書きました https://t.co/m4YhZolDjD
— mooopan (@mooopan) February 20, 2017
ということでChainerの強化学習版ChainerRLが公開されていました。
このところ手を広げすぎていて中々丁寧な仕事ができない中、
30分 x 2日でDouble DQNでライントレーサーできました。ライブラリ便利で助かる!
使用環境
- Windows 10 - 64bit <諦めが悪い心の強さ…!>
- Python 3.6.0 |Anaconda 4.3.0 (64-bit) <プライドより実利!>
- ChainerRL 0.2 < Dependency緩くしてほしい>
- Chainer 1.19 <1.20でTheanoのお世話できてない!会社ではTheano動いたのに。>
- cached_property
- gym (0.7.3)
- gym environment ライントレーサーの環境をOpenAI I/F的にした - Qiita
環境&サンプル リポジトリ
Chachay/Gym_LineFollower: Simple Open AI gym like Environment
GUI tool kitをQt5化しました
ChainerRL
pipで入れようとすると Arcade Learning Environment入れようとしてコケる。
ALEをWindowsに突っ込むところに時間をかけてもいいけど、
Windowsでpongしたいとも思わないので、ショートカット!!
1. GitHubからリポジトリを落とす
2. 同梱のChainerRLフォルダを作業フォルダに移す
以降のexampl2.pyと同じフォルダね
ライントレーサー環境定義
ライントレーサーの環境をOpenAI I/F的にした - Qiitaの環境は、ライントレーサーが受け取る車輪速度を連続値で環境を定義しています。
これを離散値にするため、継承で離散値環境にしなおします。
同時に一つ目センシングを4ステップ分の履歴観測にします。
class SState(object):
def __init__(self, STATE_NUM, DIM):
self.STATE_NUM = STATE_NUM
self.DIM = DIM
self.seq = np.zeros((STATE_NUM, DIM), dtype=np.float32)
def push_s(self, state):
self.seq[1:self.STATE_NUM ] = self.seq[0:self.STATE_NUM -1]
self.seq[0] = state
def reset(self):
self.seq = np.zeros_like(self.seq)
def fill_s(self, state):
for i in range(0, self.STATE_NUM):
self.seq[i] = state
# Define Agent And Environment
class LineTracerEnvDiscrete(LineTracerEnv):
actions = np.array([[0.5, 0.1], [1.0, 1.0], [0.1, 0.5]])
OBSDIM = 4
def __init__(self):
self.action_space_d = spaces.Discrete(self.actions.shape[0])
self.observation_space_d = spaces.Discrete(self.OBSDIM)
self.MyState = SState(self.OBSDIM, 1)
super().__init__()
def _step(self, action):
tempState, tmpReward, tmpDone, tmpInfo = super()._step(self.actions[action])
self.MyState.push_s(tempState)
return self.MyState.seq.flatten(), tmpReward, tmpDone, tmpInfo
def _reset(self):
s = super()._reset()
self.MyState.reset()
return self.MyState.seq.flatten()
env = LineTracerEnvDiscrete()
あとは藤田さん(@mooopann)のクイックスタートからコピペ・コピペ
env.OBSDIM, env.action_space_d.nとenv.action_space_d.sampleだけ若干注意。
q_func = chainerrl.q_functions.FCStateQFunctionWithDiscreteAction(
env.OBSDIM, env.action_space_d.n,
n_hidden_layers=2, n_hidden_channels=50)
optimizer = chainer.optimizers.Adam(eps=1e-2)
optimizer.setup(q_func)
gamma = 0.95
explorer = chainerrl.explorers.ConstantEpsilonGreedy(
epsilon=0.3, random_action_func=env.action_space_d.sample)
replay_buffer = chainerrl.replay_buffer.ReplayBuffer(capacity=10 ** 6)
agent = chainerrl.agents.DoubleDQN(
q_func, optimizer, replay_buffer, gamma, explorer,
replay_start_size=500, update_frequency=1,
target_update_frequency=100)
実行
動く…!
python example2.py
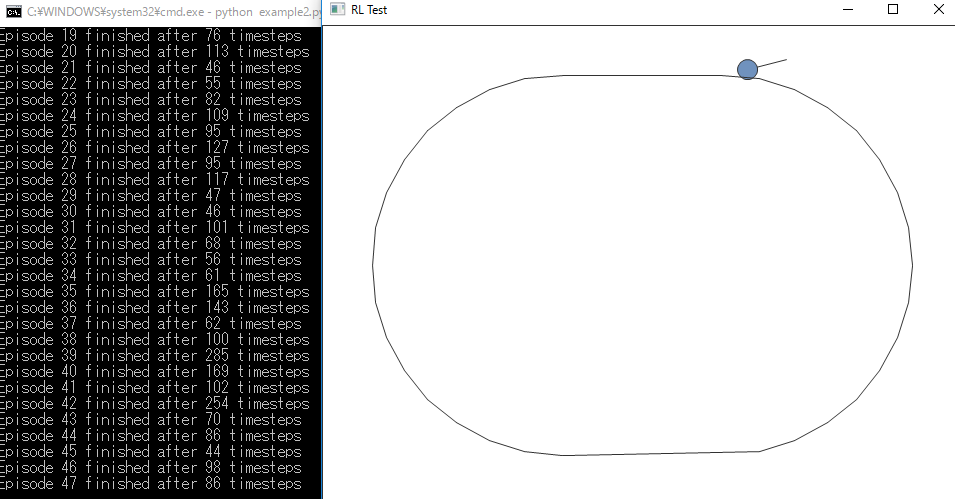
※ 周回路回れるような行動を学習できたかは…試してないっす
そのあたりは過去記事を… ⇒ ライントレーサーをDeep Q Learningで教育する - Chainer - Qiita
感想
初日:正味30分
ChainerRL使おうとしたけど、見本の書き方がhttps://t.co/cDBp9FgwA5ではないところまで理解して終わってしまった。ENV環境を連続値で作っといてなんだけど、離散値に定義しなおした環境への作り直しが必要> https://t.co/x57EkRzQfj
— chachay (@chachay) February 20, 2017
2日目:正味30分
- Envの継承クラス作成
- 動いた
まとめ
- エージェントづくりが捗りまくって素晴らしい
- pipにてWindowsで蹴られないような気づかいはいただきたい
- やっぱり↓はある
連続値を普段入力値として扱っているエンジニアとしては、連続値に対して行動候補(離散化)をエージェントで定義できるようにして、離散・連続値間の間を取り持ってくれると助かる。gymの設計コンセプトから外れるとしても。
— chachay (@chachay) February 20, 2017
スクリプト
Chachay/Gym_LineFollower: Simple Open AI gym like Environment
example2.py参照のこと