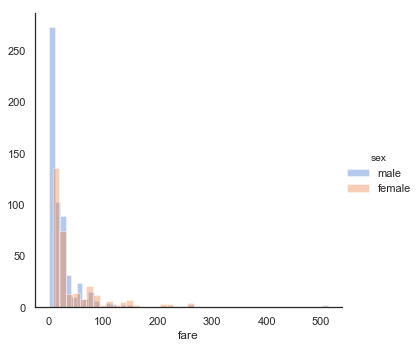
他にもいくつか情報があるので、これ以上は実際使うときに調べてみることとします。
ヒートマップ
『グラフをつくる前に読む本』から引用です。
ヒートマップは数字を色に置き換えて、「どのデータ項目にデータが偏っているだろうか?」と考えます。つまりヒートマップが一番得意な表現方法は量の「偏り」です。
flights = sns.load_dataset("flights")
flights = flights.pivot("month", "year", "passengers")
ax = sns.heatmap(flights)
こちらもheatmap関数でなんとかなります。なんでもありますね。
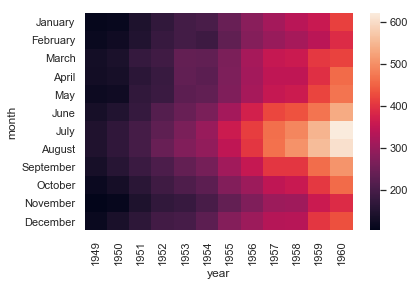
ちなみに、pivotはseabornの機能ではなく、単にpandasのDataFrameのpivotメソッドを呼んでいるだけです。これ知らなかったんですが便利ですね。
pandasのピボットテーブルでカテゴリ毎の統計量などを算出
散布図
これも『グラフをつくる前に読む本』から引用から。
複数の項目を表現した点を俯瞰して見て「縦軸と横軸の相関(2つのデータ項目が密接に関わり合っている状態)はあるだろうか?」と考えます。つまり散布図が一番得意な表現方法は、2つのデータ項目の「関係」です。
これはjointplotで、ヒストグラムと併せて描けます。
tips = sns.load_dataset("tips")
g = sns.jointplot(x="total_bill", y="tip", data=tips)
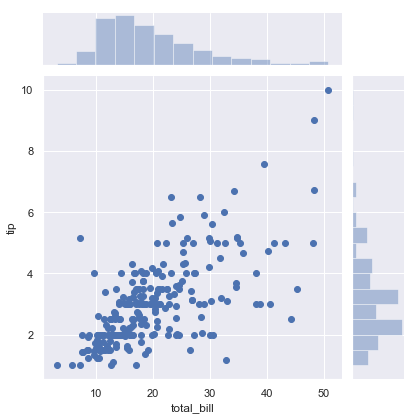
また、scatterplotを使うとヒストグラムが無いバージョンもできるし、pairplotを使えば変数の組み合わせで一気に描けるようですね。
『グラフをつくる前に読む本』では更に、「相関と因果関係を混同しないようにしよう」とか「単なる偶然である可能性も考慮しよう」という話も書いていて、実際に注意すべきなのですが、この記事の範疇を超えてしまうのでこれ以上は突っ込みません。ぜひ読んでみてください。
積み上げ棒グラフ
積み上げ棒グラフは、棒グラフと円グラフの良い所取りをしたグラフです。円グラフは内訳を「円の角度」で表現しましたが、積み上げ棒グラフは「棒の高さ」で表現します。(中略)積み上げ棒グラフは、円グラフが得意とする「内訳」と棒グラフが得意とする「比較」のどちらを強調したいか決めれば、何が言いたいのかより伝わります。
おそらく世間一般で円グラフを使うような場面では、私は積み上げ棒グラフを使います。私が欲しい機能は2つで、The Python Graph Galleryから引用すると以下の2つです。
まず、通常の積み上げ棒グラフ(#12 Stacked barplot with matplotlib)です。これは総量を比較するために使います。
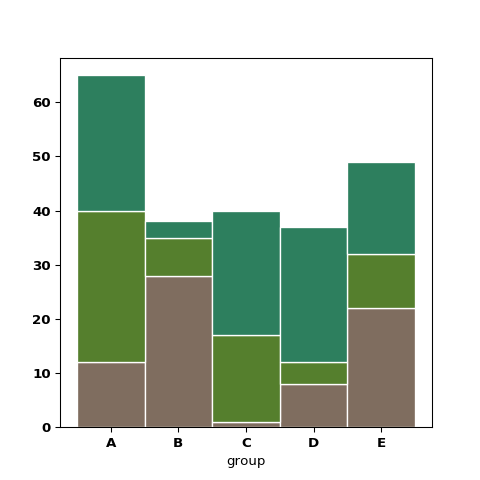
次にパーセント表示の積み上げ棒グラフ(#13 Percent stacked barplot)です。これは割合で比較するときに使います。
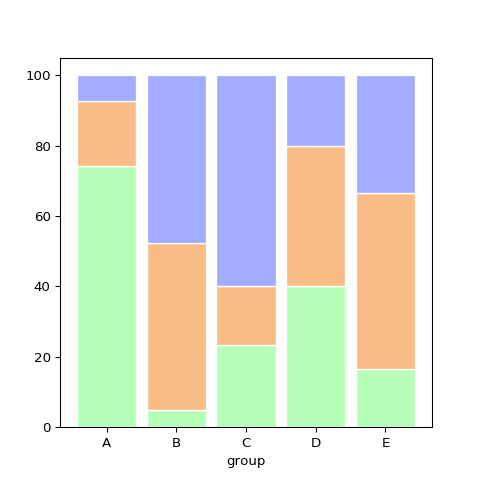
ただ、残念ながらseabornには今のところ積み上げ棒グラフの機能は無いようです。Horizontal bar plotsの例のように「トータルと別々にプロットする」くらいしか方法はありません。パーセント表示の積み上げ棒グラフの場合は少々手間がかかってしまいそうです。
また、どうやらpandasのplotメソッドにはstacked=Trueにすると積み上げ棒グラフが簡単に描けるオプションがあるようです。これと使い分けるのでもいいかもしれませんね。
面グラフ
あまり私自身聞き慣れませんでしたが、面グラフは「時系列データを用いた時間変化による内訳の推移」を表現するグラフです。私は、LIFULL HOME'Sの地域ごとの物件数の推移を表現するために使ったことがあります。
面グラフでは、面の推移を比べて「全体に対して占める割合が大きい(小さい)データ量はどのように変化するのだろう?」と考えます。つまり面グラフが一番得意な表現方法はデータ全体「内訳」の「推移」です。面グラフは、データ(数字)の総量と内訳の変化が最もわかりやすく図で表現できます。
残念ながら、これもseabornでは実装されていないようです。この辺りを参考にmatplotlibでコツコツ実装していくしかなさそうです。
これは割と理想的ですね。
レーダーチャート
円の中心から数えて、数が大きければ円の外側に、数が小さければ円の内側に折れ線が向かいます。それを見て「レーダーチャートは円の中にまんべんなく面を描けているだろうか?」と考えます。線で結ばれてできた面の滑らかさを頭の中で思い描きながら、図1のように特定の項目に偏っていないかを確認します。つまりレーダーチャートが一番得意な表現方法は、複数あるデータ項目の「比較」です。全体と部分を同時に比較しているのです。
私はレーダーチャートを使ったことはほとんど無い気がします。ただ、「物件スペックの比較」のような用途ではハマる使い方できるんじゃないかと思っています。
これもseabornでは実装されておらず、自前でがんばって実装していくしかなさそうです。私が欲しいグラフはこれですね。
ちなみに『海外では「スパイダーチャート」「スターチャート」、中国では「雷達図」と呼ばれていることが多い』ということも書いていたのですが、ライブラリ等のドキュメントではRader Chartと書かれていることが多いです。分野によって違うのかな?
まとめ
今回試してみて、私の用途で感じた利点と欠点です。今のところ、基本的な集計はseabornで、対応しない部分はmatplotlibで実装するのが良さそうだと感じています。
利点
- 基本的なグラフは描くことができる
- 自動で信頼区間等の追加情報も描いてくれるので、場合によっては「めちゃめちゃバラついてるのに集計してしまって気づけない」ような場合を防げるかもしれない。人によっては余計なお世話と感じてしまうかも
- pandasと組み合わせた操作がやりやすい
欠点
- 世間一般的にマイナーなグラフが未実装(個人的には積み上げ棒グラフが無いのがきつい)
- 用途から外れた場合、結局
matplotlibで実装する必要がある。その際にグラフのデザインの統一感を気にすると面倒かもしれない
また、今回多くを参考にさせて頂いた『グラフをつくる前に読む本』は更に詳しいノウハウや、それぞれが生まれてきた歴史に触れられています。グラフ・マニアの方はぜひ読んでみてください。