
(上図は研究開発元のサイトから引用)
PredNet?
https://coxlab.github.io/prednet/
Bill Lotter, Gabriel Kreiman, and David Cox (2016)
動画の未来のフレームを予測する深層学習のモデル。
研究開発元の CoxLab (上記リンク) に色々デモがあるので見てみるとイメージが湧くと思います。
2016年の中盤くらいに盛り上がった話なので、今更感はあるかもしれませんが、
実際に学習させてみてわかったことなどをまとめておきます。
(アルゴリズムやコンセプトの説明というよりは、学習のようすとか環境についての話をメインにします)
学習するまで
コードが公開されている (https://github.com/coxlab/prednet) ため、論文は読まなくてもモデルを学習させることは可能です。
環境について
元のコードをそのまま動かすためには、Python2+Keras1 の環境を用意する必要があります。
今の最新バージョンは Python3+Keras2 ですので、少し古いことに注意が必要です。
Keras2 に移植は試みましたが、学習が失敗するようになってしまったため、Keras1 でやることにしました。
やっていませんが、Python3 への移植は可能だと思います。
データの準備
論文中で主に参照されているのは KITTI による車載カメラの映像 です1。
git clone してきたスクリプトに process_kitti.py があるので、それを走らせると、
- データのダウンロード
- 前処理
- Train/Validation/Test 分割
まで自動でやってくれます。が、これが非常に遅い。私が使用した環境だと、データのダウンロードに丸3日はかかりました。合わせて100Gバイト近くになるデータなのでしょうがないかもしれませんが・・・それでも遅すぎる気はします。
学習
データの準備が終わったら、kitti_train.py を走らせると学習が始まります。
ここでもいくつか留意点があります。
学習時間
これは環境にも依るのでなんとも言い難いですが、私が使用した環境 (GeForce GTX TITAN 6082MiB) だと、1epoch あたりちょうど5分くらいでした。デフォルトの設定だと150epoch学習させるようになっているため、合計で 12 時間ちょっとです。LSTM を組み込んでいるモデルにしてはかなり良心的な学習時間だと思います。
学習の様子
以下が学習曲線になります:
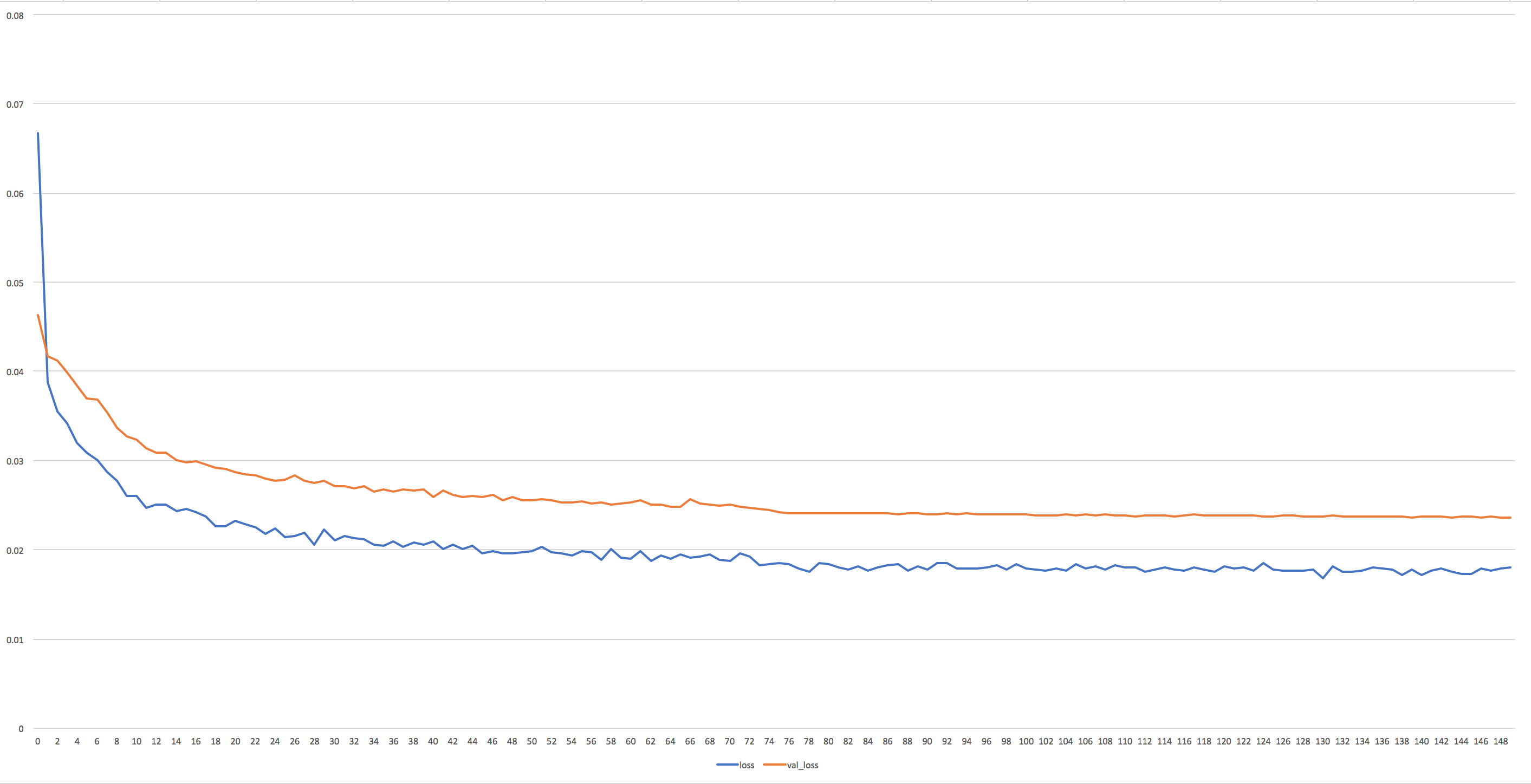
パラメータは十分安定していると言って良いと思われます。
何もいじらなければ epoch=75 のときに学習率が1/10にされますが、そのタイミングでロスがガクッと下がっています。
training loss (青線) は下がりきっていますが、validation loss (橙線) はまだ下がりそうな傾向があるので、もう少し学習させてみても良いかもしれません。
その他に注意したほうがよい点は、学習中に測っている loss (MAE) は、論文中で報告されている MAE とは測り方が違うことです。
論文中では最終的に MAE が 3.13e-3 (=0.00313) になった、と報告されていますが、この MAE は「予測フレームと実フレームのピクセルの誤差」を測ったものです。
一方、学習中に Keras が報告してくる loss も MAE という意味では同じなのですが、こちらは「誤差ユニット E の出力とゼロ行列との誤差」を測ったものです 2。
実際、今回学習したモデルの最終的な誤差 (上のグラフの縦軸) は、training で 1.780e-2 (=0.01780), validation で 2.36e-2 (=0.0236) でした。オーダーがひとつ違います。
予測結果
実際にテストデータにモデルを当てはめたところ、フレームでの MAE (論文での測り方と同じもの) は 3.927e-3 となり、多少及ばないものの、論文で報告されていた精度近くは出ているようです。
結果の画像を以下に載せますが、まず結果画像の見方を説明します。
今回の動画は 10Hz (10fps、つまり1秒には10フレームの画像が含まれる) であり、予測は10フレームぶん、つまり1秒ぶんおこなっています。
10フレームの予測とは言っても、実際には直前のフレームも入力として貰った上で予測をしているため、実質的には1フレーム先の予測と言っても良いでしょう。どの画像からどの画像を予測しているのかを図で書けば次のような感じです。

(モデル内に RNN 構造が存在しているため、実際には今までの入力を「覚えて」その情報も使っていることに注意してください。)
また、本当に数フレーム先の予測をすること (extrapolation, 外挿 と呼ばれています) も論文中で触れられていて (コードにも含まれています)、その場合には次のような図になるでしょう:

最初の数フレームは、RNN に状態を埋め込むために1フレーム前の画像を使ってモデルをウォーミングアップさせます。
その後で、正解画像を一切渡さずに自分の出力を正解だと思って外挿を開始します。
なお、以降に貼る予測結果はすべて外挿ではありませんのでご注意ください。
予測結果は次のとおりです (抜粋):







論文中で報告されている通り、白線や道路の影を正しく予測できています。
車についても、変な動き (自分に対して横に動くようなデータは少ないため学習できない?たとえば5番目の画像は車が目の前を横切っており、予測がなんかおかしなことになっています) ではない限り、結構予測できています。
ハンドルを切る動作 (6番目の画像) もうまく取り扱えていそうです。