概要
Elasticsearchにデータを投入したは良いものの、後からドキュメントの構造を変えたくなることがありますね。
WebサイトやREST APIであれば、短時間で連続してアクセスすると攻撃と見做されても困ります。
ゆっくりしていってね!という感じでアクセスしたくなりますが、そうするとデータを取りなおすのにすごく時間がかかってしまいます。
そんなときの小ネタです。
やりたいこと
元データには、post_stream以下にpostsの配列が入っています。
posts以下をバラバラにして、再度indexingしたい。
変更前
こんなデータがあったとします。
post_stream以下にpostsが2個入っています。これを2つのdocumentとして登録しなおしたいです。
{
"field1": "test1",
"field2": "test2",
"field3_array": [
"array1",
"array2",
"array3"
],
"post_stream": {
"posts": [
{
"name": "hoge",
"id": "111"
},
{
"name": "fuga",
"id": "222"
}
]
}
}
変更後
こうしたいです。
postごとに独立させたドキュメントにします。
{
"field1" : "test1",
"field2" : "test2",
"field3_array" : [
"array1",
"array2",
"array3"
],
"post" : {
"name" : "hoge",
"id" : "111"
}
}
{
"field1" : "test1",
"field2" : "test2",
"field3_array" : [
"array1",
"array2",
"array3"
],
"post" : {
"name" : "fuga",
"id" : "222"
}
}
先人の知恵を検索
こちらによると、こんな回答がついてます。
Yes I think this is doable with the reindex API by using a script.
ex : ctx._source.flat_field = ctx._source.nested_field.field;
But if you're using a nested mapping, the value will be an array of values.
Another solution would be to use logstash for this purpose.
arrayではなく、別々のドキュメントとして登録したいので、logstashでやってみることにしました。
Logstashの設定
全体の流れはこうなります。
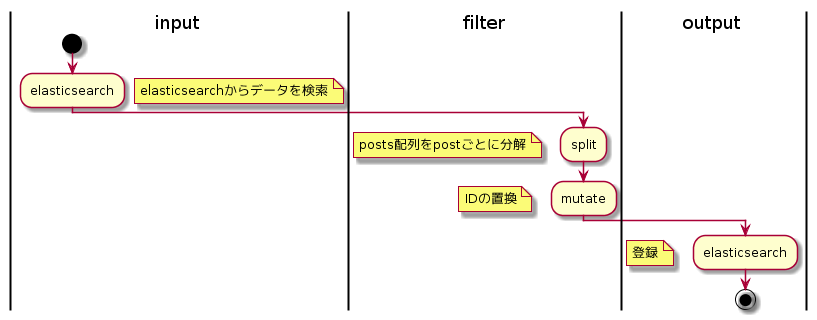
| No | フェーズ | 使用プラグイン | 処理 |
|---|---|---|---|
| 1 | input | elasticsearch | Elasticsearchから変換元のデータを取得します |
| 2 | filter | split | posts配列をpostごとに分解します |
| 3 | filter | mutate | 新たに登録しなおすIDを採番します |
| 4 | output | elasticsearch | Elasticsearchに新しい構造のドキュメントを登録します |
inputにelasticsearchプラグインとsplitを使うところがポイントかと思います。
設定ファイル
input {
# Read all documents from Elasticsearch matching the given query
elasticsearch {
hosts => "192.168.xxx.xxx"
index => "original_data"
docinfo => true
size => 50
query => '{
"query" : {
"match_all": {}
}
}'
}
}
filter {
split {
field => '[post_stream][posts]'
target => "post"
remove_field => "[post_stream]"
}
mutate {
update => { "[@metadata][_id]" => "%{[@metadata][_id]}_%{[post][id]}" }
}
}
output {
stdout {}
elasticsearch {
hosts => "192.168.xxx.xxx"
index => "conv.%{[@metadata][_index]}"
document_type => "%{[@metadata][_type]}"
document_id => "%{[@metadata][_id]}"
}
}
解説
input部分
input {
# Read all documents from Elasticsearch matching the given query
elasticsearch {
hosts => "192.168.xxx.xxx"
index => "original_data"
docinfo => true
size => 50
query => '{
"query" : {
"match_all": {}
}
}'
}
}
docinfoはデフォルトではfalseになっていると書いてありますが、ここではtrueにしています。
下表のようなIDを新しく採番で使いたいので、metadataで_idや_indexを取得できるようにしています。
| 元のdocumentID | 子ポストのID | 新しく登録するdocumentID |
|---|---|---|
| 1 | 111 | 1-111 |
| 1 | 222 | 1-222 |
| 2 | 111 | 2-111 |
filter部分
splitの部分は、公式ドキュメントの説明が一番わかりやすいかと思います。
躓きどころとしては、ネストされたオブジェクトが配列になっていて、そこを指定したいとき、どう書けばよいか、というところでしょうか。
The field which value is split by the terminator. Can be a multiline message or the ID of an array. Nested arrays are referenced like: "[object_id][array_id]"
ちゃんとドキュメントには書いてありまーす。
今回の場合でいえば、[post_stream][posts]と書けば良い、ということですね。
確認
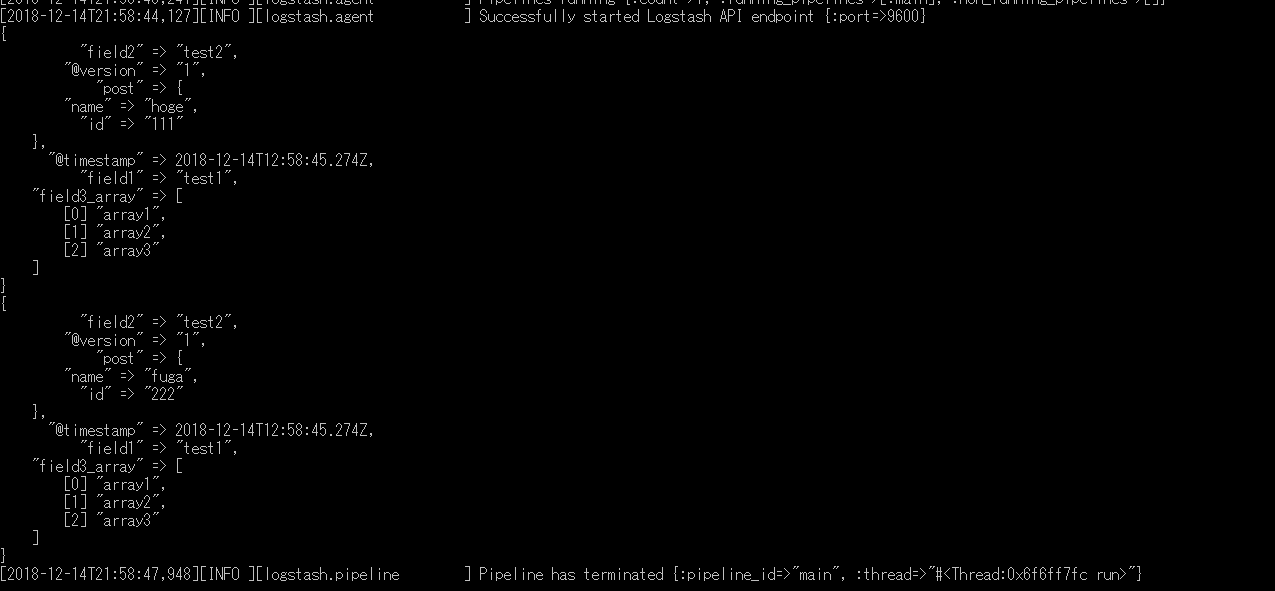
outputをstdoutなどで確認してやれば、postごとにデータが分かれていることを確認することができます。
おわりに
同じElasticsearchで別Indexに入れなおすもよし、異なるElasticsearch環境に入れるもよし、値を置換するのでなく、構造をがらっと変えてやりなおしたいときの1つのやり方にはなるでしょう。
beatsシリーズのように、起動がはやけりゃ、言うことないんですがねぇ・・・惜しい。