“And now for our main event! Ladies and gentlemen, in this corner, weighing in at 34% of the cloud infrastructure market, the reigning champion and leader of the public cloud…. Amazon!” Amazon has unparalleled expertise at maximizing scalability and availability for a vast array of customers using a plethora of software products. While Amazon offers software products like DynamoDB, it’s database-as-a-service is only one of their many offerings.
“In the other corner is today’s challenger — young, lightning quick and boasting low-level Big Data expertise… ScyllaDB!” Unlike Amazon, our company focuses exclusively on creating the best database for distributed data solutions.
A head-to-head database battle between ScyllaDB and DynamoDB is a real David versus Goliath situation. It’s Rocky Balboa versus Apollo Creed. Is it possible ScyllaDB could deliver an unexpected knockout punch against DynamoDB? [SPOILER ALERT: Our results will show ScyllaDB has 1/4th the latencies and is only 1/7th the cost of DynamoDB — and this is in the most optimized case for Dynamo. Watch closely as things go south for Dynamo in Round 6. Please keep reading to see how diligent we were in creating a fair test case and other surprise outcomes from our benchmark battle royale.]
To be clear, ScyllaDB is not a competitor to AWS at all. Many of our customers deploy ScyllaDB to AWS, we ourselves find it to be an outstanding platform, and on more than one occasion we’ve blogged about its unique bare metal instances. Here’s further validation — our ScyllaDB Cloud service runs on top of AWS. But we do think we might know a bit more about building the monstrously fast and scalable NoSQL database, so we limited the scope of this competitive challenge solely to ScyllaDB versus DynamoDB, database-to-database.
ScyllaDB is a drop-in replacement for Cassandra, implemented from scratch in C++. Cassandra itself was a reimplementation of concepts from the Dynamo paper. So, in a way, ScyllaDB is the “granddaughter” of Dynamo. That means this is a family fight, where a younger generation rises to challenge an older one. It was inevitable for us to compare ourselves against our “grandfather,” and perfectly in keeping with the traditions of Greek mythology behind our name.
If you compare ScyllaDB and Dynamo, each has pros and cons, but they share a common class of NoSQL database: Column family with wide rows and tunable consistency. Dynamo and its Google counterpart, Bigtable, were the first movers in this market and opened up the field of massively scalable services — very impressive by all means.
ScyllaDB is much younger opponent, just 4.5 years in age. Though ScyllaDB is modeled on Cassandra, Cassandra was never our end goal, only a starting point. While we stand on the shoulders of giants in terms of existing design, our proven system programing abilities have come heavily into play and led to performance to the level of a million operations per second per server. We recently announced feature parity (minus transactions) with Cassandra, and also our own database-as-a-service offering, ScyllaDB Cloud (NoSQL DBaas).
But for now we’ll focus on the question of the day: Can we take on DynamoDB?
Rules of the Game
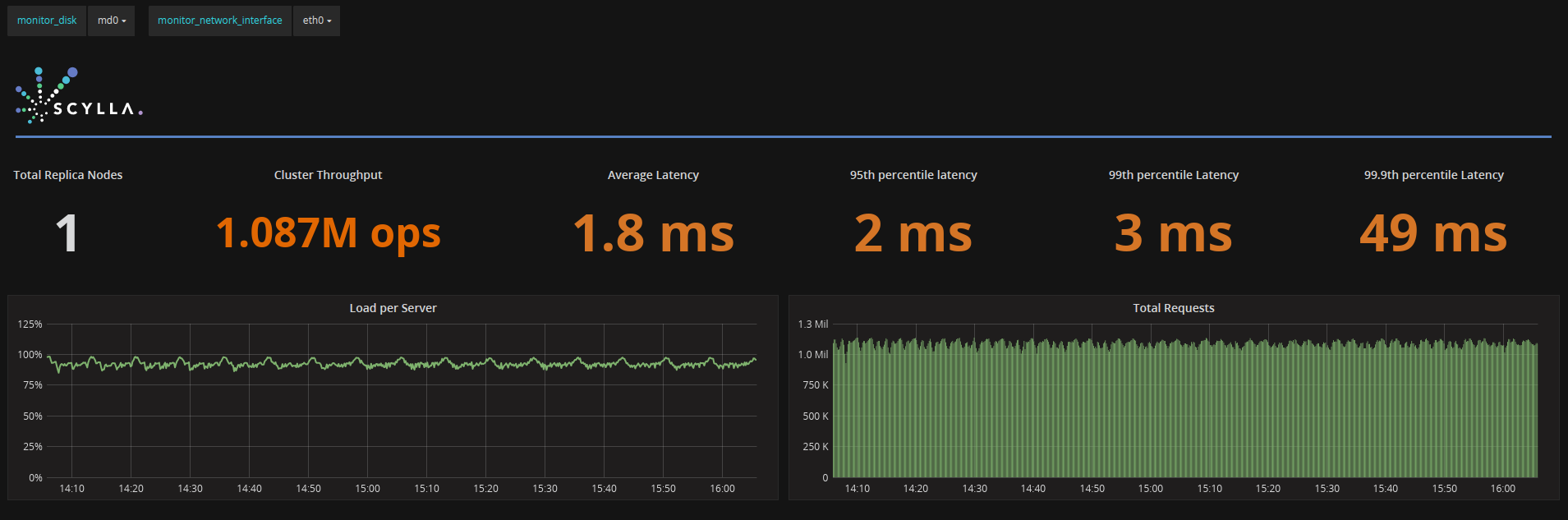
With our open source roots, our culture forces us to be fair as possible. So we picked a reasonable benchmark scenario that’s supposed to mimic the requirements of a real application and we will judge the two databases from the user perspective. For the benchmark we used Yahoo! Cloud Serving Benchmark (YCSB) since it’s a cross-platform tool and an industry standard. The goal was to meet a Service Level Agreement of 120K operations per second with a 50:50 read/write split (YCSB’s workload A) with a latency under 10ms in the 99% percentile. Each database would provision the minimal amount of resources/money to meet this goal. Each DB should be populated first with 1 billion rows using the default, 10 column schema of YCSB.
We conducted our tests using Amazon DynamoDB and Amazon Web Services EC2 instances as loaders. ScyllaDB also used Amazon Web Services EC2 instances for servers, monitoring tools and the loaders.
These tests were conducted on ScyllaDB Open Source 2.1, which is the code base for ScyllaDB Enterprise 2018.1. Thus performance results for these tests will hold true across both Open Source and Enterprise. However, we use ScyllaDB Enterprise for comparing Total Cost of Ownership
DynamoDB is known to be tricky when the data distribution isn’t uniform, so we selected uniform distribution to test Dynamo within its sweet spot. We set 3 nodes of i3.8xl for ScyllaDB, with replication of 3 and quorum consistency level, loaded the 1 TB dataset (replicated 3 times) and after 2.5 hours it was over, waiting for the test to begin.
| ScyllaDB Enterprise | Amazon DynamoDB |
ScyllaDB Cluster
|
Provisioned Capacity
|
- Workload-A: 90 min, using 8 YCSB clients, every client runs on its own data range (125M partitions)
- Loaders: 4 x m4.2xlarge (8 vCPU | 32 GiB RAM), 2 loaders per machine
- ScyllaDB workloads runs with Consistency Level = QUORUM for writes and reads.
- ScyllaDB starts with a cold cache in all workloads.
- DynamoDB workloads ran with
dynamodb.consistentReads = true - Sadly for DynamoDB, each item weighted 1.1kb – YCSB default schema, thus each write originated in two accesses
Let the Games Begin!
We started to populate Dynamo with the dataset. However, not so fast..
Turns out the population stage is hard on DynamoDB. We had to slow down the population rate time and again, despite it being well within the reserved IOPS. Sometimes we managed to populate up to 0.5 billion rows before we started to receive the errors again.
Each time we had to start over to make sure the entire dataset was saved. We believe DynamoDB needs to break its 10GB partitions through the population and cannot do it in parallel to additional load without any errors. The gory details:
- Started population with Provisioned capacity: 180K WR | 120K RD.
 We hit errors on ~50% of the YCSB threads causing them to die when using ≥50% of write provisioned capacity.
We hit errors on ~50% of the YCSB threads causing them to die when using ≥50% of write provisioned capacity.- For example, it happened when we ran with the following throughputs:
- 55 threads per YCSB client = ~140K throughput (78% used capacity)
- 45 threads per YCSB client = ~130K throughput (72% used capacity)
- 35 threads per YCSB client = ~96K throughput (54% used capacity)
After multiple attempts with various provisioned capacities and throughputs, eventually a streaming rate was found that permitted a complete database population. Here are the results of the population stage:
| YCSB Workload / Description | ScyllaDB Open Source 2.1 (3x i3.8xlarge) 8 YCSB Clients |
DynamoDB (160K WR | 80K RD) 8 YCSB clients |
| Population 100% Write Range Distribution: |
Overall Throughput(ops/sec): 104K Avg Load (scylla-server): ~85% INSERT operations (Avg): 125M |
Overall Throughput(ops/sec): 51.7K Max Consumed capacity: WR 75% INSERT operations (Avg): 125M |
ScyllaDB completed the population at twice the speed but more importantly, worked out of the box without any errors or pitfalls.
YCSB Workload A, Uniform Distribution
Finally, we began the main test, the one that gauges our potential user workload with an SLA of 120,000 operations. This scenario is supposed to be DynamoDB’s sweet spot. The partitions are well balanced and the load isn’t too high for DynamoDB to handle. Let’s see the results:
| YCSB Workload / Description |
ScyllaDB Open Source 2.1 (3x i3.8xlarge) 8 YCSB Clients |
DynamoDB (160K WR | 80K RD) 8 YCSB clients |
| Workload A 50% Read / 50% Write Range Distribution: Duration: 90 min. |
Overall Throughput(ops/sec): 119.1K Avg Load (scylla-server): ~58% READ operations (Avg): ~39.93M UPDATE operations (Avg): ~39.93M |
Overall Throughput(ops/sec): 120.1K Avg Load (scylla-server): ~WR 76% | RD 76% READ operations (Avg): ~40.53M UPDATE operations (Avg): ~40.53M |
After all the effort of loading the data, DynamoDB was finally able to demonstrate its value. DynamoDB met the throughput SLA (120k OPS). However, it failed to meet the latency SLA of 10ms for 99%, but after the population difficulties we were happy to get to this point.
ScyllaDB on the other hand, easily met the throughput SLA, with only 58% load and latency. That was 3x-4x better than DynamoDB and well below our requested SLA. (Also, what you don’t see here is the huge cost difference, but we’ll get to that in a bit.)
We won’t let DynamoDB off easy, however. Now that we’ve seen how DynamoDB performs with its ideal uniform distribution, let’s have a look at how it behaves with a real life use-case.
Real Life Use-case: Zipfian Distribution
A good schema design goal is to have the perfect, uniform distribution of your primary keys. However, in real life, some keys are accessed more than others. For example, it’s common practice to use UUID for the customer or the product ID and to look them up. Some of the customers will be more active than others and some products will be more popular than others, so the differences in access times can go up to 10x-1000x. Developers cannot improve the situation in the general case since if you add an additional column to the primary key in order to improve the distribution, you may improve the specific access but at the cost of complexity when you retrieve the full information about the product/customer.
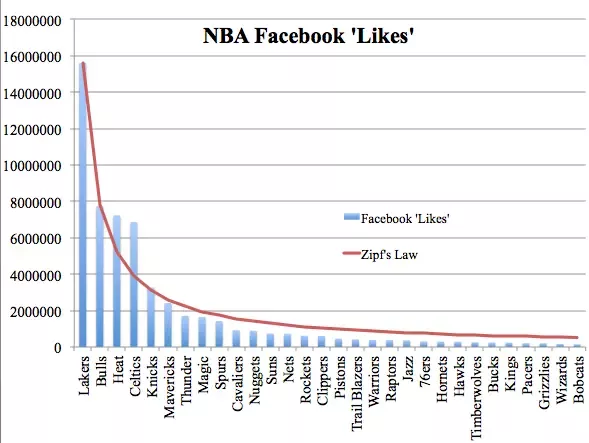
Keep in mind what you store in a database. It’s data such as how many people use Quora or how many likes NBA teams have:
With that in mind, let’s see how ScyllaDB and DynamoDB behave given a Zipfian distribution access pattern. We went back to the test case of 1 billion keys spanning 1TB of pre-replicated dataset and queried it again using YCSB Zipfian accesses. It is possible to define the hot set of partitions in terms of volume — how much data is in it — and define the percentile of access for this hot set as part from the overall 1TB set.
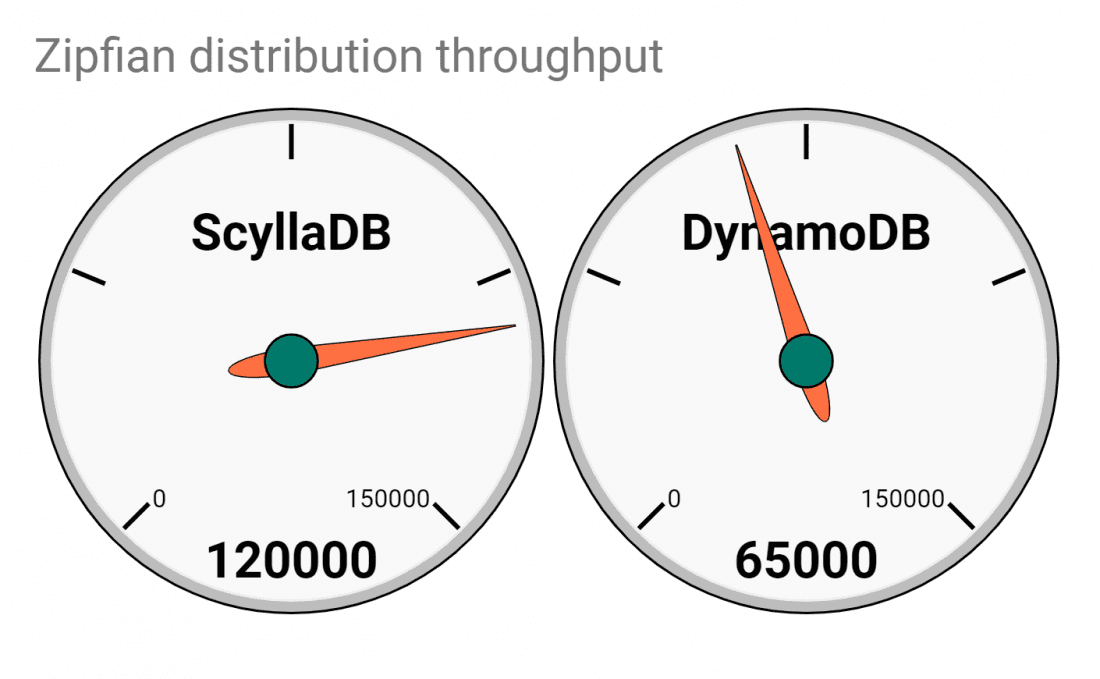
We set a variety of parameters for the hot set and the results were pretty consistent – DynamoDB could not meet the SLA for Zipfian distribution. It performed well below its reserved capacity — only 42% utilization — but it could not execute 120k OPS. In fact, it could do only 65k OPS. The YCSB client experienced multiple, recurring ProvisionedThroughputExceededException (code: 400) errors, and throttling was imposed by DynamoDB.
| YCSB Workload / Description |
ScyllaDB 2.1 (3x i3.8xlarge) 8 YCSB Clients |
DynamoDB (160K WR | 80K RD) 8 YCSB clients |
| Workload A 50% Read / 50% Write Range: 1B partitions Distribution: Zipfian Duration: 90 min. Hot set: 10K partitions |
Overall Throughput(ops/sec): 120.2K Avg Load (scylla-server): ~55% READ operations (Avg): ~40.56M UPDATE operations (Avg): ~40.56M |
Overall Throughput(ops/sec): 65K Avg Load (scylla-server): ~WR 42% | RD 42% READ operations (Avg): ~21.95M UPDATE operations (Avg): ~21.95M |
Why can’t DynamoDB meet the SLA in this case? The answer lies within the Dynamo model. The global reservation is divided to multiple partitions, each no more than 10GB in size.

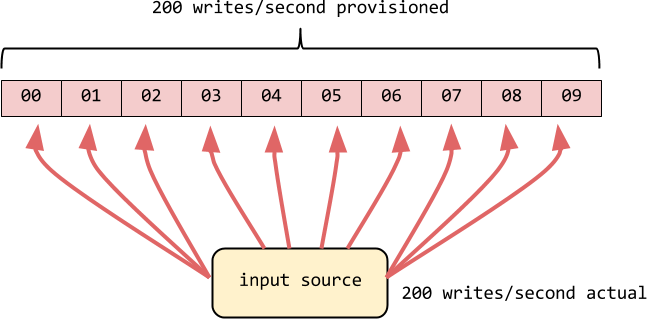
This when such a partition is accessed more often it may reach its throttling cap even though overall you’re well within your global reservation. In the example above, when reserving 200 writes, each of the 10 partitions cannot be queried more than 20 writes/s
The Dress that Broke DynamoDB
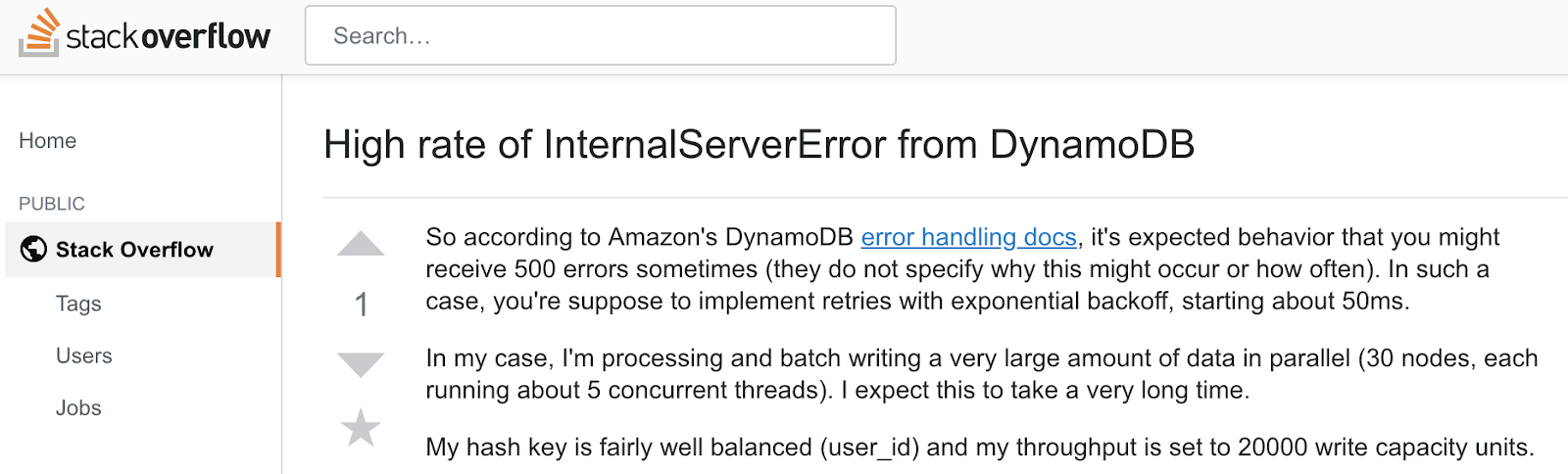
If you asked yourself, “Hmmm, is 42% utilization the worst I’d see from DynamoDB?” we’re afraid we have some bad news for you. Remember the dress that broke the internet? What if you have an item in your database that becomes extremely hot? To explore this, we tested a single hot partition access and compared it.

We ran a single YCSB, working on a single partition on a 110MB dataset (100K partitions). During our tests, we observed a DynamoDB limitation when a specific partition key exceeded 3000 read capacity units (RCU) and/or 1000 write capacity units (WCU).
Even when using only ~0.6% of the provisioned capacity (857 OPS), the YCSB client experienced ProvisionedThroughputExceededException (code: 400) errors, and throttling was imposed by DynamoDB (see screenshots below).
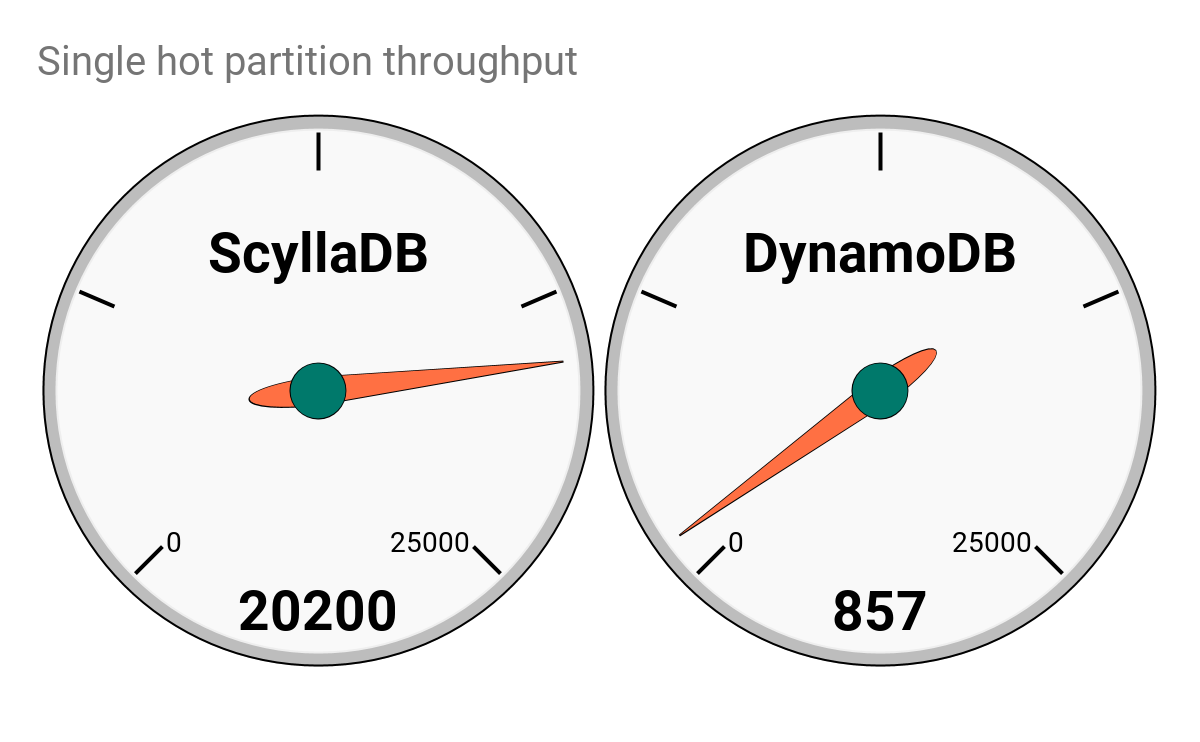
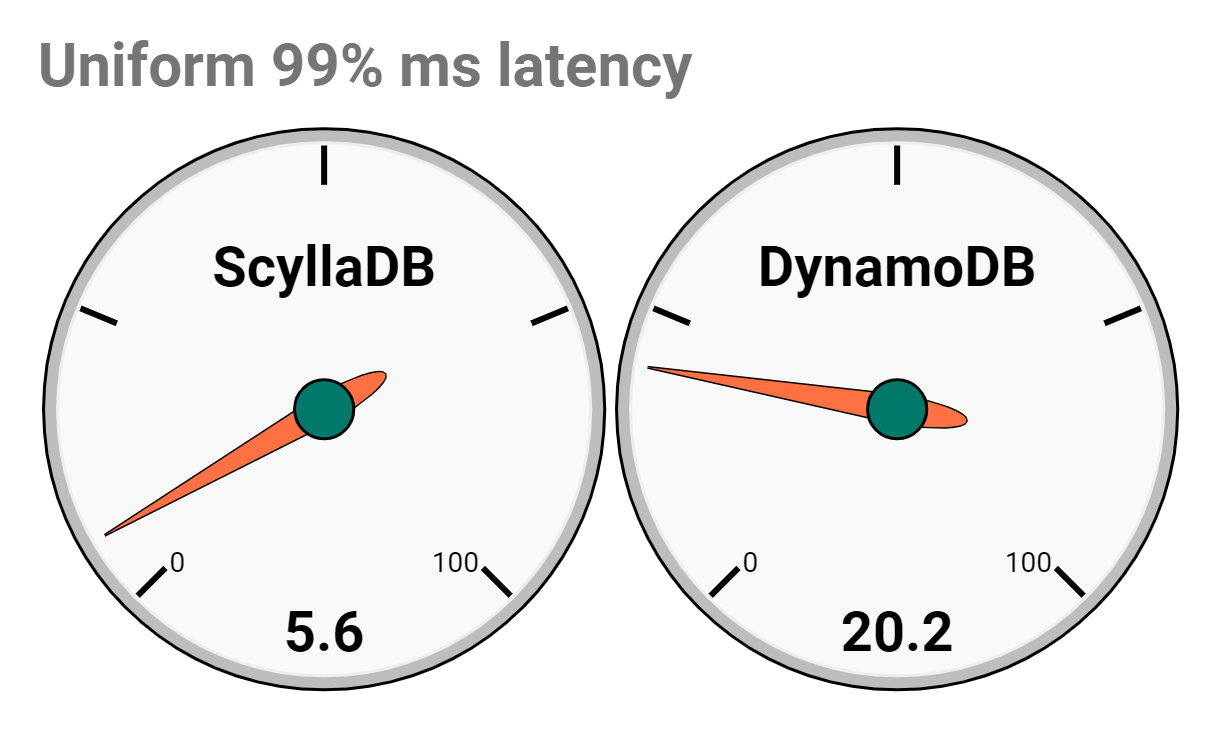
It’s not that we recommend not planning for the best data model. However, there will always be cases when your plan is far from reality. In the ScyllaDB case, a single partition still performed reasonably well: 20,200 OPS with good 99% latency.
ScyllaDB vs DynamoDB – Single (Hot) Partition
| YCSB Workload / Description |
ScyllaDB 2.1 (3x i3.8xlarge) 8 YCSB Clients |
DynamoDB (160K WR | 80K RD) 8 YCSB clients |
| Workload A 50% Read / 50% Write Range: Distribution: Uniform Duration: 90 min. |
Overall Throughput(ops/sec): 20.2K Avg Load (scylla-server): ~5% READ operations (Avg): ~50M UPDATE operations (Avg): ~50M |
Overall Throughput(ops/sec): 857 Avg Load (scylla-server): ~WR 0.6% | RD 0.6% READ operations (Avg): ~2.3M UPDATE operations (Avg): ~2.3M |
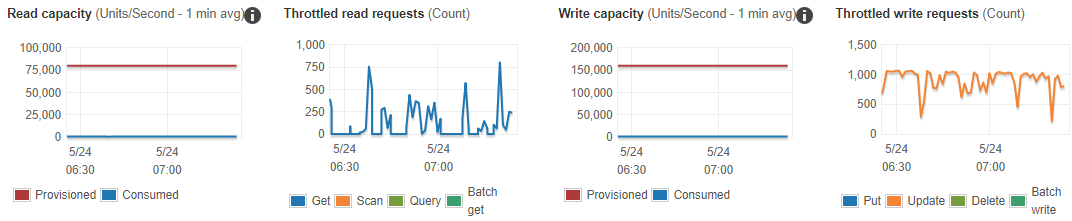
Screenshot 1: Single partition. Consumed capacity: ~0.6% -> Throttling imposed by DynamoDB
Additional Factors
Cross-region Replication and Global Tables
We compared the replication speed between datacenters and a simple comparison showed that DynamoDB replicated in 370ms on average to a remote DC while ScyllaDB’s average was 82ms. Since the DynamoDB cross-region replication is built on its streaming api, we believe that when congestion happens, the gap will grow much further into a multi-second gap, though we haven’t yet tested it.
Beyond replication propagation, there is a more burning functional difference — ScyllaDB can easily add regions on demand at any point in the process with a single command:
ALTER KEYSPACE mykespace WITH replication = { 'class' : 'NetworkTopologyStrategy', 'replication_factor': '3', '<exiting_dc>' : 3, <new_dc> : 4};
In DynamoDB, on the other hand, you must define your global tables ahead of time. This imposes a serious usability issue and a major cost one as you may need to grow the amount of deployed datacenters over time.

Explicit Caching is Expensive and Bad for You
DynamoDB performance can improve and its high cost can be reduced in some cases when using DAX. However, ScyllaDB has a much smarter and more efficient embedded cache (the database nodes have memory, don’t they?) and the outcome is far better for various reasons we described in a recent blog post.
Freedom
This is another a major advantage of ScyllaDB — DynamoDB locks you to the AWS cloud, significantly decreasing your chances of ever moving out. Data gravity is significant. No wonder they’re going after Oracle!
ScyllaDB is an open source NoSQL database. You have the freedom to choose between our community version, an Enterprise version and our new fully managed service. ScyllaDB runs on all major cloud providers and opens the opportunity for you to run some datacenters on one provider and others on another provider within the same cluster. One of our telco customers is a great example of the hybrid model — they chose to run some of their datacenters on-premise and some on AWS.
![]()
Our approach for “locking-in” users is quite different — we do it solely by the means of delivering quality and value such that you won’t want to move away from us. As of today, we have experienced exactly zero customer churn.
No Limits
DynamoDB imposes various limits on the size of each cell — only 400kb. In ScyllaDB you can effectively store megabytes. One of our customers built a distributed storage system using ScyllaDB, keeping large blobs in ScyllaDB with single-digit millisecond latency for them too.
Another problematic limit is the sort key amount, DynamoDB cannot hold more than 10GB items. While this isn’t a recommended pattern in ScyllaDB either, we have customers who keep 130GB items in a single partition. The effect of these higher limits is more freedom in data modeling and fewer reasons to worry.
Total Cost of Ownership (TCO)
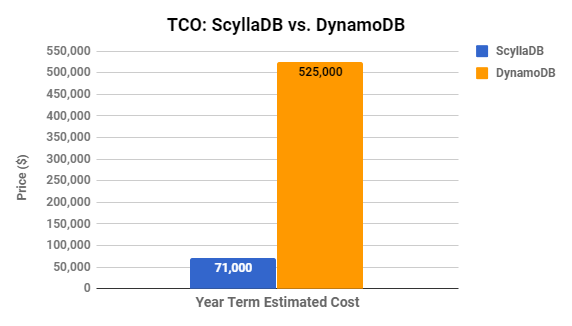
We’re confident the judges would award every round of this battle to ScyllaDB so far, and we haven’t even gotten to comparing the total cost of ownership. The DynamoDB setup, which didn’t even meet the required SLA and which caused us to struggle multiple times to even get working, costs 7 times more than the comparable ScyllaDB setup.
| ScyllaDB Enterprise (3 x i3.8xlarge + ScyllaDB Enterprise license) |
Amazon DynamoDB (160K write | 80K Read + Business-level Support) |
Year-term Estimated Cost: ~$71K
|
Year-term Estimated Cost: ~$524K
|
Note that only 3 machines were needed for ScyllaDB; not much of a challenge in terms of administration. And, as we mentioned earlier, you can offload all your database administration with our new fully managed cloud service, ScyllaDB Cloud. (By the way, ScyllaDB Cloud comes in at 4-6x less expensive than DynamoDB, depending on the plan.)
Final Decision: A Knockout!
- DynamoDB failed to achieve the required SLA multiple times, especially during the population phase.
- DynamoDB has 3x-4x the latency of ScyllaDB, even under ideal conditions
- DynamoDB is 7x more expensive than ScyllaDB
- Dynamo was extremely inefficient in a real-life Zipfian distribution. You’d have to buy 3x your capacity, making it 20x more expensive than ScyllaDB
- ScyllaDB demonstrated up to 20x better throughput in the hot-partition test with better latency numbers
- Last but not least, ScyllaDB provides you freedom of choice with no cloud vendor lock-in (as ScyllaDB can be run on various cloud vendors, or even on-premises).
Still not convinced? Listen to what our users have to say.
If you’d like to try your own comparison, remember that our product is open source. Feel free to download now. We’d love to hear from you if you have any questions about how we stack up or if you’d like to share your own results. And we’ll end with a final reminder that our ScyllaDB Cloud (now available in Early Access) is built on ScyllaDB Enterprise, delivering similar price-performance advantages while eliminating administrative overhead.