現在、AIや機械学習界隈で最も有名なスタンフォード大学のAndrew Ng教授が、「Machine Learning Yearning」というオンライン書籍を執筆中です。2018年4-5月に、そのドラフト版(1-30章)がオンラインで公開中です。この投稿では、いち早く翻訳を進めています。

この本は、機械学習プロジェクトの構築方法を提供します。また、機械学習アルゴリズムを教えるのではなく、機械学習アルゴリズムが機能する方法に焦点を当てています。
本投稿は、23-27章(Bias and Variance)の翻訳になります。少しづつ翻訳していきます。※翻訳違っていたらご指摘ください。
本書籍は、とても読みやすく、かつ各章短めに記載されています。
1~22章までの翻訳
23. Addressing Bias and Variance(バイアスとバリアンスに対処する)
バイアスとバリアンスの問題に対処するための最もシンプルな式は次の通りです。
- もし、回避可能バイアスを高く保持する(high avoidable bias)ならば、モデルのサイズを大きくします(例えば、レイヤ/ニューロンを追加することによって、ニューラルネットワークのサイズを大きくするなど)。
- もしハイバリアンス(high variance)であれば、トレーニングセットにデータを追加します。
もし、ニューラルネットワークのサイズやトレーニングセット量を制限なく増やすことができるならば、多くの学習上の問題は非常にうまくいく可能性があります。
実際には、モデルのサイズを大きくすると、大規模モデルの計算速度は非常に遅いため、結果的に計算上の問題を引き起こします。より多くのトレーニングデータを取得する気力を失うかもしれません。(インターネット上でさえ、有限の猫の写真しかありません!)
モデルアーキテクチャ(例えば、異なるニューラルネットワークモデル)が異なれば、問題となるバイアス/バリアンスの量も異なります。近年のディープラーニングの研究では、多くの革新的なモデルアーキテクチャが開発されています。もし、ニューラルネットワークを使っているなら、学術的な文献がインスピレーションの大きな源泉になる可能性があります。Github上でには、オープンソースの実装が多く公開されています。しかし、新しいアーキテクチャを試した結果は、モデルサイズやデータを拡大した単純な式よりも予測が難しいです。モデルサイズを大きくすることは、一般的にバイアスを減らしますが、バリアンスとオーバーフィットのリスクが増加します。ただし、このオーバーフィット問題はいつも正則化(regularization)を利用しない場合にだけ発生します。もしうまく設計された正則化方法を組み込むと、オーバーフィットのリスク拡大なく、いつも安心してモデルサイズを拡大できます。
L2正則化かドロップアウト(Dropout)を使用し、開発セットで最もよく動作する正則化パラメータを保持するディープラーニングを適用しているとしましょう。モデルサイズを拡大すれば、通常パフォーマンスは同じか改善するか、です。大幅に悪化する可能性は低い。大規模モデルを避ける唯一の理由は、計算コストの増加です。
24. Bias vs. Variance tradeoff(バイアス-バリアンストレードオフの話)
「バイアス-バリアンストレードオフ」について、あなたは聞いたことがあるかもしれません。多くの学習アルゴリズムに加えられる変更のうち、バイアスの誤差(エラー)を減らす代わりに、バリアンスを増やすという犠牲を払うものもあれば、その逆もあります。これは、バイアスとバリアンスの間にトレードオフを作ります。
例えば、モデルサイズを大きくする(ニューラルネットワークのニューロン/ レイヤーの追加、もしくは入力の特徴量を追加)ことは、一般的にバイアスを減らすが、バリアンスを増加させる可能性があります。あるいは、正則化を追加することは、一般的にバイアスを増加させ、バリアンスを減らします。
現代では、しばしば豊富なデータにアクセスし、非常に大きなニューラルネットワークを使うことができます(ディープラーニング)。したがって、トレードオフは少なくなり、バリアンスを犠牲にすることなくバイアスを減らす様々なオプションがあります。その逆もしかりです。
例えば、バリアンスを大幅に増やさずバイアスを減らすために、ニューラルネットワークのサイズを拡大し、正則化方法を調整することができます。トレーニングデータを追加することによって、バイアスに影響を与えずにバリアンスを減らすことができます。もし、あなたのタスクに合ったモデルアーキテクチャを選択したら、バイアスとバリアンスを同時に減らせるかもしれません。そのようなアーキテクチャを選択することは難しいですが。
次のいくつかの章では、バイアスとバリアンスに大勝するための具体的なテクニックについて説明していきます。
25. Techniques for reducing avoidable bias(回避可能なバイアスを減らすテクニック)
あなたの学習アルゴリズムが、回避可能なバイアスにひどく苦しんでいるなら、以下のテクニックを試してみてください。
モデルサイズの拡大(ニューロン/レイヤー数など):このテクニックは、トレーニングセットによりフィットさせるため、バイアスを減らします。もしバリアンスが増えたら、正則化を利用してください。通常はバリアンスの増加を防ぎます。
エラー分析から得た洞察に基づいた入力特徴量の修正:エラー分析では、アルゴリズム内の特定のエラーカテゴリを取り除く特徴量を追加で作成することを促しているとします(これについては、次の章でさらに議論します。)。これらの新しい特徴量はバイアスとバリアンスの両方に役立ちます。理論的には、特徴量を追加することはバリアンスを増加させる可能性があります。これが当てはまる場合には、通常はバリアンスの増加を防ぐ正則化を利用します。
正則化の削減か除外(L2正則化、L1正則化、ドロップアウト):回避可能なバイアスを低減する一方、バリアンスが拡大するでしょう。
モデルアーキテクチャを問題に適した形に修正(ニューラルネットワークのアーキテクチャなど):このテクニックは、バイアスとバリアンスの両方に効きます。
役に立たない1つの方法
- トレーニングデータの追加 :この手法は、バリアンスの問題を手助けします。通常の、バイアスに大きな影響はありません。
26. Error analysis on the training set()
開発/テストセット上でのパフォーマンスに期待する以前に、トレーニングセット上でアルゴリズムは良いパフォーマンスを出す必要があります。
ハイバイアスに対処するための先に述べたテクニックに加えて、時にはトレーニングセット上でエラー分析を行います。これは、「目玉の親父開発セット」上のエラー分析と同様のプロトコルに従います。これは、アルゴリズムのバイアスが高い場合(すなわちトレーニングセットによくフィットしていない場合)に有用です。
例えば、アプリの音声認識システムを構築し、ボランティアによるオーディオクリップのトレーニングセットを収集しているとします。もしあなたのシステムがトレーニングセット上でうまくいかない場合には、トレーニングセットの主要エラーカテゴリを理解するために、アルゴリズムがうまくいっていない最大100件のサンプルを実際に聴いてみることを検討してください。開発セットでのエラー分析と同様に、様々なカテゴリのエラーをカウントできます。
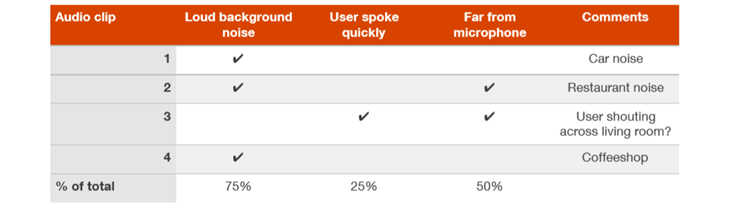
この例では、"background noise"のトレーニングサンプルにより、アルゴリズムが困難な状況を持つことがわかります。このように、"background noise"のトレーニングセットのサンプルにより適したテクニックにフォーカスできます。
学習アルゴリズムとして同じ入力オーディオが与えられたとき、人間がこれらのオーディオクリップを同じように再生できるか再確認できます。もし、単純に誰が何を言ったかわからない背景ノイズがあるならば、アルゴリズムが正しく発話を認識するように期待することは無理かもしれません。後の章では、アルゴリズムと人間のパフォーマンスを比較することの利点について説明します。
27. Techniques for reducing variance(バリアンスを減らすテクニック)
もしあなたのアルゴリズムがハイバリアンスに苦しんでいるなら、以下のテクニックを試してみるとよいでしょう。
トレーニングデータの追加:データ処理のために必要なデータや十分なコンピュータリソースを活用できるのであれば、これはバリアンスに対処するための最もシンプルかつ信頼できる方法です。
正則化の追加(L2正則化、L1正則化、ドロップアウト):このテクニックは、バリアンスを減らしますが、バイアスが増えます。
早期停止を追加(すなわち、開発セットのエラーに基づいて、勾配降下法を早期停止する):この手法は、バリアンスを減らしますは、バイアスが増加します。早期停止は正則化のように動作し、一部の著者はそれを正則化のテクニックとして呼んでいます。
入力特徴量の数/タイプを減らすための特徴量選択:このテクニックはバリアンス問題に役立ちますが、同様にバイアスが増加する可能性があります。特徴量の数を少し減らす(特徴量1,000個 --> 900個)ことで、バイアスに大きな影響を与える可能性は低いです。特徴量の数を大幅に減らす(特徴量1,000個 --> 100個)と、重要な特徴量が含まれていない場合を除き、バイアスに大きな影響が出る可能性があります。現代のディープラーニングでは、データが豊富にある場合における特徴量選択の考え方は変わってきており、私たちは保持するすべての特徴量をアルゴリズムに与え、そのデータに基づいてモデル選択が行われる可能性があります。しかし、もしトレーニングデータが小さいのであれば、特徴量選択は有用である可能性があります。
モデルサイズ(ニューロン/レイヤ数)を小さくする:注意して利用してください。このテクニックは、バイアスを増加させる可能性がありますが、バリアンスを減らす可能性があります。しかしながら、バリアンスへの対処としては、このテクニックはお勧めしません。正則化を追加することは、通常分類器のパフォーマンスが向上します。モデルサイズを減らすことの利点は、計算コストを減らし、モデルのトレーニング速度を高めることです。もし、モデルのトレーニング速度の向上が有益であるならば、モデルサイズを減らすこと検討してください。計算コストに対する懸念がない場合には、代わりに正則化を追加してください。
ここで、バイアスへの対処に関する過去の章からの再掲になりますが、2つの戦術があります。
- エラー分析の洞察に基づく入力特徴量の修正:エラー分析の結果、特定のエラーカテゴリを除去するために、追加の特徴量を作ることがアルゴリズムの手助けになるとします。新しい特徴量はバイアスとバリアンスの両方に有益です。理論的には、特徴量を追加していくことはバリアンスを高める可能性があります。もしこれが当てはまったら、バリアンスの増加を防ぐために正則化を利用します。
- モデルアーキテクチャを問題に適した形に修正(ニューラルネットワークのアーキテクチャなど):このテクニックは、バイアスとバリアンスの両方に効きます。