PandasでOne-HotベクトルをメモリケチるためにSparse行列(疎行列)として記録してGroupbyしたら値が消えて、1日分の処理丸々無駄にしまいました。疎行列のGroupbyで悲しい思いをする人が出ないように書いておきます。
環境:Pandas 0.23.4 Final
前置きが若干長いので、†闇†の部分だけ読みたい方は、「PandasのGroupbyとSparse行列の†闇†」まで飛んでください。
One-Hotベクトルとは
あるカラムだけ1で他のカラムは0な行列の表現。カテゴリー変数でよく使います。古典的な統計の教科書では「ダミー変数」という言い方もします。PandasのOneHotベクトルを作る関数get_dummiesはこれが由来です。
例えば、3つのクラスがあったとして、それぞれ$0, 1, 2$としましょう。今データのラベルが、
$$y=(0,1,2,1,0)$$
とします。これのOne-Hotベクトルは以下のようになります。
Y=\begin{bmatrix}1&0&0\\ 0&1&0 \\ 0&0&1 \\ 0&1&0 \\ 1&0&0\end{bmatrix}
このように0と1がいっぱい並んでいるのがOne-Hotベクトルの特徴です。
One-Hotベクトルのメリット
カテゴリー変数をOne-Hotベクトル化するメリットですが、逆にOne-Hotベクトル化しない場合のデメリットを考えたほうがわかりやすいです。例えば、今ある花の大きさを考えたいとします。3つのクラスで次のような特徴があったとします。
- $y=0$のクラスは、やたらと花が大きい(平均で20cmぐらいある)
- $y=1$のクラスは、とても花が小さい(平均で1cmもない)
- $y=2$のクラスは、花の大きさがそこそこ(平均で5cmぐらい)
花の大きさを$L$、カテゴリー変数を$C$、パラメーターを$a,b$として、
$$L=aC+b$$
という簡単な回帰モデルを考えます。もし、Cがカテゴリー変数そのままだったら、$C=(0,1,2)$と行った値が代入されますが、このような式(データ)から花の長さLを予測するのはかなり難しいです。なぜなら、カテゴリー変数の「値」と花の長さに関係がないからです。
サンプルプログラムを書いてみました。クラス0,1,2に対して50個ずつ、計150個サンプルを擬似的に作りました。ただの単回帰分析でやってみます。
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.metrics import r2_score
import matplotlib.pyplot as plt
np.random.seed(72)
# カテゴリー0は花が大きい、1は極めて小さい、2は普通
L = np.concatenate((np.random.normal(20.0, 2.0, size=50),
np.random.normal(1.0, 0.1, size=50),
np.random.normal(5.0, 1.0, size=50))).reshape(-1,1)
C = np.concatenate((np.repeat(0, 50), np.repeat(1, 50), np.repeat(2, 50))).reshape(-1,1)
regressor = LinearRegression()
regressor.fit(C, L)
L_pred = regressor.predict(C)
# R2スコア
r2 = r2_score(L, L_pred)
# 予測値と真の値のプロット
xlabel = np.arange(150)
plt.subplot(2,1,1)
plt.scatter(xlabel, L[:,0])
plt.title("True")
plt.subplot(2,1,2)
plt.scatter(xlabel, L_pred[:,0])
plt.title("Pred")
plt.suptitle("R2 = "+str(r2))
plt.show()
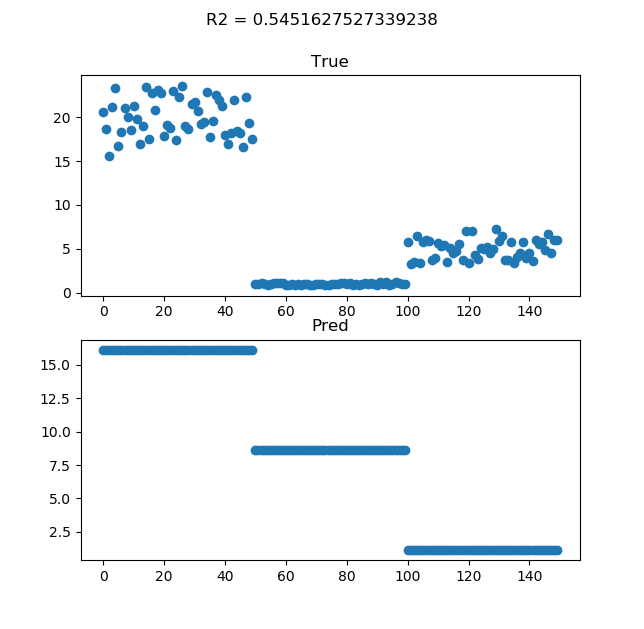
1つ目のクラスは予測できていますが、2つ目のクラスがダメダメです。相関係数も0.546と低いです。しかし、これは単回帰分析だから精度が悪いのではありません。カテゴリー変数(特徴量)の扱いがダメなのです。
データの生成と回帰モデルとの予測の間にOne-Hotエンコーディングをはさみます。これはSklearnのOneHotEncoderでやらせています。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(categories="auto", sparse=False)
C_onehot = encoder.fit_transform(C)
regressor = LinearRegression()
regressor.fit(C_onehot, L)
L_pred = regressor.predict(C_onehot)
One-Hotエンコーディングをはさむと単回帰でもグッと精度が上がります。
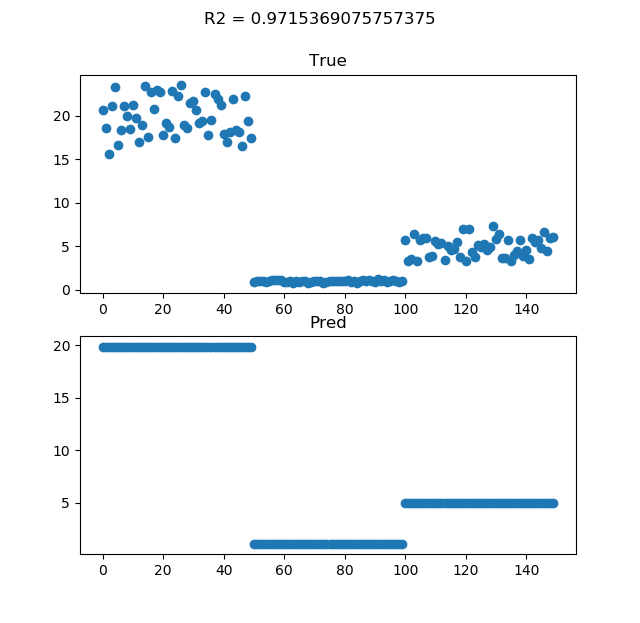
カテゴリー変数をOne-Hotベクトルに変えただけで、相関係数が0.546→0.972まで上がりました。2番目のクラスもちゃんと予測できていますね。「回帰モデルが悪いのではなく、特徴量の扱いがダメ」という教科書に載せられそうな美しい例ですね。
One-Hotベクトルのデメリット
何でもかんでもOne-Hotベクトルにすればいいという話ではなくて、ちゃんとデメリットもあります。それはメモリ使用量や計算量が爆発的に増えるということです。
理解しやすいのはメモリ使用量です。データが150個程度だと気にすることはありませんが、例えばデータが100万個でカテゴリーが1000個だったとします。ディープラーニングで使うことも考えて、最大でfloat32(4バイト変数)の型を割り当てるとします1。このメモリサイズは「1M×1k×4≒4GB」も必要です。One-Hotエンコーディングしない場合だったら1M×4≒4MBで十分です。
メモリ問題の対策としてのSparse行列
計算量の問題まで加味すると何らかの次元削減を検討する必要がありますが、メモリ問題だけならSparse行列(疎行列)を使えばOKです。例えば先程のSklearnのOneHotEncoderならオプションの「sparse=True」にするだけで疎行列で出力できます。
encoder = OneHotEncoder(categories="auto", sparse=True)
C_onehot = encoder.fit_transform(C)
print(C_onehot)
(0, 0) 1.0
(1, 0) 1.0
(2, 0) 1.0
(3, 0) 1.0
(4, 0) 1.0
(5, 0) 1.0
(6, 0) 1.0
(7, 0) 1.0
(8, 0) 1.0
(9, 0) 1.0
: :
このように1でない成分のインデックスと値を記録するというデータ構造です。One-Hotベクトルのようにほとんどが0の行列を扱う場合には強い味方です。
PandasのGroupbyとSparse行列の†闇†
ここからが†闇†の話です。先程はOneHotエンコーディングにSklearnのOneHotEncoderを使いましたが、より統合的な手法としてPandasのget_dummies()という関数があります。これはNanを勝手に落としてくれる機能があったり優れものです2。
get_dummies(sparse=False)(というか密行列一般?)でgroupbyをする場合は全く問題ありません。例えば次のようなデータにおいて、「class」変数をOneHotエンコーディングして、「group」変数でグルーピングするものとします。ここからapply関数を使ってグルーピングされたDataFrameをそのまま出力する関数を実行します。
import pandas as pd
import numpy as np
def identity(x):
print(x)
df = pd.DataFrame({"some_value":np.arange(5),
"class":np.array([3,0,1,3,-1]),
"group":np.array([0,0,0,1,1])})
df = pd.get_dummies(df, columns=["class"], sparse=False)
print(df)
df.groupby("group").apply(identity)
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
3 3 1 0 0 0 1
4 4 1 1 0 0 0
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
some_value group class_-1 class_0 class_1 class_3
3 3 1 0 0 0 1
4 4 1 1 0 0 0
このように、ちゃんとOneHotベクトルもグルーピングされました。「group=0」の場合だけ2回呼ばれていますが、これは仕様らしいです。
上のコードは密行列の場合はちゃんと動きますが、疎行列にすると闇の魔術になります。疎行列の場合はget_dummiesで「sparse=True」とします。
df = pd.get_dummies(df, columns=["class"], sparse=True)
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
3 3 1 0 0 0 1
4 4 1 1 0 0 0
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
some_value group class_-1 class_0 class_1 class_3
0 0 0 NaN NaN NaN NaN
1 1 0 NaN NaN NaN NaN
2 2 0 NaN NaN NaN NaN
some_value group class_-1 class_0 class_1 class_3
3 3 1 NaN NaN NaN NaN
4 4 1 NaN NaN NaN NaN
Nanが発生してしまいました。ちなみにapplyの関数の中で他のsome_valueでソートするともっと意味不明なことがおこります。
def identity(x):
x = x.sort_values("some_value", 0, False)
print(x)
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
3 3 1 0 0 0 1
4 4 1 1 0 0 0
some_value group class_-1 class_0 class_1 class_3
2 2 0 0 0 1 0
1 1 0 0 1 0 0
0 0 0 0 0 0 1
some_value group class_-1 class_0 class_1 class_3
2 2 0 0 0 0 0
1 1 0 0 0 0 0
0 0 0 0 0 0 0
some_value group class_-1 class_0 class_1 class_3
4 4 1 0 0 0 0
3 3 1 0 0 0 0
Nanではなく、One-Hotベクトルの値が消えます。自分はこれで1日走らせた前処理が全部無駄になりました。
原因はapplyの関数の中で返り値がなかったから
ちなみにこの疎行列でGroupbyしたときにNanが出る現象を回避する方法はあって、applyで食わす関数の返り値にDataFrameを入れるということです。
恒等出力の場合はreturnで自分自身を返す
最初のidentityの場合は「return x」を入れましょう。
def identity(x):
print(x)
return x # これを追加
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
3 3 1 0 0 0 1
4 4 1 1 0 0 0
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
some_value group class_-1 class_0 class_1 class_3
3 3 1 0 0 0 1
4 4 1 1 0 0 0
これで期待された結果が出ました。
ソートする場合は、さらにsort_valuesの中で「inplace=True」を追加する
ソートする場合は、ソートしたDataFrameを返すだけではうまくいきません。
def identity(x):
x = x.sort_values("some_value", 0, False)
print(x)
return x
some_value group class_-1 class_0 class_1 class_3
2 2 0 0 0 0 0
1 1 0 0 0 0 0
0 0 0 0 0 0 0
some_value group class_-1 class_0 class_1 class_3
4 4 1 0 0 0 0
3 3 1 0 0 0 0
さらに、sort_valuesの中で「inplace=True」を追加して、元の引数のDataFrameを上書きするようにします。
def identity(x):
x.sort_values("some_value", 0, False, inplace=True)
print(x)
return x
some_value group class_-1 class_0 class_1 class_3
0 0 0 0 0 0 1
1 1 0 0 1 0 0
2 2 0 0 0 1 0
3 3 1 0 0 0 1
4 4 1 1 0 0 0
some_value group class_-1 class_0 class_1 class_3
2 2 0 0 0 1 0
1 1 0 0 1 0 0
0 0 0 0 0 0 1
some_value group class_-1 class_0 class_1 class_3
2 2 0 0 0 1 0
1 1 0 0 1 0 0
0 0 0 0 0 0 1
some_value group class_-1 class_0 class_1 class_3
4 4 1 1 0 0 0
3 3 1 0 0 0 1
これでようやく期待された出力が得られました。ちなみに、これ「疎行列が悪いんじゃん。applyの中で密行列に変換すればよくね?」というのはダメです。相変わらずOneHotベクトルが消えました。
def identity(x):
dense = x.to_dense()
dense = dense.sort_values("some_value", 0, False)
print(dense)
return dense
Sprase行列のGruopby、非常に†闇†が深いなと思いました。大きいデータでやる前に、簡単な例で期待された出力になるか確認するのを強く推奨します。returnを省略したり、ソートの置き換えをしなくても疎行列ではない場合はうまく行ってしまいます。
なぜreturnを入れるのを忘れてしまったかというと、Pandasがただのメソッドチェーンとして使えて便利だったからです。密行列で試してうまく行ったから、疎行列でもうまくいくだろうと思ったのが浅はかでした。おそらくですが、密行列は値コピーされるが、疎行列の場合シャローコピーで参照しか渡されないのでしょうね。メソッド内のprintなのに、returnを入れればちゃんと機能するのが†闇†。
(やっぱりapplyで最初のグループを2回呼んでる仕様がいけないんじゃないの)
教訓
Sparse行列のGroupbyは闇が深いが、
- 必ずapplyの関数で、DataFrameを返すようにする
- 疎行列の参照を考えて、メソッド内の置き換え操作は「inplace=True」などで上書きするようにする
とすると防衛術になるのではないかということでした。
正直疎行列なんて小手先の方法使わないで、Pandasのバックエンドのデータ構造をSQL等(SQLでなくても例えばRedisをバックエンドにしたらどうだろう?)にして、全てインメモリでやらせるのではなく永続化しながらストレージと連携してクエリ操作をする、データベースとPandasをもっと密な形で動かせるライブラリが欲しいなと思いました。これだったらメモリ問題まず解消すると思います。
-
実際にOne-Hotベクトルに変換するときはもっとコンパクトな型(Pandasのget_dummiesだったらデフォルトはnp.uint8)で十分ですが、どこかで分類器に食わせるときにもっと高価な型が必要になることがあります。 ↩