要約
Scikit-learnのPassiveAggressiveClassifierを使い、サポートベクトルマシンのミニバッチ学習(もどき)を実装します。確率的勾配降下法やオンライン学習にも応用できるはずです。
注意:ミニバッチ学習もどき(ここ重要)なのでSVMの本質的なミニバッチではありません。
コード:https://gist.github.com/koshian2/5edc72b54748b40c63e85fca5c0152ee
きっかけ
サポートベクトルマシン(SVM)で画像分類をする際に、データの容量が大きすぎてメモリに入り切らない場合どうしよう?とふと思いました。
例えばCIFAR-10データセットの場合、32x32のRGBカラー画像が6万件あります。各座標を64ビット変数に格納すると、32×32×3×60000×8≒1.4GBもメモリが必要になります。ピクセルサイズが例えば96×96になればこの9倍必要なので1、結構真面目にメモリ問題気にする必要があります。
Scikit-learnでは
ニューラルネットワークではミニバッチ2学習や、確率的勾配降下法(SGD)3が、だいたいどんなライブラリ側でも提供されており簡単にできます。Scikit-learnの場合、公式ドキュメントで大きいデータに対する戦略が示されています。
参考:6. Strategies to scale computationally: bigger data
例えばロジスティック回帰はSGDClassifierを使えば、partial_fit()→partial_fit()→…→score()というプロセスでミニバッチができます。ところがSVMの場合このような便利な関数がありません。
StackExchangeを見てたら面白い記述がありました。
参考:Can SVM do stream learning one example at a time?
The streaming setting in machine learning is called "online learning". There is no exact support vector machine in the online setting (since the definition of the objective function is inherently for the batch setting). Probably the most straightforward generalization of the SVM to the online setting are passive-aggressive algorithms.
(この例ではオンライン学習だけど)目的関数の性質上本質的にはできないが、Passive Aggressiveアルゴリズムを使えば簡単に一般化できるかもしれないよ、とのこと。
Passive-Aggressiveアルゴリズム
以下の記事を参考にしました。こちらに記されている論文を読んでみました。ガバガバ解釈なので間違っていたらすみません(数式はちょっと変えています)。
参考:機械学習超入門II ~Gmailの優先トレイでも使っているPA法を30分で習得しよう!~
参考:The Learning Behind Gmail Priority Inbox
この論文はGmailにおいて、ある一定期間内にメールに対してアクション(メールが開かれたか、返信したかなど)が行われたかどうかを推定するモデルについて考えています。つまり教師あり学習の分類問題です。数式で書くと、
$$p=\Pr(a\in A, t\in(T_{min}, T_{max})|x, s) $$
を推定するモデルです。ここで、aはアクション、Aがアクションの集合です。例えば、アクションの種類をメールを開く=1、返信=2とすれば、a=1,a=2,というのと同じで、要するに多クラス分類の問題です。$(T_{min}, T_{max})$がある期間を示します。時間が経つごとに更新していくモデル(オンライン学習)を表すために必要なもので、あまり気にしなくていいです。xは特徴量のベクトル、sはユーザーがメールを見る機会が得られたかどうかを表します。ここで予測誤差eを
\begin{align}
e = \begin{cases}
0 & (\lnot s\lor t\in(T_{min}, T_{max})) \\
1-p & (a\in A) \\
-p & (otherwise)
\end{cases}
\end{align}
とします。つまり、メールを一切みなかった、またはその期間外だったら予測誤差を0とする。それ以外は、アクションを起こしたら1-p、アクションを起こさなかったら-pとカウントするということです。今この問題が多クラス分類であったことを思い出すと、e=0となるような条件を除外して、二値分類に簡略化して考えるとこうなります。
- $e = 1 -p\qquad(a = 1)$
- $e = -p\qquad(a = 0)$
例えばp=0.9と推定して、実際にアクションを起こさなかったら-0.9という高いペナルティがかかりますし、逆にp=0.1と推定して、実際にアクションを起こしたら同じく高いペナルティ0.9がかかかります。
さて、この論文ではpの推定に2つのロジスティック回帰を使っています。1つはGmail全体で共通パラメーターを持つのグローバルなモデル、もう1つはユーザーごとにパラメーターが異なるローカルなモデルです。今、グローバルなモデルの係数を${\bf g}=[g_1, \cdots, g_n]$(nは特徴量の数)、ローカルなモデルの係数を$\theta=[\theta_1, \cdots, \theta_n]$とし、特徴量データの行列を$X = [x^{(1)}, \cdots, x^{(m)}]$(mはデータの数)とすると
$$s^{(i)}=\sum_{j=1}^n(g_jx_j^{(i)} + \theta_jx_j^{(i)})=g^Tx^{(i)}+\theta^Tx^{(i)}$$
となります。この$s^{(i)}$にシグモイド関数をかけると、推定値が出てきます。
$$p^{(i)}=h_{g,\theta}(x^{(i)}) = \frac{1}{1+\exp[-(g^Tx^{(i)}+\theta^Tx^{(i)})]}$$
ここで、$p^{(i)}$より$e^{(i)}$が計算できますが、これに基づいてローカルなモデルの係数θの値のみアップデートします(グローバルなモデルはアップデートしない)。アップデートの仕方は、
$$\theta_j := \theta_j + \sum_{i=1}^{m_{batch}}x_j^{(i)}\frac{{\rm sgn}(e^{(i)})\max(|e^{(i)}|-\epsilon, 0)}{||x^{(i)}||^2 + \frac{1}{2C}}$$
とします。Σは論文に記されているものではなく、複数サンプルを同時にアップデートする用に、自分が勝手につけたしたもので和が正しいのか平均が正しいのかよくわかりません(Scikit-learnの組み込み使うので気にしなくてもどうにかなります)。論文では$m_{batch}=1$であったため、Σがあってもなくても同じです。ミニバッチでアップデートする場合はインデックスをスライドさせていきます。ちなみにsgn(x)は符号関数です。sgn(-3)=-1、sgn(0)=0, sgn(2)=1, …となります。
ここではεとCの2つのハイパーパラメーターがあります。論文によると、Cは正則化のハイパーパラメーターでアップデートのAggressiveness(積極性)を表します。SVMで使われる正則化のパラメーターCと同じと考えて良いでしょう。一方で、εは誤差関数のPassiveness(消極性)を表すハイパーパラメーターです。SVMのマージンとほぼ同じ発想です。このmaxを使った誤差関数(Hinge誤差)がSVMでも使われているので、Passive AggressiveアルゴリズムをSVMにスライドさせるのはそこまで違和感がないように思えます。
実際、一般的なコスト関数を見てみます。まずはロジスティック回帰。ロジスティック回帰はCの逆数であるλを正則化の項として使うことが多いです。
$$J(\theta)=\frac{1}{m}\bigl[\sum_{i=1}^my^{(i)}(-\log h_\theta(x^{(i)})) + (1-y^{(i)})(1-\log h_\theta(x^{(i)})) \bigr] + \frac{1}{2Cm}\sum_{j=1}^n\theta_j^2$$
一方で一般的なSVMのコスト関数は次のようになります。
\begin{align}
J(\theta)=C\bigl[\sum_{i=1}^my^{(i)}cost_1(\theta^Tx^{(i)}) + (1-y^{(i)})cost_0(\theta^Tx^{(i)}) \bigr] + \frac{1}{2}\sum_{j=1}^n\theta_j^2 \\
cost_0(z)=\max(z+1, 0), cost_1(z)=\max(-(z-1), 0)
\end{align}
ただし次の条件を満たします。
$$z=\theta^Tx\geq1\quad(y=1),\qquad z=\theta^Tx\leq-1\quad(y=0)$$
この誤差関数のmaxはHinge関数ですし、実際グラフを書いてみるとロジスティック回帰の-log(…)の関数とよく似ています。なので、だいぶ乱暴な展開ですが、Passive Aggressiveアルゴリズムをサポートベクトルマシンのミニバッチやオンライン学習の代用として使うことはできそうです。実際にプログラムで試してみると結構うまくいきます。後ほど確認していきます。
ちなみにカーネルありの場合はどうなの?と思うかもしれませんが、実はRBF(ガウシアン)カーネルの場合うまくいきません。少し考えてみたので、最後におまけの項目として書いたのでよろしければどうぞ。
バッチ学習の場合
カーネルなし
Scikit-learnのSVCを使って手書き数字の画像を分類します。データはMNIST Originalではなく、sklearnl.datasets.load_digits()にある軽量版MNISTです。これは処理時間短縮のためです。
import numpy as np
from sklearn.datasets import load_digits
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.multiclass import OneVsRestClassifier
import time
# データ読み込み
digits = load_digits()
# 255で割る
original_data = digits["data"] / 255
# ノルムが1になるように標準化
original_data = original_data / np.linalg.norm(original_data, ord=2, axis=1)[:, np.newaxis]
# 訓練-テストの分割
X, Xtest, y, ytest = train_test_split(original_data, digits['target'], test_size=0.2, random_state=114514)
# 通常のSVC
start = time.time()
svc = SVC(kernel="linear")
svc.fit(X, y)
print("Elapsed time(s) :", time.time() - start)
print("Train accuracy :", svc.score(X, y))
print("Test accuracy :", svc.score(Xtest, ytest))
print(svc.intercept_.shape)
print(svc.coef_.shape)
Elapsed time(s) : 0.05200672149658203
Train accuracy : 0.9839944328462074
Test accuracy : 0.9777777777777777
(45,)
(45, 64)
これでもかなりいい感じに。ただし、coefやinterceptの次元に注意してください。SVCではdecision_function_shapeの引数がデフォルトで"ovr"(One vs Rest)なのですが、事実上One vs oneの次元となります。ovrの場合はcoefの次元は(10, 64)となりますが(64は8×8の画像のピクセル数です)、ovoの場合は(クラス数)*(クラス数-1)/2つまり、この場合はクラス数が10あるので(45, 64)となります。この理由がよくわからなかったのですが、SklearnのLinearSVCのドキュメントに書いてありました。
Furthermore SVC multi-class mode is implemented using one vs one scheme while LinearSVC uses one vs the rest. It is possible to implement one vs the rest with SVC by using the sklearn.multiclass.OneVsRestClassifier wrapper. Finally SVC can fit dense data without memory copy if the input is C-contiguous. Sparse data will still incur memory copy though.
参考:http://scikit-learn.org/stable/modules/generated/sklearn.svm.LinearSVC.html
つまり、SVCでの多クラス分類はone vs oneとして行うから、one vs restをやりたければLinearSVCを使うか、SVCをOneVsRestClassifierでラップして使いなさいとのこと。実際、SVCをLinearSVCで置き換えると次のようになります。
svc = LinearSVC()
Elapsed time(s) : 0.031504154205322266
Train accuracy : 0.9770354906054279
Test accuracy : 0.9638888888888889
(10,)
(10, 64)
こちらは期待通りになりました。ちなみにOneVsRestClassifierでラップする場合も同様になります。
svc = OneVsRestClassifier(SVC(kernel="linear"))
Elapsed time(s) : 0.16802144050598145
Train accuracy : 0.9596381350034795
Test accuracy : 0.9583333333333334
(10, 1)
(10, 64)
LinearSVCとOneVsRestClassiferでラップする場合の違いは速さです。おそらくですが、ラップした場合はone vs oneで計算してからone vs restになおしているのに対して、LinearSVCの場合は最初からone vs oneで計算しているはずです。load_digitsではなく、MNIST Originalを使うと露骨に差が出ます(LinearSVCが10秒で答え出すのに対して、SVCをラップするとカーネル抜いても30分経っても答えが出ない)。
カーネルありの場合
load_digits→SVC+OneVsRestClassifierでRBFカーネルを用いた場合の精度も見てみます。
svc = OneVsRestClassifier(SVC(kernel="rbf"))
svc.fit(X, y)
print("Elapsed time(s) :", time.time() - start)
print("Train accuracy :", svc.score(X, y))
print("Test accuracy :", svc.score(Xtest, ytest))
print(svc.intercept_.shape)
kernel="rbf"の場合、coefは出ないのでinterceptの次元だけ表示しています。
Elapsed time(s) : 0.40955209732055664
Train accuracy : 0.9109255393180237
Test accuracy : 0.925
(10, 1)
RBFカーネルを入れた場合、カーネルなしの場合と比べて精度が落ちてしまいました。これはデータが画像だからということが大きいと思います。最後にあるおまけのところでも触れます。
とりあえず手書き数字の場合、RBFカーネルは使わなくても良さそうです。
MNIST Original+カーネルなしの場合
load_digits()が軽量版MNISTであったのに対して、本来のMNIST Originalでもやってみます。違いは以下の通りです。
- load_digits():サンプル数1797、8×8=64pixelのグレースケール。データの次元数は(1797, 64)
- MNIST Original:サンプル数7万、28×28=784pixelのグレースケール。データの次元数は(70000, 784)
MNIST Originalのほうが計算コストが高いことが予想できます。コードは以下の通りです(ほとんど変わらないので中端折ります)。
import numpy as np
from sklearn.datasets import fetch_mldata
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC, LinearSVC
from sklearn.multiclass import OneVsRestClassifier
import time
# データ読み込み
digits = fetch_mldata("MNIST original")
## 略 ##
svc = LinearSVC()
svc.fit(X, y)
print("Elapsed time(s) :", time.time() - start)
print("Train accuracy :", svc.score(X, y))
print("Test accuracy :", svc.score(Xtest, ytest))
print(svc.intercept_.shape)
print(svc.coef_.shape)
10秒弱で出てきます。おおよそ9割程度です。ハイパーパラメーターの調整すればもう少し良くなりますが今回はやりません。
Elapsed time(s) : 9.298680782318115
Train accuracy : 0.9240892857142857
Test accuracy : 0.9149285714285714
(10,)
(10, 784)
PassiveAggressiveClassifierでミニバッチ学習もどき
MNIST Originalでの実践例です。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_mldata
from sklearn.model_selection import train_test_split
from sklearn.linear_model import PassiveAggressiveClassifier
from sklearn.decomposition import PCA
# データ読み込み
mnist = fetch_mldata('MNIST original')
# 255で割る
original_data = mnist["data"] / 255
# ノルムが1になるように標準化
original_data = original_data / np.linalg.norm(original_data, ord=2, axis=1)[:, np.newaxis]
# 訓練-テストの分割
X, Xtest, y, ytest = train_test_split(original_data, mnist['target'], test_size=0.2, random_state=114514)
pac = PassiveAggressiveClassifier(C=1, shuffle=False)
# 反復回数
iter_count = 5
# 反復ごとの精度
train_accuracies = np.zeros(iter_count)
# ミニバッチのサイズ
minibatch_size = 32
# ミニバッチの回数
n_minibatch = np.ceil(len(y)/32).astype(int)
# ミニバッチごとの精度
minibatch_accuracies = np.zeros(iter_count * n_minibatch)
# ミニバッチごとの係数(プロット用に主成分分析で2次元にする)
minibatch_coefs = np.zeros((minibatch_accuracies.shape[0], 2))
# プロット用の主成分分析
pca_decomp = PCA(2)
# シャッフルする際の訓練データのインデックス
train_indices = np.arange(len(y))
np.random.seed(114514)
for k in range(iter_count):
# インデックスのシャッフル
np.random.shuffle(train_indices)
for i in range(n_minibatch):
# 取り出すインデックス
start_idx = i * 32
end_idx = min((i + 1)*32, len(y))
minibatch_indices = train_indices[start_idx:end_idx]
X_minibatch, y_minibatch = X[minibatch_indices, :], y[minibatch_indices]
# ミニバッチの適用
pac.partial_fit(X_minibatch, y_minibatch, classes=np.arange(10))
# ミニバッチの訓練データに対する精度
minibatch_score = pac.score(X_minibatch, y_minibatch)
print(start_idx, "->", end_idx, "Mini-batch Accuracy:", minibatch_score)
minibatch_accuracies[k * n_minibatch + i] = minibatch_score
# 係数
minibatch_coefs[k * n_minibatch + i, :] = pca_decomp.fit_transform(pac.coef_)[0]
# 訓練データに対する精度
train_accuracies[k] = pac.score(X, y)
print("Train Accuracy:", pac.score(X, y))
print("Test Acuuracy:", pac.score(Xtest, ytest))
print(pac.coef_.shape)
print(pac.intercept_.shape)
plt.plot(np.arange(iter_count)+1, train_accuracies, marker="o")
plt.xlabel("Total iteration")
plt.ylabel("Accuracy")
plt.show()
plt.plot(np.arange(iter_count * n_minibatch)+1, minibatch_accuracies)
plt.xlabel("Minibatch iteration")
plt.ylabel("Accuracy")
plt.show()
plt.plot(minibatch_coefs[:, 0], minibatch_coefs[:, 1], linewidth=0.5)
plt.show()
PassiveAgggressiveClassifierのハイパーパラメーターは正則化のCはありますが、εはどこで設定できない?インデックス反復のたびにをシャッフルして、サンプルをランダムに読み込ませるようにしています。訓練データを5回反復させました。
ミニバッチの中でやっているのはこういうことです。最初に訓練データのインデックスをシャッフルします。そして、シャッフルしたインデックスからミニバッチのサイズだけ取り出します。次に取り出したインデックスを元に、ミニバッチで使うデータ(X)とラベル(y)を取得し、分類器にpartial_fit()させます。これを訓練データの最後まで繰り返します。訓練データ全体で何回か反復してもいいかもしれません(この例では5回反復しています)。
ここではやりませんが、より実践的にはハイパーパラメーターのCを調整します。今訓練データとテストデータの精度の差がほとんどないので、
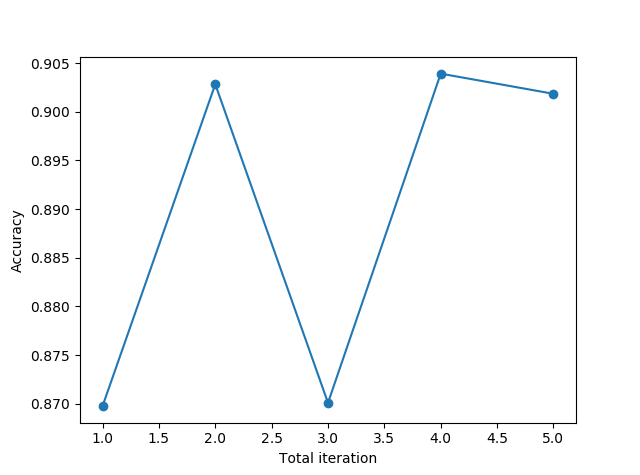
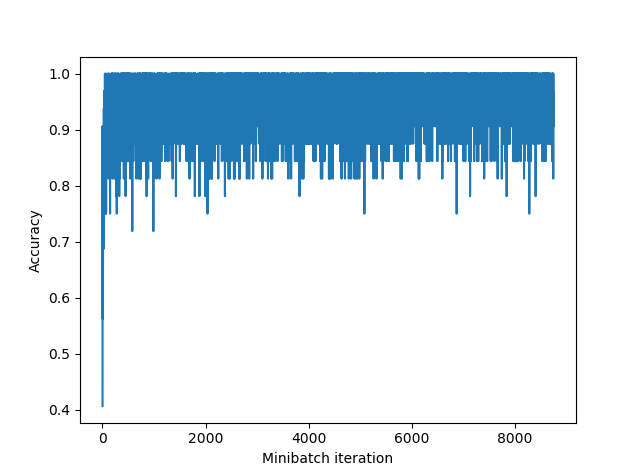
Total Iterationが訓練データ全体に対する精度を表すのに対して、Minibatch iterationがミニバッチでの訓練データのサブセットに対する精度を表します。
Train Accuracy: 0.9018392857142857
Test Acuuracy: 0.892
(10, 784)
(10,)
バッチ学習での精度が0.91~92だったのに対して、PACを使った場合でも0.9前後に収束してますね。いい感じにミニバッチもどきが実装できました!
途中主成分分析を使っていますが、係数のアップデートの途中経過をプロットする用です。784次元の係数を2次元に投射してプロットしたものがこちら。
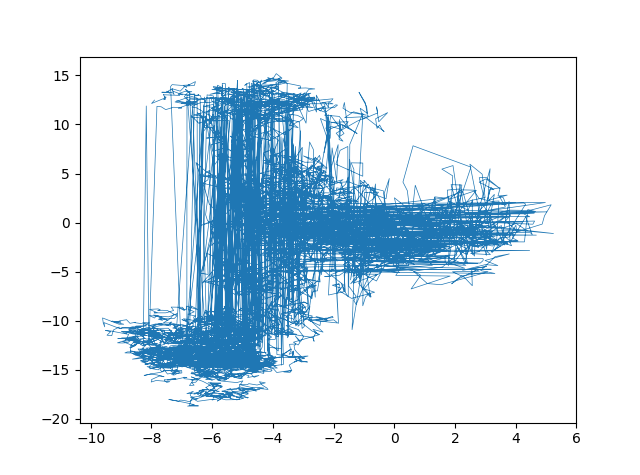
ミニバッチごとにこのように係数が変動しています。主成分分析は可視化以外の目的がないので切って構いません(重いだけなので)。Cの値を変えるとこのステップの幅が変わります。
この方法の何がうれしいの?
このサンプルだとあまり有り難みが実感できないかもしれませんが、冒頭に記したようにメモリ問題が解決できます。
MNISTではデータを全てメモリに展開することは可能でしたが(それでもメモリ1GB近く使います)、もっと大きなデータを使用する際にとても便利です。例えば、訓練データの1つがNumpy配列で1MB、10MBするようなケースは、訓練データ全てをオンメモリにできません。
どうするかというと次のようにするとよいでしょう。以下のアルゴリズムはどっかから持ってきたものではなくオレオレ妄想なので、適当にアレンジしてください。
- 事前処理で訓練データを、前処理込みでNumpy配列の「チャンク」に格納しておく。例えばミニバッチのサイズが32だとしたら、1チャンクを8サンプルとする。チャンク単位でファイルに保存しておく4。
- 反復ごとにチャンクの配列をシャッフルし、1チャンク8サンプル、1ミニバッチ32サンプルだったら、ミニバッチごとにシャッフルしたチャンクを4個ずつメモリに読み込んでアップデートする。使ったチャンクはメモリから解法する。シャッフルするのはファイルのパスなので、メモリ使用量がほとんどかからない。
このチャンクはSSDに保存しておくといいと思います。これだったら係数がメモリに載せきれれば、訓練データは云100GBぐらい普通にいけるので。
あわせてSGDClassifierとの違いも少し書いておきます。カーネルなしのSVMがロジスティック回帰とあまり変わらないのと同様に、PassiveAggressiveClassifierとSGDClassifierがやっていることというのは実はそこまで変わりません。一つの大きな違いは、PassiveAggressiveClassifierはεというパラメーターがあるため、ノイズデータに対してある程度の耐性があるということです(引数としてεはありませんが内部ではちゃんと機能している)。MNISTみたいにきれいなデータだとあまり問題にならないかもしれませんが、SGDで訓練していて大きな外れ値のあるデータが入ると、そのタイミングでモデルの性能がガクッと落ちることがあります。その点においてPAのほうがノイズに対するロバスト性はあります。
ただ、Scikit-learnのSGDは学習率の最適化をデフォルトでしてくれるので、収束した結果はもしかするとPAよりもよいかもしれません。もちろんPAのCの値は途中で変更できるので(Cは正則化としての役割もある一方で、ステップの幅を決めているため学習率と似たような側面もあります)、反復ごとにCを減少させていくとよりよい結果に収束するかと思います。極端な例ですが、直前に示したコードでkについてのループ内、iについてのループの外側で、
for k in range(iter_count):
# : : :
pac.C = 1.0 / (k*10+1)
というようなコードを入れると(k*10+1というのは極端過ぎるかもしれませんが)、最終的なテスト精度が0.92とよりよい値になります。SGDの学習率を減衰させていくのが、SGDが最終的に解の周りをうろうろするからということと同様に、PAのCを減らしていくことで似たような効果が生じます。SGDの学習率の値や減衰方法もハイパーパラメーターなので。ただ、PAをミニバッチではなくオンライン学習として扱う側面もあるので(冒頭のGmailの例がそうです)、訓練データの分布の変更に柔軟に対応していくか、解の精度を良くするかはトレードオフであるといえると思います。
RBF(ガウシアンカーネル)の場合うまく行かない(おまけ)
内容難しいのでここはスキップしてもいいです。RBFでは、2つのデータのベクトル$(x^{(i)},x^{(j)})$のカーネル関数を次のように定義します。
$$K(x^{(i)},x^{(j)})=\exp(-\gamma ||x^{(i)}-x^{(j)}||^2) $$
もしXがm×nの行列だったら、カーネルの行列はm×mの行列になります。したがってこのまま最適化を解くと、パラメーターの数が変わってしまいます。なぜなら本来、SVMの係数の次元はデータの数mではなく、特徴量の次元のn(または切片も含めたn+1)でなくてはならないのですから。
そこで、一旦このカーネル行列を媒介とした最適化の係数を$\alpha = (\alpha_1, \cdots,\alpha_m)$とします(具体的な計算は省略しますので興味があったら下の参考資料を見てください)。αはm次元のベクトルとなります。そして次のように計算して、m次元の係数αから、n次元の係数wに変換します。
$$w=\sum_i^m \alpha_iy^{(i)}\phi(x^{(i)}) $$
ここで$\phi(x^{(i)})$はn次元のベクトルで、以下の性質を満たします。
$$K(x^{(i)},x^{(j)})=\phi(x^{(i)})^T\phi(x^{(j)}) $$
今、Kの行列の固有値分解をし、$K=USU^T$とすると、$K=\phi^T\phi$からΦを求めることができるらしい(Φがどういう関数かということはあまり気にしなくてもいいらしい)。
ただし、これができるのはn≦mの場合で、例えばミニバッチのように少ないサンプルで特徴量の次元がそのままという場合には、おそらくうまくいかないはずです。例えば、MNISTのようにn=784の場合は、ミニバッチでm=32,64…と小さい数でやると、戻したときの係数の後ろの方がほとんど0になってしまうのではないかと思われます。
基本的にSVM、特にカーネルを入れた場合はバッチ学習しかできないと思ったほうがよさそうです(自分が調べても出てきませんでしたが、何かあったらぜひ教えてください)。カーネルなしの場合はこのような変数のマッピングがないので、Passive Aggressiveアルゴリズムを使えばミニバッチ学習もどきができます。
この例では画像の分類を想定していますが、画像の分類の場合はあまりRBFカーネルを使うメリットがなさそうな感じはします(事実、上記で調べたようにload_digits()のデータではカーネルなしのほうが精度がいいです)。なぜなら、RBFカーネルが無限次元のカーネルトリックを使っているためです。すごいアバウトに考えるとRBFカーネルは、expのテイラー展開より$x, x^2, x^3, \cdots$と無限次数まで多項式変数を導入しているということになります。でも画像の場合、例えば座標(0, 0)のピクセル値の2乗や3乗ってほとんど意味がないですよね。それだったら画像の解像度を上げるほうがより直接的で有効だと思います。
逆に、例えばIrisデータセットのような、特徴量の次元が少なく、特徴量の値がピクセル値ではないような場合(つまり特徴量どうしに画像のような連続性がない場合)、RBFはとても有効に機能するはずです。
じゃあSVMでミニバッチやオンライン学習したくてRBF使いたいときどうすればいいの?と思うかもしれませんが、ざっと考えて以下の2つでしょう(他にもあるかもしれません)。
- ニューラルネットワークなどミニバッチが簡単にできるアルゴリズムを使う
- カーネルではなく、多項式変数を導入したカーネルなしSVM、またはロジスティック回帰を使う
自分もこの問題半日ぐらい調べてなんとなく理解したぐらいなので、間違っているところがあると思います。詳しくは以下の資料を参照ください。
http://nktmemoja.github.io/uncategorized/2015/06/30/30235719.html
http://people.csail.mit.edu/dsontag/courses/ml12/slides/lecture6.pdf
https://www.slideshare.net/mobile/ShinyaShimizu/ss-11623505
https://en.m.wikipedia.org/wiki/Radial_basis_function_kernel
https://www.csie.ntu.edu.tw/~cjlin/papers/bottou_lin.pdf
-
教師なし学習用のデータなので一概に比較できないが、STL-10データセットは、96×96のカラー画像が10万件。https://cs.stanford.edu/~acoates/stl10 ↩
-
全部の訓練データを一気に食わせるバッチ学習ではなく、訓練データを小分けにして食わせるのがミニバッチ。ディープラーニングでよく使う。 ↩
-
ミニバッチが小分けするのに対して、SGDは1個ずつ食わせる。ここではミニバッチとして説明。 ↩
-
なぜファイル単位ではなく、チャンク単位とするのかというと、1ファイルごとに読んでいくとファイル読み込みの際のオーバーヘッドが凄まじいから。npz形式でもいいしMessagePackとかでもいいかもしれない。データベースから取ってくるのも有効。これだとチャンクとか考えなくてよさそうだけど、同一クライアントでやるとDBがメモリ食いそう。 ↩