はじめに
こんにちは。
みなさま年末いかがお過ごしでしょうか。
この記事はSupership Advent Calendar 2018 15日目です。
私はデータビジネス事業部に所属しており、
Supershipの保有している広告配信ログを使った各種分析を担当しています。
アドテク業界やWeb業界にお勤めのデータサイエンティスト・エンジニアの方にはご理解いただけるかと思いますが、
Web系のデータは巨大で(もちろん私たちSupershipも例外ではありません)、ストレスなく日常的に集計するとなるとなかなか大変です。
そのような巨大なデータを分析するための分析基盤として近年いくつものプロダクトが
開発されていますが、私たちのチームではDatabricks社のDatabricksを利用しています。
このプロダクト、非常に便利ながらあまり日本語情報がなく、今ひとつ広まっていない印象です。
そこでこの記事では、私たちの業務におけるユースケースも交えながらDatabricksのすごさや、
どのように活用しているのか、データアナリスト目線で紹介したいと思います。
0. Databricksとは
DatabricksとはDatabricks社が開発したApache Sparkのホスティングサービスで、
Unified Analytics Platform として開発されています。
ユーザ目線から見るとJupyter Notebookに非常によく似ているのですが、
このあと紹介する多種多様な機能を備えており、その名の通りUnifiedにデータ分析を行うことができます。
例えば、データ分析の流れでよくあるような、
- s3上に置いた複数ファイルにまたがるデータを分散処理を用いて集計および整形する
- クラスタリングや予測モデルを構築する
- 分析プロセス・結果を上司や同僚にレビューしてもらう
- 分析結果を可視化しダッシュボードとして展開する
といったプロセスがすべてDatabricksだけで完結できます。
どうでしょう。興味を持っていただけたでしょうか。
次に具体的な機能を紹介していきます。
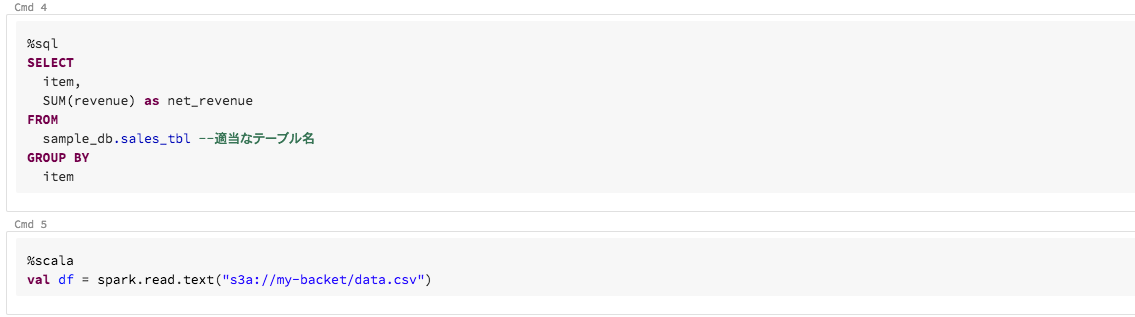
1. ひとつのnotebook上でpythonだけではなくSQLやScalaも柔軟に実行できる
Databricksのnotebookは、%sql や %scala というマジックコマンドを
セルの先頭で使うことによって単一のnotebookの中でPythonやSQL,Scalaのスクリプトを
実行することができます。また、ここでは紹介しませんが、Rやシェルスクリプトも実行可能です。
でも、これだけだとありがたみが伝わりづらいかもしれません。もう少し実用的なケースをご紹介しましょう。
その前に軽く前置きをすると、Pythonはデータ分析において非常に強力な言語ではありますが、
JavaやScalaといった静的型付け言語に比べるとどうしても処理速度が遅いことが課題として挙げられます。
そこで例えばspark SQLに実装されていないような処理をscalaで実行し、その結果をまたpysparkで扱うことができたら便利だと思いませんか?
簡単なデモをお見せします。
例:webサイトの記事タイトルを形態素解析する
まずはpythonで適当なSparkDataFrameを作成します。
記事タイトルは弊社のサービス、nanapiから拝借しました。
# 適当なデータを作成
import pandas as pd
df_txt = spark.createDataFrame(pd.DataFrame({
"article_id": [0, 1, 2],
"article_title": [
"日本酒で煮るだけ!毎晩たべても飽きない『常夜鍋』の作り方",
"着たまま直す!浴衣の着崩れを3ステップで整える方法",
"簡単であっという間にキレイ!クエン酸で電気ケトルの汚れを落とす方法",
]}))
# tmpviewを作成
df_txt.createOrReplaceTempView("df_txt")
そして、同じnotebookの次のセルでは、上記のデータを受け取りscalaで形態素解析を行います。
%scala
// 必要なモジュールをimport
import com.atilika.kuromoji.ipadic.neologd.{Token,Tokenizer}
import collection.JavaConversions._
import org.apache.spark.sql._
import org.apache.spark.sql.types._
import org.apache.spark.sql.functions._
// 形態素解析を実行するための関数を定義(動詞など活用形がある品詞は原型に直す)
def tokenizePartitionSimple(it : Iterator[Row], columnName : String ) : Iterator[Row] = {
val tokenizer = new Tokenizer()
val newPartition = it.map( (r: Row) => {
val txtIndex = r.fieldIndex(columnName)
val tokens = tokenizer
.tokenize(r.getString(txtIndex))
.map(t => if(t.isKnown()) t.getBaseForm() else t.getSurface())
.filter(_ != " ")
.mkString(" ")
Row.fromSeq(r.toSeq :+ tokens)
}).toList
newPartition.iterator // create a new iterator
}
var tokenizeFunction : (Iterator[Row], String) => Iterator[Row] = tokenizePartitionSimple
// 形態素解析を実行する
var df = table("df_txt")
val columnName = "article_title"
val tokenized_rdd = df.rdd.mapPartitions((it: Iterator[Row]) => tokenizeFunction.apply(it, columnName))
val df_tokenized = spark.createDataFrame(tokenized_rdd, df.schema.add(StructField("tokenized", StringType, true)))
// 再びpythonで扱えるようにtmpviewを作成
df_tokenized.createOrReplaceTempView("df_tokenized")
そして、scalaで処理したデータをpythonで受け取ってみましょう。
# pysparkで結果を確認
df_tokenized = table("df_tokenized")
df_tokenized.show(10, False)
このデータ量だとscalaで処理するメリットはほぼない大きくはありませんが、データが大きくなれば当然メリットも大きくなります。こうした言語をまたいだ処理が手軽にできるのはありがたいですね。
2. 履歴管理機能やコメント機能でnotebook上でコードレビュー・議論も行える
Databricksにはスクリプトの履歴を管理する機能や、notebookに直接(コードとは別に)コメントできる機能も備えられています。
イメージとしては、jupyter notebookをgoogle docsのような使い心地で利用することができます。
事例を交えながら個別に機能について解説していきましょう。
例えば、Jupyter notebookをベースに分析を長時間行っていると、「重要な関数を書いたセルを間違って削除してしまった。」
「モデルのハイパーパラメータを色々いじっているうちに、精度が良かった(orベンチマークにしていた)
予測モデルのパラメータがわからなくなってしまった」といった状況を経験することもあるかと思います(私はあります笑)。
そんな時に、notebookを5分前や1時間前、昨日時点の状態にさっと戻せたら便利だと思いませんか?
Databricksはnotebookの履歴を自動で管理してくれ、そんなワガママをかなえてくれます。
自動で数分おきに履歴を管理してくれる他、任意の時点での保存、githubとの連携機能を使っている場合は
連携しているgitリポジトリのcommit履歴も表示され、いつでも任意の履歴の復元が可能です。
さらに、複数人でnotebookを編集しているときには誰がどの箇所を変更したかも管理してくれます。
コメント機能は、私達のチームでは分析プロセスについての議論やカジュアルなコードレビューに利用しています。
これらの機能に関しては「Gitで良いじゃん」と思われるかもしれません(正直否定しません)が、アドホック分析、
特に分析を始めたばかりの段階においては書き捨てのコードも多いため、
必ずしもgit上でコードを管理しないこともあるかと思います。
そんな時にも直接notebook上で気軽にコメントすることで分析プロセスやコードの品質向上に努めています。
3. notebookをバッチスクリプトとして利用できる
おそらく、データ分析を実務でやっている人から見ると一番魅力的なのはここではないでしょうか。
「Jupyter Notebookをバッチスクリプトとして利用する方法」のはデータ分析界隈で最近話題になっており色々な方法が提案されています12が、
私たちのチームではdatabricksのjobs機能でそれを実現しています。
これにより、分析者が構築した予測モデルをそのままバッチスクリプトとして定期実行することができ、私たちのチームでは主に広告配信セグメントの作成に活用しています。
Jobごとにスケジューラを設定できることはもちろん、クラスタスペックや依存ライブラリを柔軟に設定できるので、
「このスクリプト、重いけど確実かつhogehoge時間以内に実行したいのでハイスペックなインスタンスを割り当てたい」
「このスクリプトは重い処理は特にないからコスト削減のためにインスタンススペックを下げて実行しよう」
といったような柔軟な調整が効き、またコスト管理もしやすいメリットがあります。
4. notebookをダッシュボードとして利用できる
さらに、Databricksは、sparkDataFrameをダッシュボードとして可視化することができます。
しかも、記法はシンプルで、display() というDatabricksがサポートしている関数にSparkDataFrameを渡してあげるだけです。
例:display(<dataframe-name>)
そこから、グラフの設定をGUIベースで作っていくことができます。使用感はほぼBIツールですね。
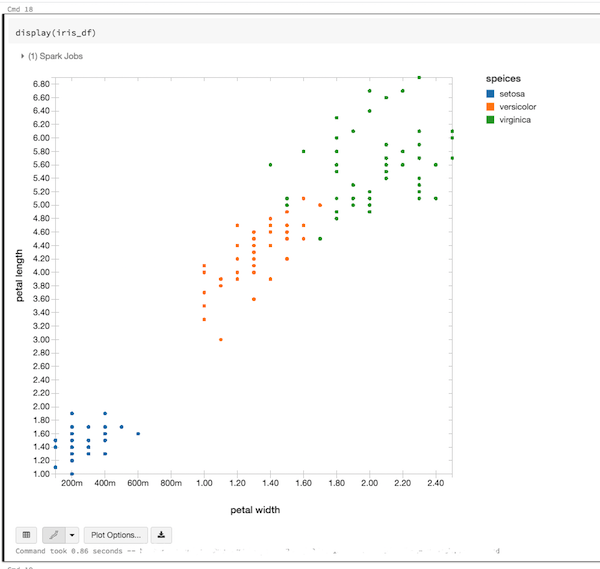
例えばこんなグラフが作れます(データはみなさんおなじみirisです)。
Databricks上での可視化の例
散布図も書けるし、
棒グラフもかける(そしてマウスオーバーすると値も表示される)
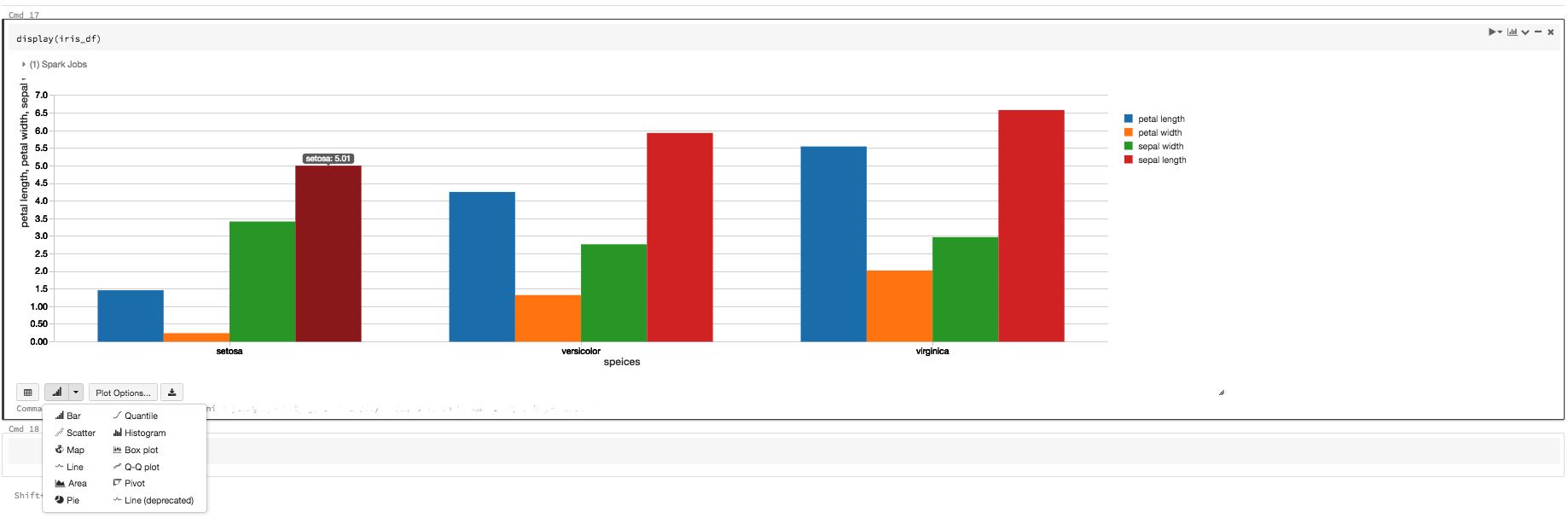
現状、他のBIツールと比べてしまうとサポートしているビューの種類は決して多いとは言えませんが、棒グラフやヒストグラム、散布図といった
基本的な可視化方法は網羅しており、社内向けに分析結果を共有する程度なら十分そのニーズを満たすことができます。
そして、ダッシュボードとして活用できるのはもちろん、データ理解のためのEDAにも活用でき非常に役立っています。
まとめ
データ分析の様々なプロセスがDatabricks上で行えることを示してみました。
書き出してみるとかなり長い記事になっており反省しているのですが、正直まだまだお伝えしきれていない機能やノウハウもあります。
興味を持たれた方はぜひ公式ドキュメントなどもご参照ください。
最後に、私たちの部署では広告配信ログを始めとしたデータを活用したDMPを開発しており、一緒に働いてくれる仲間を募集しています。
ビッグなデータでApache Sparkをぶん回したい方、DMPやアドテク、マーケティングに興味がある方、いろんなデータに触ってみたい方、ついついこの記事を最後まで読んでしまった方、ぜひご応募お待ちしております!